 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe distribution of calibrated likelihood functions on the probability-likelihood Aitchison simplex
Sep 03, 2025



While calibration of probabilistic predictions has been widely studied, this paper rather addresses calibration of likelihood functions. This has been discussed, especially in biometrics, in cases with only two exhaustive and mutually exclusive hypotheses (classes) where likelihood functions can be written as log-likelihood-ratios (LLRs). After defining calibration for LLRs and its connection with the concept of weight-of-evidence, we present the idempotence property and its associated constraint on the distribution of the LLRs. Although these results have been known for decades, they have been limited to the binary case. Here, we extend them to cases with more than two hypotheses by using the Aitchison geometry of the simplex, which allows us to recover, in a vector form, the additive form of the Bayes' rule; extending therefore the LLR and the weight-of-evidence to any number of hypotheses. Especially, we extend the definition of calibration, the idempotence, and the constraint on the distribution of likelihood functions to this multiple hypotheses and multiclass counterpart of the LLR: the isometric-log-ratio transformed likelihood function. This work is mainly conceptual, but we still provide one application to machine learning by presenting a non-linear discriminant analysis where the discriminant components form a calibrated likelihood function over the classes, improving therefore the interpretability and the reliability of the method.
Explaining a probabilistic prediction on the simplex with Shapley compositions
Aug 02, 2024Originating in game theory, Shapley values are widely used for explaining a machine learning model's prediction by quantifying the contribution of each feature's value to the prediction. This requires a scalar prediction as in binary classification, whereas a multiclass probabilistic prediction is a discrete probability distribution, living on a multidimensional simplex. In such a multiclass setting the Shapley values are typically computed separately on each class in a one-vs-rest manner, ignoring the compositional nature of the output distribution. In this paper, we introduce Shapley compositions as a well-founded way to properly explain a multiclass probabilistic prediction, using the Aitchison geometry from compositional data analysis. We prove that the Shapley composition is the unique quantity satisfying linearity, symmetry and efficiency on the Aitchison simplex, extending the corresponding axiomatic properties of the standard Shapley value. We demonstrate this proper multiclass treatment in a range of scenarios.
Revisiting and Improving Scoring Fusion for Spoofing-aware Speaker Verification Using Compositional Data Analysis
Jun 16, 2024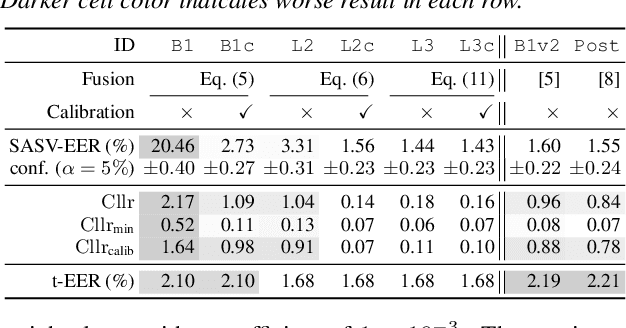
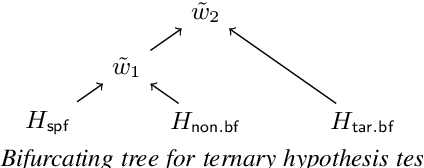
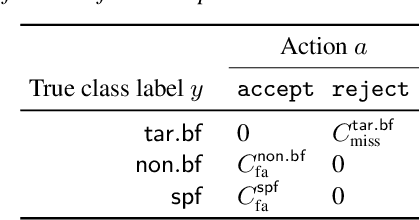
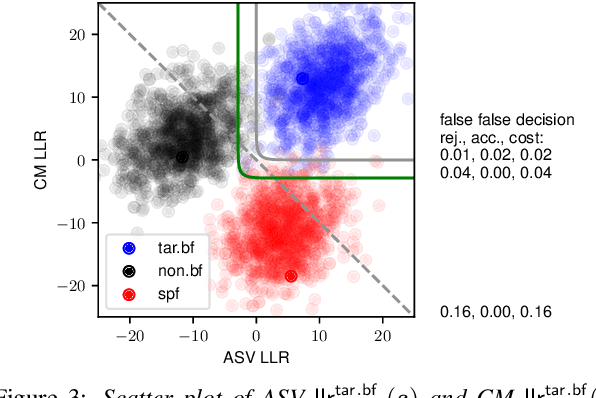
Fusing outputs from automatic speaker verification (ASV) and spoofing countermeasure (CM) is expected to make an integrated system robust to zero-effort imposters and synthesized spoofing attacks. Many score-level fusion methods have been proposed, but many remain heuristic. This paper revisits score-level fusion using tools from decision theory and presents three main findings. First, fusion by summing the ASV and CM scores can be interpreted on the basis of compositional data analysis, and score calibration before fusion is essential. Second, the interpretation leads to an improved fusion method that linearly combines the log-likelihood ratios of ASV and CM. However, as the third finding reveals, this linear combination is inferior to a non-linear one in making optimal decisions. The outcomes of these findings, namely, the score calibration before fusion, improved linear fusion, and better non-linear fusion, were found to be effective on the SASV challenge database.
Hiding speaker's sex in speech using zero-evidence speaker representation in an analysis/synthesis pipeline
Nov 29, 2022The use of modern vocoders in an analysis/synthesis pipeline allows us to investigate high-quality voice conversion that can be used for privacy purposes. Here, we propose to transform the speaker embedding and the pitch in order to hide the sex of the speaker. ECAPA-TDNN-based speaker representation fed into a HiFiGAN vocoder is protected using a neural-discriminant analysis approach, which is consistent with the zero-evidence concept of privacy. This approach significantly reduces the information in speech related to the speaker's sex while preserving speech content and some consistency in the resulting protected voices.
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022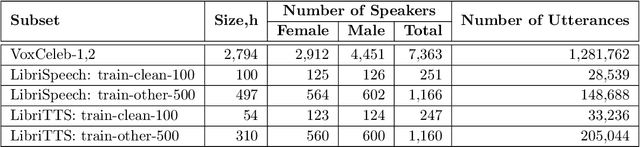
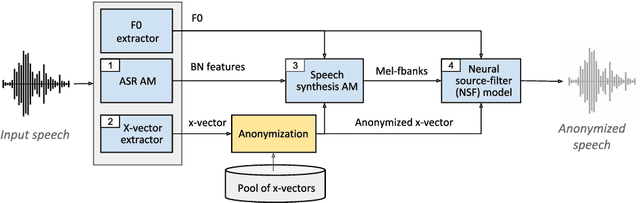
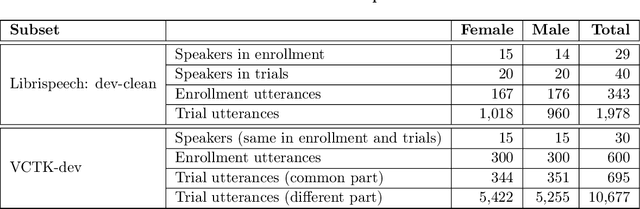
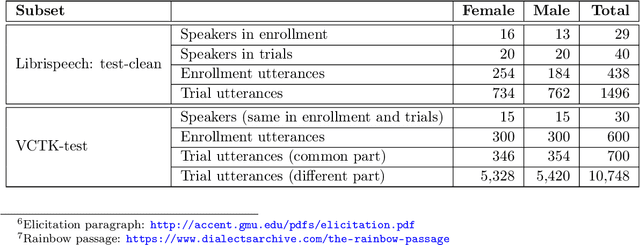
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
A bridge between features and evidence for binary attribute-driven perfect privacy
Oct 12, 2021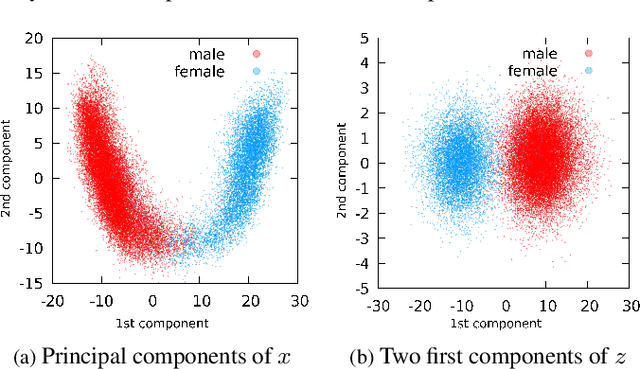
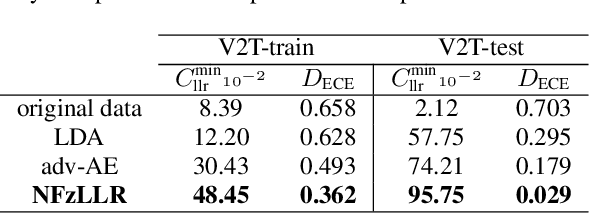
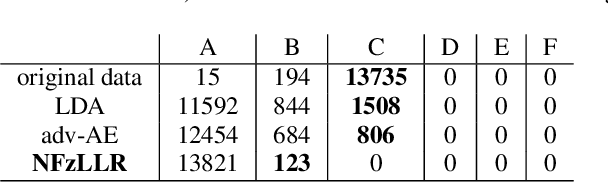
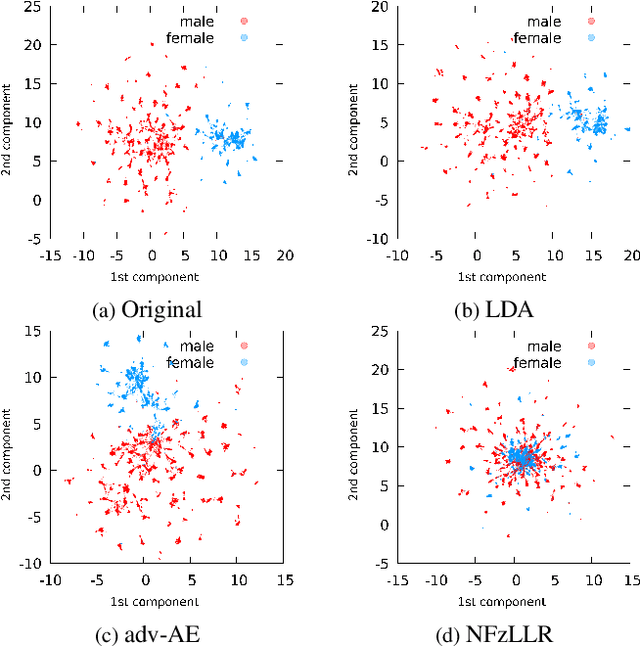
Attribute-driven privacy aims to conceal a single user's attribute, contrary to anonymisation that tries to hide the full identity of the user in some data. When the attribute to protect from malicious inferences is binary, perfect privacy requires the log-likelihood-ratio to be zero resulting in no strength-of-evidence. This work presents an approach based on normalizing flow that maps a feature vector into a latent space where the strength-of-evidence, related to the binary attribute, and an independent residual are disentangled. It can be seen as a non-linear discriminant analysis where the mapping is invertible allowing generation by mapping the latent variable back to the original space. This framework allows to manipulate the log-likelihood-ratio of the data and thus to set it to zero for privacy. We show the applicability of the approach on an attribute-driven privacy task where the sex information is removed from speaker embeddings. Results on VoxCeleb2 dataset show the efficiency of the method that outperforms in terms of privacy and utility our previous experiments based on adversarial disentanglement.
The VoicePrivacy 2020 Challenge: Results and findings
Sep 01, 2021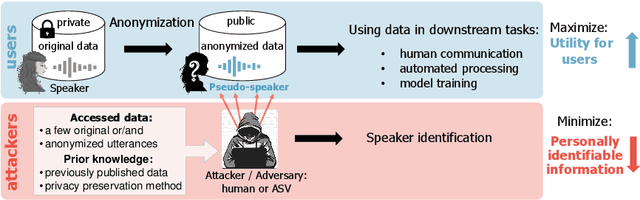
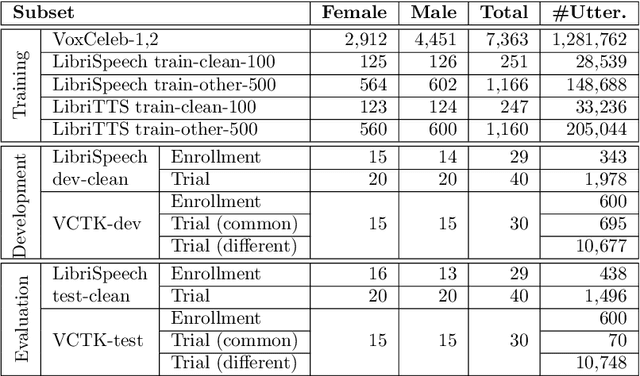
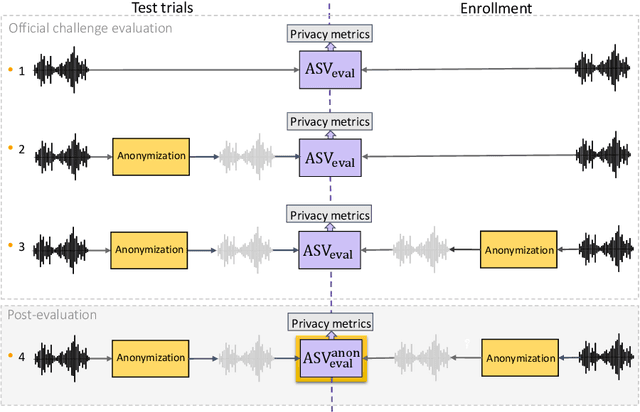
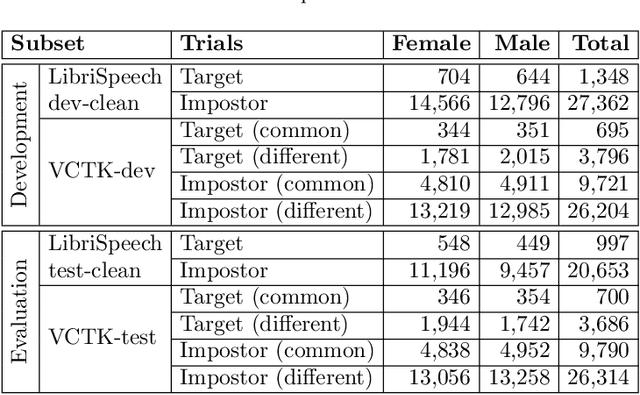
This paper presents the results and analyses stemming from the first VoicePrivacy 2020 Challenge which focuses on developing anonymization solutions for speech technology. We provide a systematic overview of the challenge design with an analysis of submitted systems and evaluation results. In particular, we describe the voice anonymization task and datasets used for system development and evaluation. Also, we present different attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and provide a summary description of the anonymization systems developed by the challenge participants. We report objective and subjective evaluation results for baseline and submitted systems. In addition, we present experimental results for alternative privacy metrics and attack models developed as a part of the post-evaluation analysis. Finally, we summarize our insights and observations that will influence the design of the next VoicePrivacy challenge edition and some directions for future voice anonymization research.
Adversarial Disentanglement of Speaker Representation for Attribute-Driven Privacy Preservation
Dec 08, 2020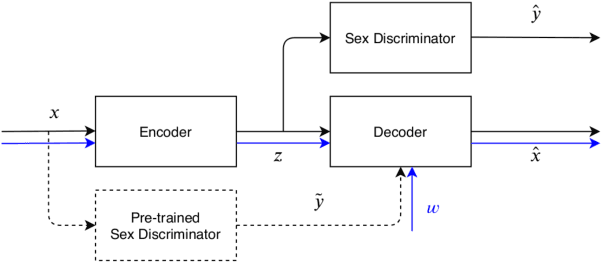

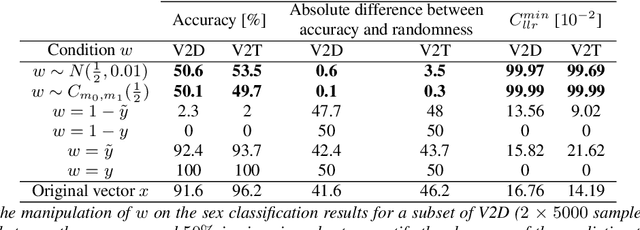
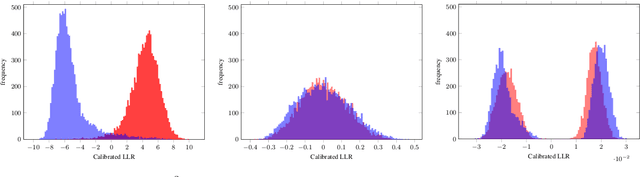
With the increasing interest over speech technologies, numerous Automatic Speaker Verification (ASV) systems are employed to perform person identification. In the latter context, the systems rely on neural embeddings as a speaker representation. Nonetheless, such representations may contain privacy sensitive information about the speakers (e.g. age, sex, ethnicity, ...). In this paper, we introduce the concept of attribute-driven privacy preservation that enables a person to hide one or a few personal aspects to the authentication component. As a first solution we define an adversarial autoencoding method that disentangles a given speaker attribute from its neural representation. The proposed approach is assessed with a focus on the sex attribute. Experiments carried out using the VoxCeleb data sets have shown that the defined model enables the manipulation (i.e. variation or hiding) of this attribute while preserving good ASV performance.
Introducing the VoicePrivacy Initiative
May 13, 2020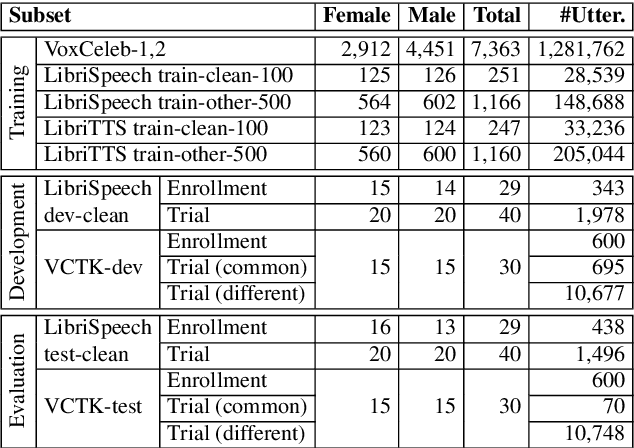
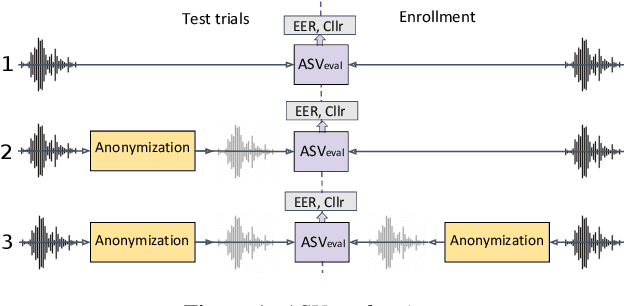
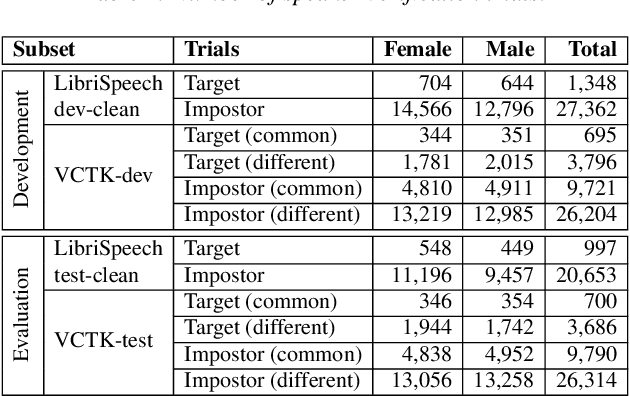
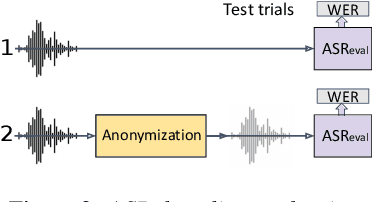
The VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this paper, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.