 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData augmentation versus noise compensation for x- vector speaker recognition systems in noisy environments
Paper and Code
Jun 29, 2020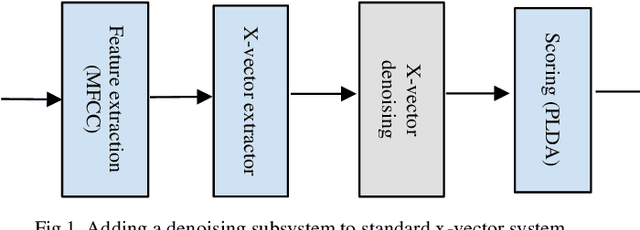
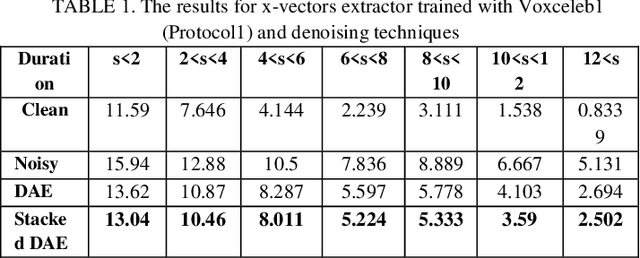
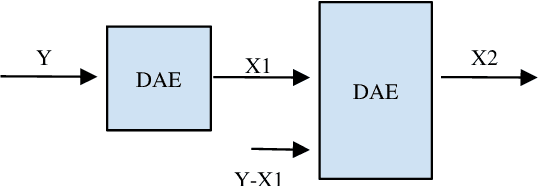
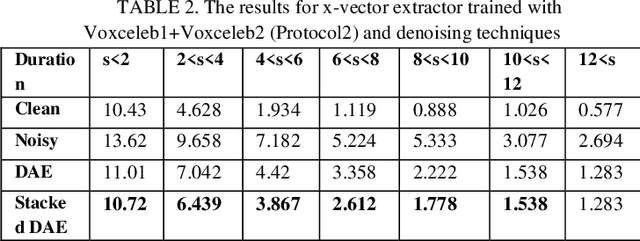
The explosion of available speech data and new speaker modeling methods based on deep neural networks (DNN) have given the ability to develop more robust speaker recognition systems. Among DNN speaker modelling techniques, x-vector system has shown a degree of robustness in noisy environments. Previous studies suggest that by increasing the number of speakers in the training data and using data augmentation more robust speaker recognition systems are achievable in noisy environments. In this work, we want to know if explicit noise compensation techniques continue to be effective despite the general noise robustness of these systems. For this study, we will use two different x-vector networks: the first one is trained on Voxceleb1 (Protocol1), and the second one is trained on Voxceleb1+Voxveleb2 (Protocol2). We propose to add a denoising x-vector subsystem before scoring. Experimental results show that, the x-vector system used in Protocol2 is more robust than the other one used Protocol1. Despite this observation we will show that explicit noise compensation gives almost the same EER relative gain in both protocols. For example, in the Protocol2 we have 21% to 66% improvement of EER with denoising techniques.