 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Self-Supervised Speech Models to Mixture-of-Experts for Robust Anti-Spoofing
Jun 12, 2026Recent advances in speech generation have significantly improved the naturalness of synthetic speech, making spoofing detection increasingly challenging. A key limitation of current anti-spoofing systems is their limited robustness to unseen synthesis methods. In this work, we transform a self-supervised speech representation model into a Mixture-of-Experts (MoE) architecture to improve generalization. Feed-forward blocks in selected encoder layers are replaced by multiple expert networks controlled by a layer-wise gating mechanism, allowing experts to capture complementary acoustic patterns while preserving the representations learned during self-supervised pretraining. We further analyze the architectural choices affecting the performance of this MoE conversion and investigate the activation behavior of the experts. The proposed approach is evaluated on 14 spoofing datasets and reduces the macro EER from 5.46% to 4.81%, corresponding to 11.9% relative improvement over the baseline.
Speaker-Invariant Representation Learning for Spoofing Detection via Gradient Reversal and A Variational Information Bottleneck
Jun 07, 2026Sophisticated generative speech technology can undermined the reliability of voice biometrics. While spoofing detection systems excel when assessed under in-domain conditions, generalisation to out-of-domain settings is often poor. In this paper, we show that such issues could be caused by speaker bias, where models learn individual voice traits rather than markers of manipulation or generation. We propose a teacher-student framework for speaker-invariant spoofing detection that disentangles identity without requiring speaker labels. We leverage a pre-trained speaker recognition teacher to guide a student model via a gradient reversal layer. To control the balance between suppressing cues related to voice identity with the preservation of those related to spoofing detection, we integrate a Variational Information Bottleneck. Evaluations across nine datasets show our model achieves a 25.7% relative reduction to the EER compared to the MHFA baseline.
A Comparison of SSL-Based Feature Extractors and Back-End Classifiers for Spoofing Detection: A Multi-Corpus Training and Cross-Linguistic Analysis
Jun 07, 2026Voice biometric systems face growing threats from spoofing attacks, yet the evaluation of detection models remains inconsistent across datasets. To investigate these unpredictable fluctuations, we conduct a comprehensive benchmark of four self-supervised learning feature extractors paired with four back-end classifiers. We compare the hierarchical local feature extraction of ResNet with the global sequence and relational modeling of attention and graph-based back-ends. Through multi-corpus training across three scenarios and six evaluation datasets, our empirical analysis yields two critical findings. First, we expose a domain bias within the ASVspoof 5 dataset, showing that naive data scaling actively degrades performance. Second, our cross-linguistic analysis reveals that fine-tuning with just 8 hours of target-language data enhances detection robustness. Together, these findings emphasize the critical need for domain-aware and language-specific adaptation in spoofing detection.
Assessing the Energy and Carbon Emissions of Neural Speaker Verification Model in Training and Inference
Jun 06, 2026Deep-learning speaker verification (SV) increasingly relies on deep neural network backbones, whose environmental impact remains largely undocumented. In this paper, we conduct an evaluation of ResNet architectures trained on VoxCeleb2, varying depth, channel width, and stage distribution, and measure energy consumption and carbon footprint using node-level sensors. Results show a clear point of diminishing returns: deeper or wider models bring only marginal accuracy gains while energy consumption grows steeply. In contrast, mid-sized networks such as ResNet-50 and stage-concentrated variants achieve favorable trade-offs between performance and environmental impact. These findings provide actionable guidelines for designing energy-efficient SV systems.
On Low-Bit Quantization Errors in Speaker Verification: Diagnostic and Mitigation
Jun 06, 2026Although low-bit quantization provides practical means to deploy speaker verification on resource-constrained devices, its effects on speaker verification performance remain poorly understood. In this paper, we study uniform K-means quantization-aware training of ResNet-36 and ResNet-200 through joint layer-wise and score-level analyses. Our layer-wise analysis highlights fragile components and shows that score degradation is not fully explained by weight distortion alone. We identify a clear knee point at 2 bits, with larger score drift and harmful decision flips concentrated near the FP32 threshold. Our score-level analysis reveals where and how score errors emerge under extreme quantization. Building on these findings, we propose a calibrated multi-precision cascade that resolves most trials at 2 bits and escalates only ambiguous cases, achieving performance close to FP32 while preserving the efficiency benefits of low-bit inference with substantially lower compute and memory costs.
Enhancing Multi-Corpus Training in SSL-Based Anti-Spoofing Models: Domain-Invariant Feature Extraction
Mar 19, 2026The performance of speech spoofing detection often varies across different training and evaluation corpora. Leveraging multiple corpora typically enhances robustness and performance in fields like speaker recognition and speech recognition. However, our spoofing detection experiments show that multi-corpus training does not consistently improve performance and may even degrade it. We hypothesize that dataset-specific biases impair generalization, leading to performance instability. To address this, we propose an Invariant Domain Feature Extraction (IDFE) framework, employing multi-task learning and a gradient reversal layer to minimize corpus-specific information in learned embeddings. The IDFE framework reduces the average equal error rate by 20% compared to the baseline, assessed across four varied datasets.
Assessing the Impact of Speaker Identity in Speech Spoofing Detection
Feb 24, 2026Spoofing detection systems are typically trained using diverse recordings from multiple speakers, often assuming that the resulting embeddings are independent of speaker identity. However, this assumption remains unverified. In this paper, we investigate the impact of speaker information on spoofing detection systems. We propose two approaches within our Speaker-Invariant Multi-Task framework, one that models speaker identity within the embeddings and another that removes it. SInMT integrates multi-task learning for joint speaker recognition and spoofing detection, incorporating a gradient reversal layer. Evaluated using four datasets, our speaker-invariant model reduces the average equal error rate by 17% compared to the baseline, with up to 48% reduction for the most challenging attacks (e.g., A11).
The distribution of calibrated likelihood functions on the probability-likelihood Aitchison simplex
Sep 03, 2025



While calibration of probabilistic predictions has been widely studied, this paper rather addresses calibration of likelihood functions. This has been discussed, especially in biometrics, in cases with only two exhaustive and mutually exclusive hypotheses (classes) where likelihood functions can be written as log-likelihood-ratios (LLRs). After defining calibration for LLRs and its connection with the concept of weight-of-evidence, we present the idempotence property and its associated constraint on the distribution of the LLRs. Although these results have been known for decades, they have been limited to the binary case. Here, we extend them to cases with more than two hypotheses by using the Aitchison geometry of the simplex, which allows us to recover, in a vector form, the additive form of the Bayes' rule; extending therefore the LLR and the weight-of-evidence to any number of hypotheses. Especially, we extend the definition of calibration, the idempotence, and the constraint on the distribution of likelihood functions to this multiple hypotheses and multiclass counterpart of the LLR: the isometric-log-ratio transformed likelihood function. This work is mainly conceptual, but we still provide one application to machine learning by presenting a non-linear discriminant analysis where the discriminant components form a calibrated likelihood function over the classes, improving therefore the interpretability and the reliability of the method.
Hiding speaker's sex in speech using zero-evidence speaker representation in an analysis/synthesis pipeline
Nov 29, 2022The use of modern vocoders in an analysis/synthesis pipeline allows us to investigate high-quality voice conversion that can be used for privacy purposes. Here, we propose to transform the speaker embedding and the pitch in order to hide the sex of the speaker. ECAPA-TDNN-based speaker representation fed into a HiFiGAN vocoder is protected using a neural-discriminant analysis approach, which is consistent with the zero-evidence concept of privacy. This approach significantly reduces the information in speech related to the speaker's sex while preserving speech content and some consistency in the resulting protected voices.
How to Leverage DNN-based speech enhancement for multi-channel speaker verification?
Oct 17, 2022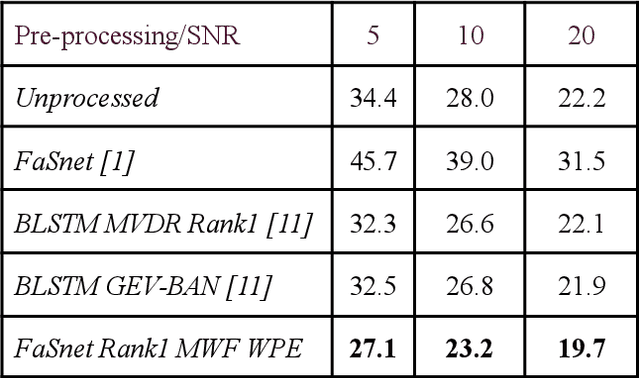
Speaker verification (SV) suffers from unsatisfactory performance in far-field scenarios due to environmental noise andthe adverse impact of room reverberation. This work presents a benchmark of multichannel speech enhancement for far-fieldspeaker verification. One approach is a deep neural network-based, and the other is a combination of deep neural network andsignal processing. We integrated a DNN architecture with signal processing techniques to carry out various experiments. Ourapproach is compared to the existing state-of-the-art approaches. We examine the importance of enrollment in pre-processing,which has been largely overlooked in previous studies. Experimental evaluation shows that pre-processing can improve the SVperformance as long as the enrollment files are processed similarly to the test data and that test and enrollment occur within similarSNR ranges. Considerable improvement is obtained on the generated and all the noise conditions of the VOiCES dataset.