 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRANITE : a Byzantine-Resilient Dynamic Gossip Learning Framework
Apr 24, 2025Gossip Learning (GL) is a decentralized learning paradigm where users iteratively exchange and aggregate models with a small set of neighboring peers. Recent GL approaches rely on dynamic communication graphs built and maintained using Random Peer Sampling (RPS) protocols. Thanks to graph dynamics, GL can achieve fast convergence even over extremely sparse topologies. However, the robustness of GL over dy- namic graphs to Byzantine (model poisoning) attacks remains unaddressed especially when Byzantine nodes attack the RPS protocol to scale up model poisoning. We address this issue by introducing GRANITE, a framework for robust learning over sparse, dynamic graphs in the presence of a fraction of Byzantine nodes. GRANITE relies on two key components (i) a History-aware Byzantine-resilient Peer Sampling protocol (HaPS), which tracks previously encountered identifiers to reduce adversarial influence over time, and (ii) an Adaptive Probabilistic Threshold (APT), which leverages an estimate of Byzantine presence to set aggregation thresholds with formal guarantees. Empirical results confirm that GRANITE maintains convergence with up to 30% Byzantine nodes, improves learning speed via adaptive filtering of poisoned models and obtains these results in up to 9 times sparser graphs than dictated by current theory.
Secure Federated Graph-Filtering for Recommender Systems
Jan 28, 2025Recommender systems often rely on graph-based filters, such as normalized item-item adjacency matrices and low-pass filters. While effective, the centralized computation of these components raises concerns about privacy, security, and the ethical use of user data. This work proposes two decentralized frameworks for securely computing these critical graph components without centralizing sensitive information. The first approach leverages lightweight Multi-Party Computation and distributed singular vector computations to privately compute key graph filters. The second extends this framework by incorporating low-rank approximations, enabling a trade-off between communication efficiency and predictive performance. Empirical evaluations on benchmark datasets demonstrate that the proposed methods achieve comparable accuracy to centralized state-of-the-art systems while ensuring data confidentiality and maintaining low communication costs. Our results highlight the potential for privacy-preserving decentralized architectures to bridge the gap between utility and user data protection in modern recommender systems.
Scrutinizing the Vulnerability of Decentralized Learning to Membership Inference Attacks
Dec 17, 2024



The primary promise of decentralized learning is to allow users to engage in the training of machine learning models in a collaborative manner while keeping their data on their premises and without relying on any central entity. However, this paradigm necessitates the exchange of model parameters or gradients between peers. Such exchanges can be exploited to infer sensitive information about training data, which is achieved through privacy attacks (e.g Membership Inference Attacks -- MIA). In order to devise effective defense mechanisms, it is important to understand the factors that increase/reduce the vulnerability of a given decentralized learning architecture to MIA. In this study, we extensively explore the vulnerability to MIA of various decentralized learning architectures by varying the graph structure (e.g number of neighbors), the graph dynamics, and the aggregation strategy, across diverse datasets and data distributions. Our key finding, which to the best of our knowledge we are the first to report, is that the vulnerability to MIA is heavily correlated to (i) the local model mixing strategy performed by each node upon reception of models from neighboring nodes and (ii) the global mixing properties of the communication graph. We illustrate these results experimentally using four datasets and by theoretically analyzing the mixing properties of various decentralized architectures. Our paper draws a set of lessons learned for devising decentralized learning systems that reduce by design the vulnerability to MIA.
Differentially private and decentralized randomized power method
Nov 04, 2024
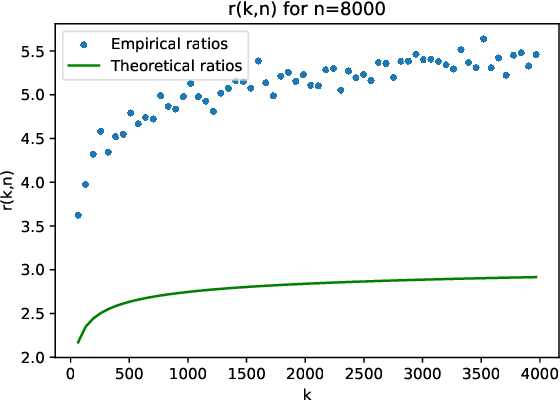
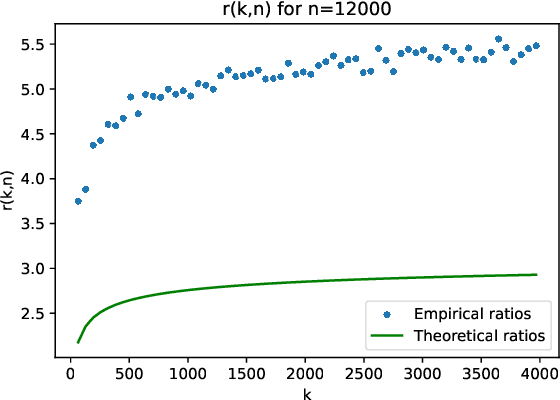

The randomized power method has gained significant interest due to its simplicity and efficient handling of large-scale spectral analysis and recommendation tasks. As modern datasets contain sensitive private information, we need to give formal guarantees on the possible privacy leaks caused by this method. This paper focuses on enhancing privacy preserving variants of the method. We propose a strategy to reduce the variance of the noise introduced to achieve Differential Privacy (DP). We also adapt the method to a decentralized framework with a low computational and communication overhead, while preserving the accuracy. We leverage Secure Aggregation (a form of Multi-Party Computation) to allow the algorithm to perform computations using data distributed among multiple users or devices, without revealing individual data. We show that it is possible to use a noise scale in the decentralized setting that is similar to the one in the centralized setting. We improve upon existing convergence bounds for both the centralized and decentralized versions. The proposed method is especially relevant for decentralized applications such as distributed recommender systems, where privacy concerns are paramount.
Community Detection Attack against Collaborative Learning-based Recommender Systems
Jun 15, 2023



Collaborative-learning based recommender systems emerged following the success of collaborative learning techniques such as Federated Learning (FL) and Gossip Learning (GL). In these systems, users participate in the training of a recommender system while keeping their history of consumed items on their devices. While these solutions seemed appealing for preserving the privacy of the participants at a first glance, recent studies have shown that collaborative learning can be vulnerable to a variety of privacy attacks. In this paper we propose a novel privacy attack called Community Detection Attack (CDA), which allows an adversary to discover the members of a community based on a set of items of her choice (e.g., discovering users interested in LGBT content). Through experiments on three real recommendation datasets and by using two state-of-the-art recommendation models, we assess the sensitivity of an FL-based recommender system as well as two flavors of Gossip Learning-based recommender systems to CDA. Results show that on all models and all datasets, the FL setting is more vulnerable to CDA than Gossip settings. We further evaluated two off-the-shelf mitigation strategies, namely differential privacy (DP) and a share less policy, which consists in sharing a subset of model parameters. Results show a better privacy-utility trade-off for the share less policy compared to DP especially in the Gossip setting.
Differentially Private Speaker Anonymization
Feb 23, 2022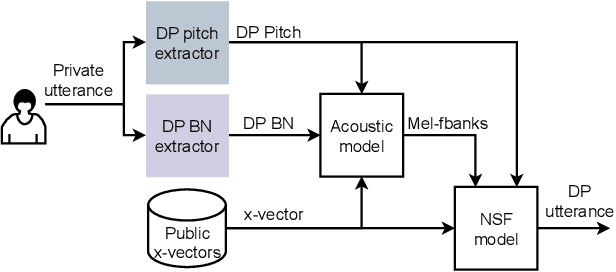
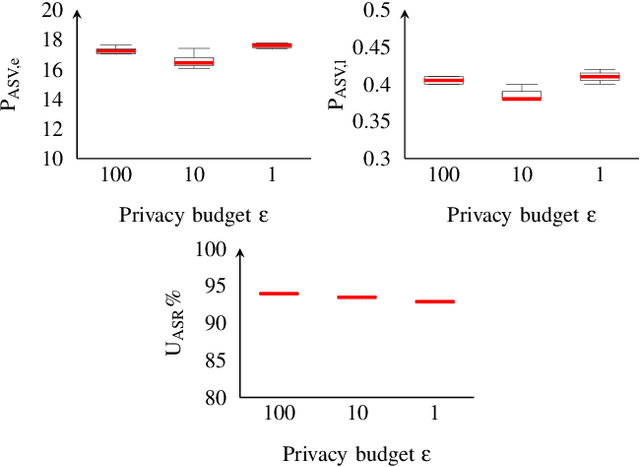
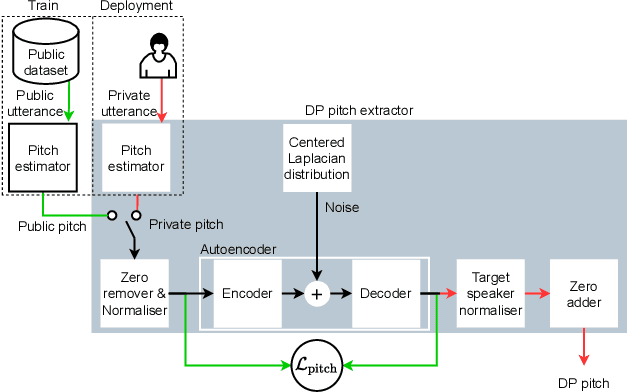
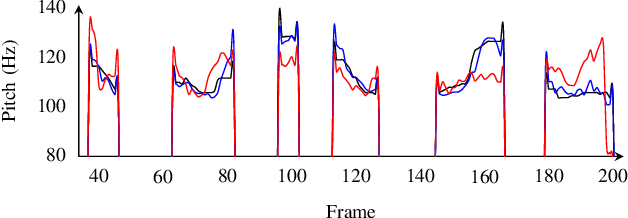
Sharing real-world speech utterances is key to the training and deployment of voice-based services. However, it also raises privacy risks as speech contains a wealth of personal data. Speaker anonymization aims to remove speaker information from a speech utterance while leaving its linguistic and prosodic attributes intact. State-of-the-art techniques operate by disentangling the speaker information (represented via a speaker embedding) from these attributes and re-synthesizing speech based on the speaker embedding of another speaker. Prior research in the privacy community has shown that anonymization often provides brittle privacy protection, even less so any provable guarantee. In this work, we show that disentanglement is indeed not perfect: linguistic and prosodic attributes still contain speaker information. We remove speaker information from these attributes by introducing differentially private feature extractors based on an autoencoder and an automatic speech recognizer, respectively, trained using noise layers. We plug these extractors in the state-of-the-art anonymization pipeline and generate, for the first time, differentially private utterances with a provable upper bound on the speaker information they contain. We evaluate empirically the privacy and utility resulting from our differentially private speaker anonymization approach on the LibriSpeech data set. Experimental results show that the generated utterances retain very high utility for automatic speech recognition training and inference, while being much better protected against strong adversaries who leverage the full knowledge of the anonymization process to try to infer the speaker identity.
The VoicePrivacy 2020 Challenge: Results and findings
Sep 01, 2021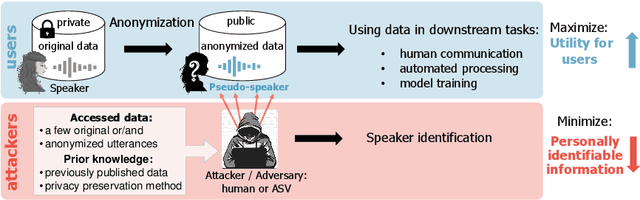
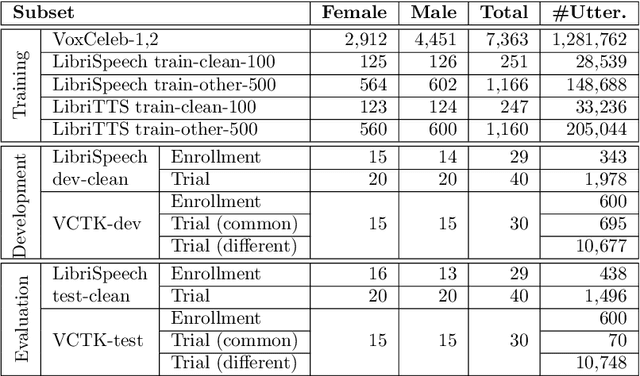
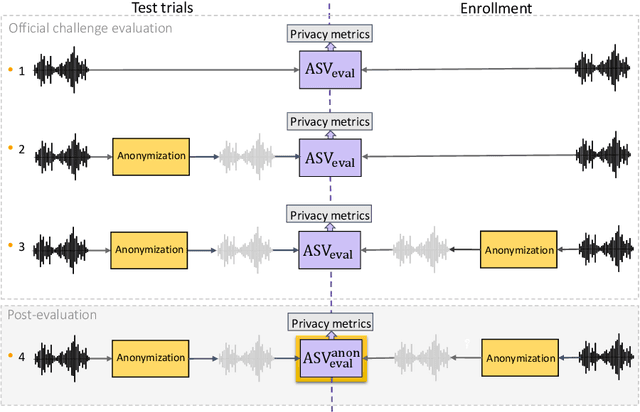
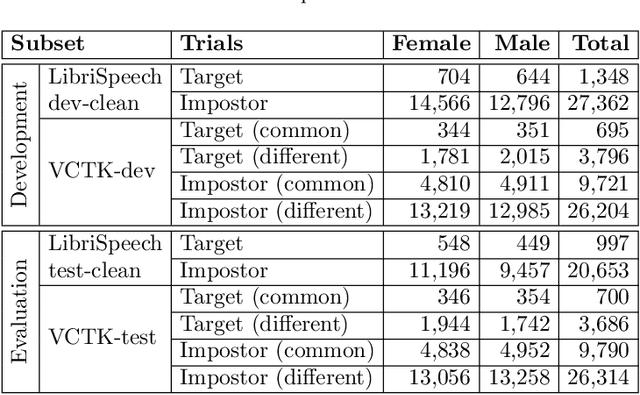
This paper presents the results and analyses stemming from the first VoicePrivacy 2020 Challenge which focuses on developing anonymization solutions for speech technology. We provide a systematic overview of the challenge design with an analysis of submitted systems and evaluation results. In particular, we describe the voice anonymization task and datasets used for system development and evaluation. Also, we present different attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and provide a summary description of the anonymization systems developed by the challenge participants. We report objective and subjective evaluation results for baseline and submitted systems. In addition, we present experimental results for alternative privacy metrics and attack models developed as a part of the post-evaluation analysis. Finally, we summarize our insights and observations that will influence the design of the next VoicePrivacy challenge edition and some directions for future voice anonymization research.
Design Choices for X-vector Based Speaker Anonymization
May 18, 2020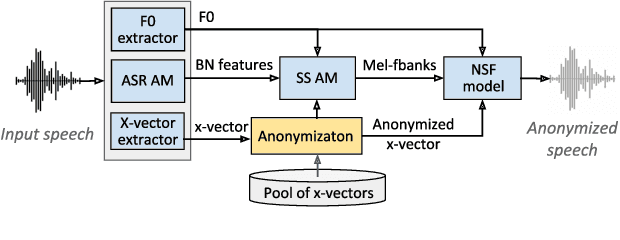
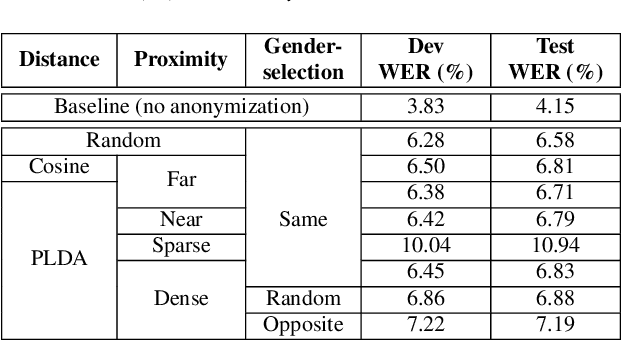
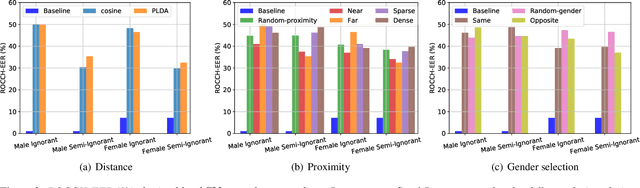
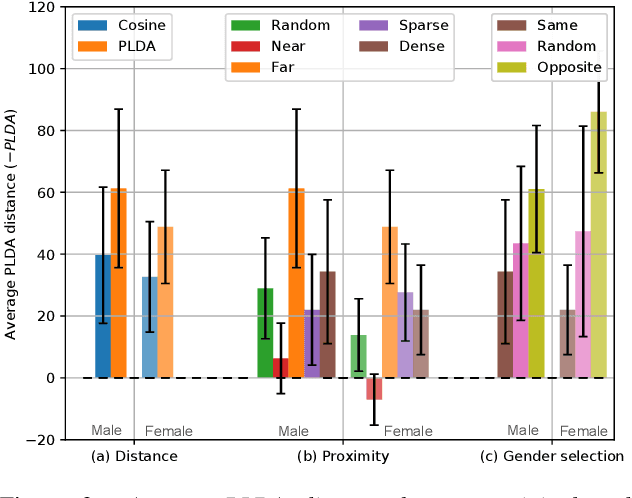
The recently proposed x-vector based anonymization scheme converts any input voice into that of a random pseudo-speaker. In this paper, we present a flexible pseudo-speaker selection technique as a baseline for the first VoicePrivacy Challenge. We explore several design choices for the distance metric between speakers, the region of x-vector space where the pseudo-speaker is picked, and gender selection. To assess the strength of anonymization achieved, we consider attackers using an x-vector based speaker verification system who may use original or anonymized speech for enrollment, depending on their knowledge of the anonymization scheme. The Equal Error Rate (EER) achieved by the attackers and the decoding Word Error Rate (WER) over anonymized data are reported as the measures of privacy and utility. Experiments are performed using datasets derived from LibriSpeech to find the optimal combination of design choices in terms of privacy and utility.