 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnglish to Central Kurdish Speech Translation: Corpus Creation, Evaluation, and Orthographic Standardization
Apr 01, 2026We present KUTED, a speech-to-text translation (S2TT) dataset for Central Kurdish, derived from TED and TEDx talks. The corpus comprises 91,000 sentence pairs, including 170 hours of English audio, 1.65 million English tokens, and 1.40 million Central Kurdish tokens. We evaluate KUTED on the S2TT task and find that orthographic variation significantly degrades Kurdish translation performance, producing nonstandard outputs. To address this, we propose a systematic text standardization approach that yields substantial performance gains and more consistent translations. On a test set separated from TED talks, a fine-tuned Seamless model achieves 15.18 BLEU, and we improve Seamless baseline by 3.0 BLEU on the FLEURS benchmark. We also train a Transformer model from scratch and evaluate a cascaded system that combines Seamless (ASR) with NLLB (MT).
FLEURS-Kobani: Extending the FLEURS Dataset for Northern Kurdish
Mar 31, 2026FLEURS offers n-way parallel speech for 100+ languages, but Northern Kurdish is not one of them, which limits benchmarking for automatic speech recognition and speech translation tasks in this language. We present FLEURS-Kobani, a Northern Kurdish (ISO 639-3 KMR) spoken extension of the FLEURS benchmark. The FLEURS-Kobani dataset consists of 5,162 validated utterances, totaling 18 hours and 24 minutes. The data were recorded by 31 native speakers. It extends benchmark coverage to an under-resourced Kurdish variety. As baselines, we fine-tuned Whisper v3-large for ASR and E2E S2TT. A two-stage fine-tuning strategy (Common Voice to FLEURS-Kobani) yields the best ASR performance (WER 28.11, CER 9.84 on test). For E2E S2TT (KMR to EN), Whisper achieves 8.68 BLEU on test; we additionally report pivot-derived targets and a cascaded S2TT setup. FLEURS-Kobani provides the first public Northern Kurdish benchmark for evaluation of ASR, S2TT and S2ST tasks. The dataset is publicly released for research use under a CC BY 4.0 license.
How to Leverage DNN-based speech enhancement for multi-channel speaker verification?
Oct 17, 2022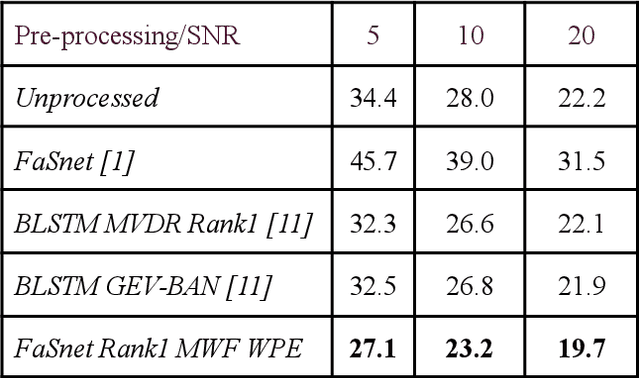
Speaker verification (SV) suffers from unsatisfactory performance in far-field scenarios due to environmental noise andthe adverse impact of room reverberation. This work presents a benchmark of multichannel speech enhancement for far-fieldspeaker verification. One approach is a deep neural network-based, and the other is a combination of deep neural network andsignal processing. We integrated a DNN architecture with signal processing techniques to carry out various experiments. Ourapproach is compared to the existing state-of-the-art approaches. We examine the importance of enrollment in pre-processing,which has been largely overlooked in previous studies. Experimental evaluation shows that pre-processing can improve the SVperformance as long as the enrollment files are processed similarly to the test data and that test and enrollment occur within similarSNR ranges. Considerable improvement is obtained on the generated and all the noise conditions of the VOiCES dataset.
Central Kurdish machine translation: First large scale parallel corpus and experiments
Jun 17, 2021
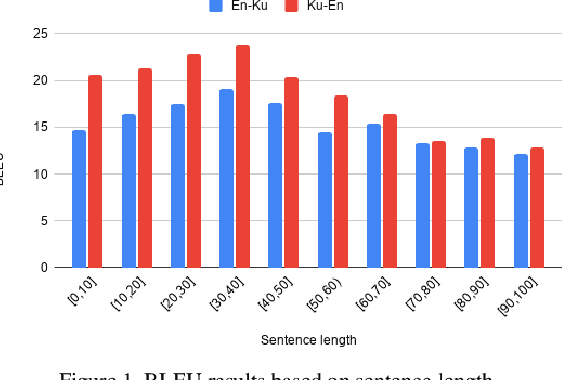
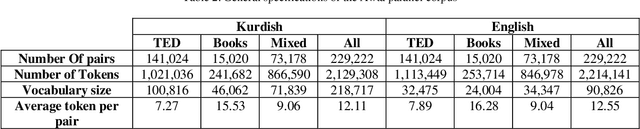
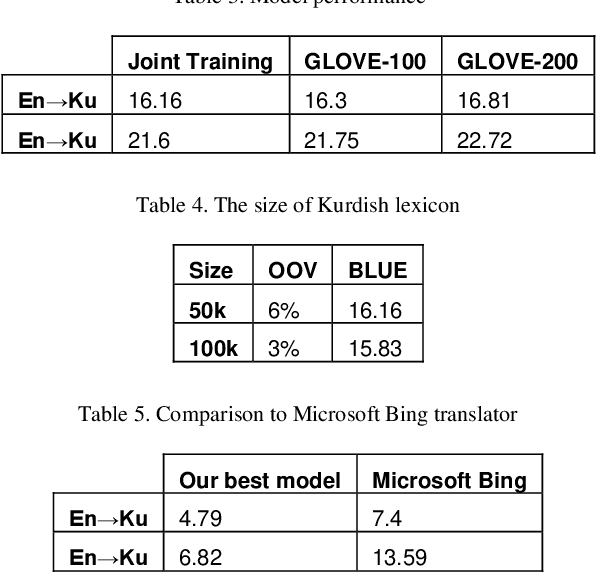
While the computational processing of Kurdish has experienced a relative increase, the machine translation of this language seems to be lacking a considerable body of scientific work. This is in part due to the lack of resources especially curated for this task. In this paper, we present the first large scale parallel corpus of Central Kurdish-English, Awta, containing 229,222 pairs of manually aligned translations. Our corpus is collected from different text genres and domains in an attempt to build more robust and real-world applications of machine translation. We make a portion of this corpus publicly available in order to foster research in this area. Further, we build several neural machine translation models in order to benchmark the task of Kurdish machine translation. Additionally, we perform extensive experimental analysis of results in order to identify the major challenges that Central Kurdish machine translation faces. These challenges include language-dependent and-independent ones as categorized in this paper, the first group of which are aware of Central Kurdish linguistic properties on different morphological, syntactic and semantic levels. Our best performing systems achieve 22.72 and 16.81 in BLEU score for Ku$\rightarrow$EN and En$\rightarrow$Ku, respectively.
Jira: a Kurdish Speech Recognition System Designing and Building Speech Corpus and Pronunciation Lexicon
Feb 15, 2021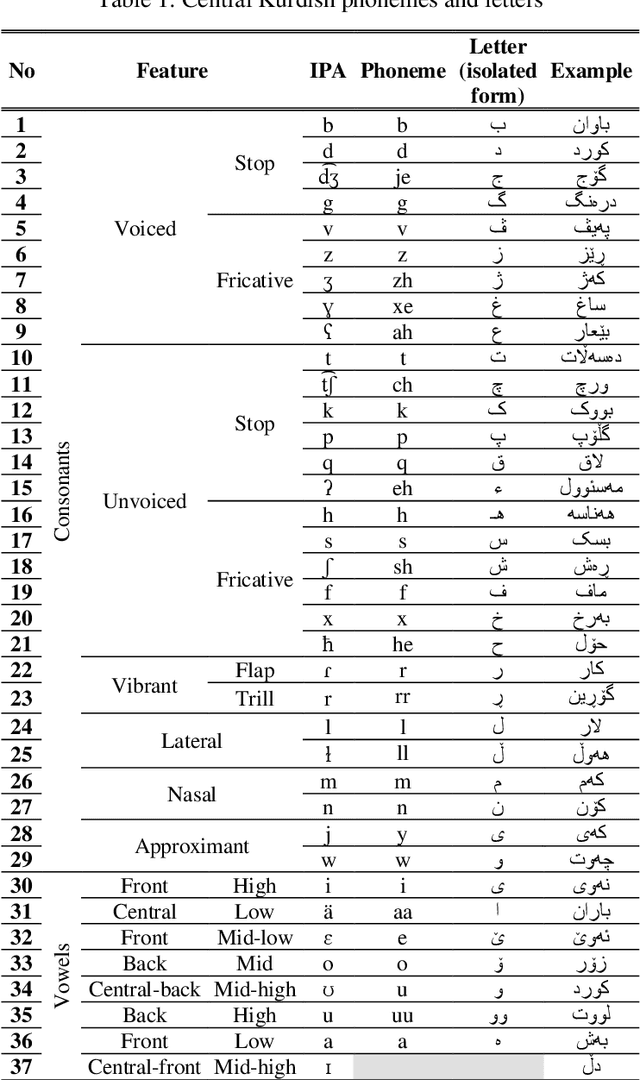
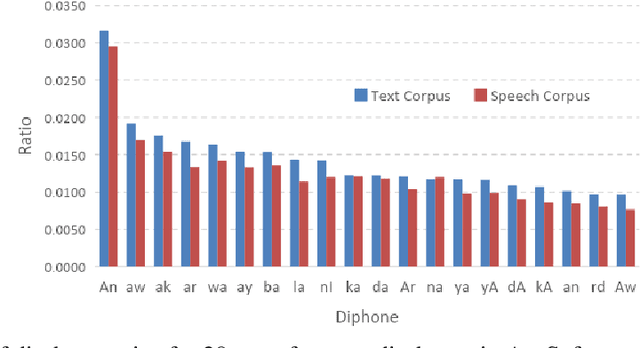

In this paper, we introduce the first large vocabulary speech recognition system (LVSR) for the Central Kurdish language, named Jira. The Kurdish language is an Indo-European language spoken by more than 30 million people in several countries, but due to the lack of speech and text resources, there is no speech recognition system for this language. To fill this gap, we introduce the first speech corpus and pronunciation lexicon for the Kurdish language. Regarding speech corpus, we designed a sentence collection in which the ratio of di-phones in the collection resembles the real data of the Central Kurdish language. The designed sentences are uttered by 576 speakers in a controlled environment with noise-free microphones (called AsoSoft Speech-Office) and in Telegram social network environment using mobile phones (denoted as AsoSoft Speech-Crowdsourcing), resulted in 43.68 hours of speech. Besides, a test set including 11 different document topics is designed and recorded in two corresponding speech conditions (i.e., Office and Crowdsourcing). Furthermore, a 60K pronunciation lexicon is prepared in this research in which we faced several challenges and proposed solutions for them. The Kurdish language has several dialects and sub-dialects that results in many lexical variations. Our methods for script standardization of lexical variations and automatic pronunciation of the lexicon tokens are presented in detail. To setup the recognition engine, we used the Kaldi toolkit. A statistical tri-gram language model that is extracted from the AsoSoft text corpus is used in the system. Several standard recipes including HMM-based models (i.e., mono, tri1, tr2, tri2, tri3), SGMM, and DNN methods are used to generate the acoustic model. These methods are trained with AsoSoft Speech-Office and AsoSoft Speech-Crowdsourcing and a combination of them. The best performance achieved by the SGMM acoustic model which results in 13.9% of the average word error rate (on different document topics) and 4.9% for the general topic.
Adversarial Disentanglement of Speaker Representation for Attribute-Driven Privacy Preservation
Dec 08, 2020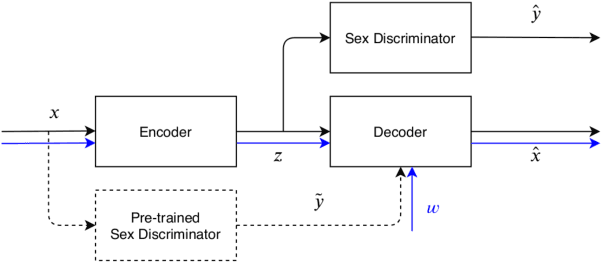

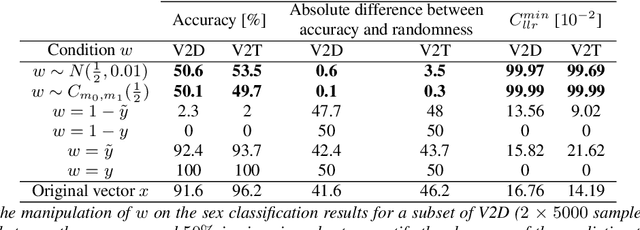
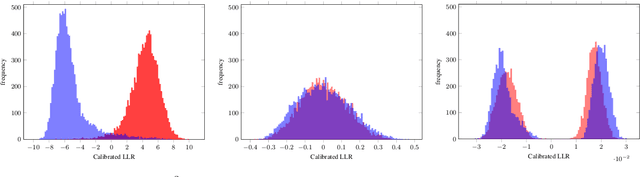
With the increasing interest over speech technologies, numerous Automatic Speaker Verification (ASV) systems are employed to perform person identification. In the latter context, the systems rely on neural embeddings as a speaker representation. Nonetheless, such representations may contain privacy sensitive information about the speakers (e.g. age, sex, ethnicity, ...). In this paper, we introduce the concept of attribute-driven privacy preservation that enables a person to hide one or a few personal aspects to the authentication component. As a first solution we define an adversarial autoencoding method that disentangles a given speaker attribute from its neural representation. The proposed approach is assessed with a focus on the sex attribute. Experiments carried out using the VoxCeleb data sets have shown that the defined model enables the manipulation (i.e. variation or hiding) of this attribute while preserving good ASV performance.
Data augmentation versus noise compensation for x- vector speaker recognition systems in noisy environments
Jun 29, 2020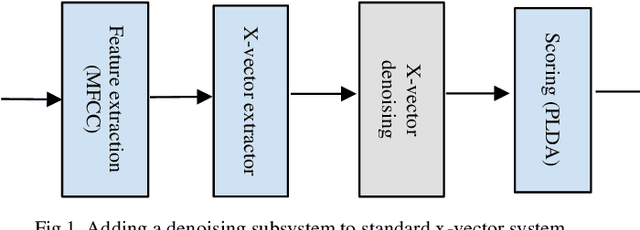
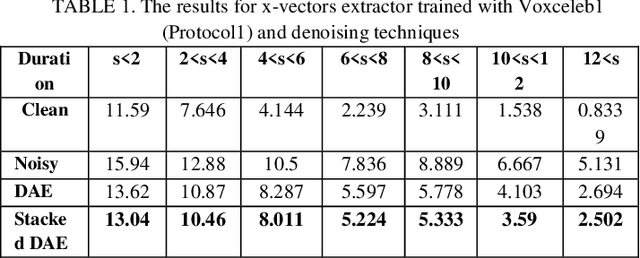
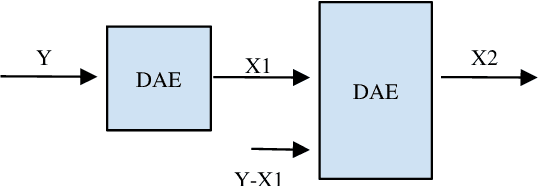
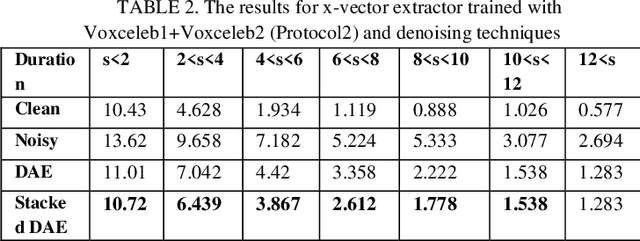
The explosion of available speech data and new speaker modeling methods based on deep neural networks (DNN) have given the ability to develop more robust speaker recognition systems. Among DNN speaker modelling techniques, x-vector system has shown a degree of robustness in noisy environments. Previous studies suggest that by increasing the number of speakers in the training data and using data augmentation more robust speaker recognition systems are achievable in noisy environments. In this work, we want to know if explicit noise compensation techniques continue to be effective despite the general noise robustness of these systems. For this study, we will use two different x-vector networks: the first one is trained on Voxceleb1 (Protocol1), and the second one is trained on Voxceleb1+Voxveleb2 (Protocol2). We propose to add a denoising x-vector subsystem before scoring. Experimental results show that, the x-vector system used in Protocol2 is more robust than the other one used Protocol1. Despite this observation we will show that explicit noise compensation gives almost the same EER relative gain in both protocols. For example, in the Protocol2 we have 21% to 66% improvement of EER with denoising techniques.