 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Decomposition of Graph Neural Networks
Paper and Code
Oct 25, 2024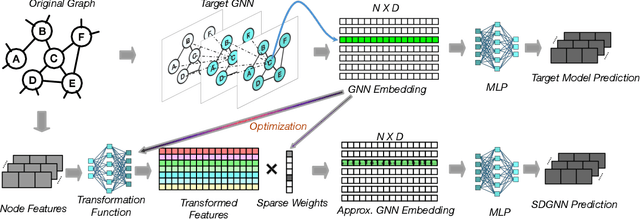
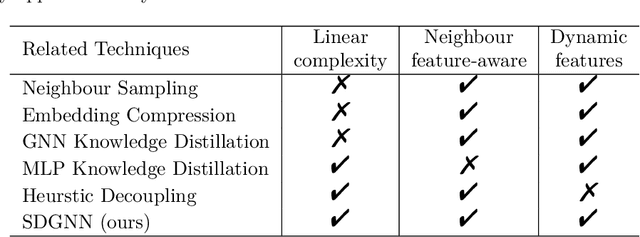
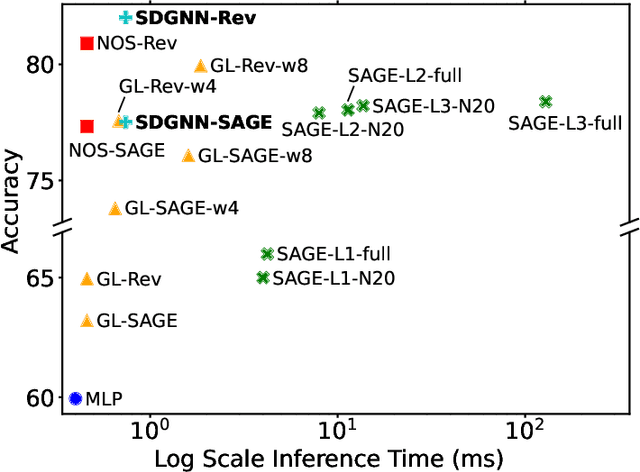

Graph Neural Networks (GNN) exhibit superior performance in graph representation learning, but their inference cost can be high, due to an aggregation operation that can require a memory fetch for a very large number of nodes. This inference cost is the major obstacle to deploying GNN models with \emph{online prediction} to reflect the potentially dynamic node features. To address this, we propose an approach to reduce the number of nodes that are included during aggregation. We achieve this through a sparse decomposition, learning to approximate node representations using a weighted sum of linearly transformed features of a carefully selected subset of nodes within the extended neighbourhood. The approach achieves linear complexity with respect to the average node degree and the number of layers in the graph neural network. We introduce an algorithm to compute the optimal parameters for the sparse decomposition, ensuring an accurate approximation of the original GNN model, and present effective strategies to reduce the training time and improve the learning process. We demonstrate via extensive experiments that our method outperforms other baselines designed for inference speedup, achieving significant accuracy gains with comparable inference times for both node classification and spatio-temporal forecasting tasks.