 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe distribution of calibrated likelihood functions on the probability-likelihood Aitchison simplex
Sep 03, 2025



While calibration of probabilistic predictions has been widely studied, this paper rather addresses calibration of likelihood functions. This has been discussed, especially in biometrics, in cases with only two exhaustive and mutually exclusive hypotheses (classes) where likelihood functions can be written as log-likelihood-ratios (LLRs). After defining calibration for LLRs and its connection with the concept of weight-of-evidence, we present the idempotence property and its associated constraint on the distribution of the LLRs. Although these results have been known for decades, they have been limited to the binary case. Here, we extend them to cases with more than two hypotheses by using the Aitchison geometry of the simplex, which allows us to recover, in a vector form, the additive form of the Bayes' rule; extending therefore the LLR and the weight-of-evidence to any number of hypotheses. Especially, we extend the definition of calibration, the idempotence, and the constraint on the distribution of likelihood functions to this multiple hypotheses and multiclass counterpart of the LLR: the isometric-log-ratio transformed likelihood function. This work is mainly conceptual, but we still provide one application to machine learning by presenting a non-linear discriminant analysis where the discriminant components form a calibrated likelihood function over the classes, improving therefore the interpretability and the reliability of the method.
Asymmetric and trial-dependent modeling: the contribution of LIA to SdSV Challenge Task 2
Mar 28, 2024
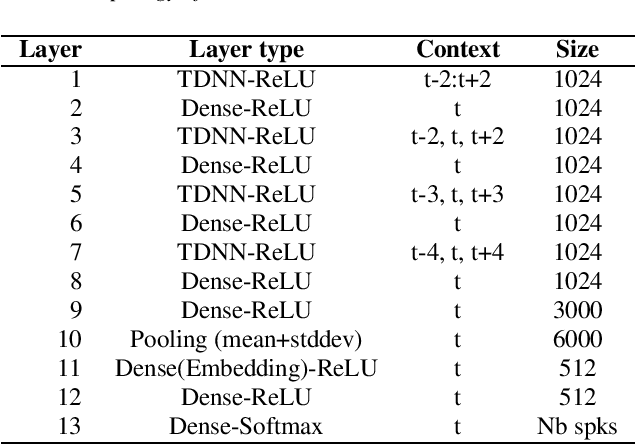

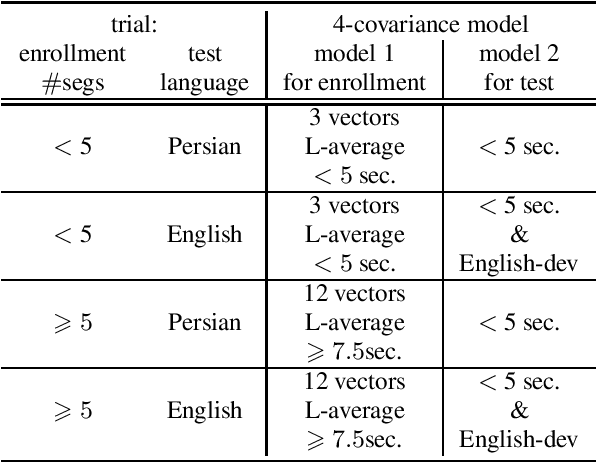
The SdSv challenge Task 2 provided an opportunity to assess efficiency and robustness of modern text-independent speaker verification systems. But it also made it possible to test new approaches, capable of taking into account the main issues of this challenge (duration, language, ...). This paper describes the contributions of our laboratory to the speaker recognition field. These contributions highlight two other challenges in addition to short-duration and language: the mismatch between enrollment and test data and the one between subsets of the evaluation trial dataset. The proposed approaches experimentally show their relevance and efficiency on the SdSv evaluation, and could be of interest in many real-life applications.
Jeffreys divergence-based regularization of neural network output distribution applied to speaker recognition
Dec 28, 2023

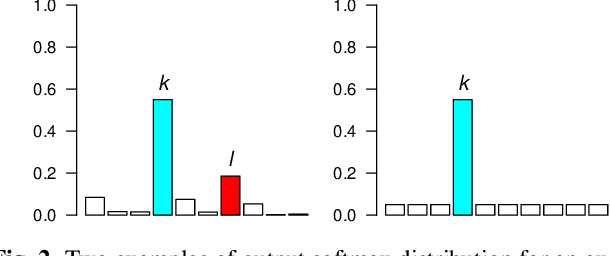
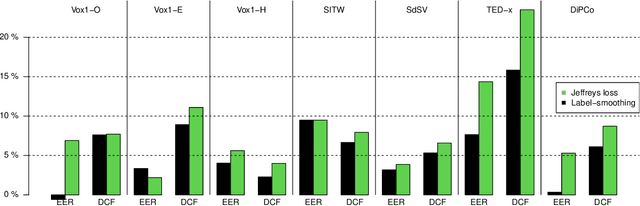
A new loss function for speaker recognition with deep neural network is proposed, based on Jeffreys Divergence. Adding this divergence to the cross-entropy loss function allows to maximize the target value of the output distribution while smoothing the non-target values. This objective function provides highly discriminative features. Beyond this effect, we propose a theoretical justification of its effectiveness and try to understand how this loss function affects the model, in particular the impact on dataset types (i.e. in-domain or out-of-domain w.r.t the training corpus). Our experiments show that Jeffreys loss consistently outperforms the state-of-the-art for speaker recognition, especially on out-of-domain data, and helps limit false alarms.
I4U System Description for NIST SRE'20 CTS Challenge
Nov 02, 2022



This manuscript describes the I4U submission to the 2020 NIST Speaker Recognition Evaluation (SRE'20) Conversational Telephone Speech (CTS) Challenge. The I4U's submission was resulted from active collaboration among researchers across eight research teams - I$^2$R (Singapore), UEF (Finland), VALPT (Italy, Spain), NEC (Japan), THUEE (China), LIA (France), NUS (Singapore), INRIA (France) and TJU (China). The submission was based on the fusion of top performing sub-systems and sub-fusion systems contributed by individual teams. Efforts have been spent on the use of common development and validation sets, submission schedule and milestone, minimizing inconsistency in trial list and score file format across sites.
A bridge between features and evidence for binary attribute-driven perfect privacy
Oct 12, 2021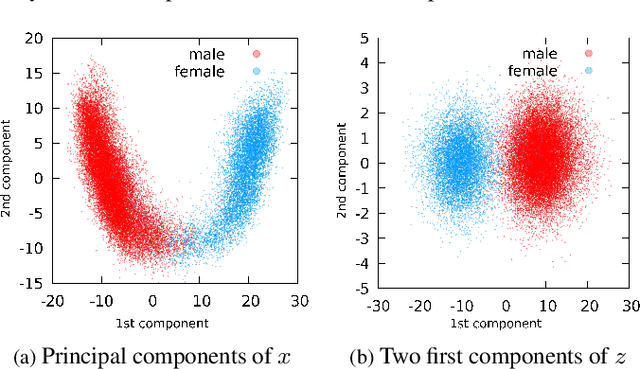
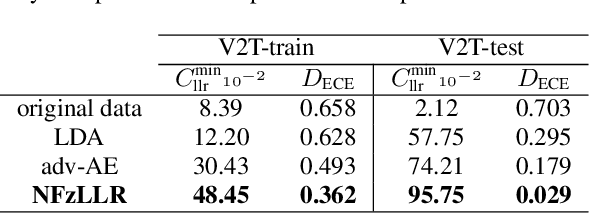
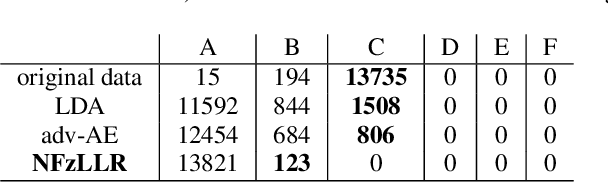
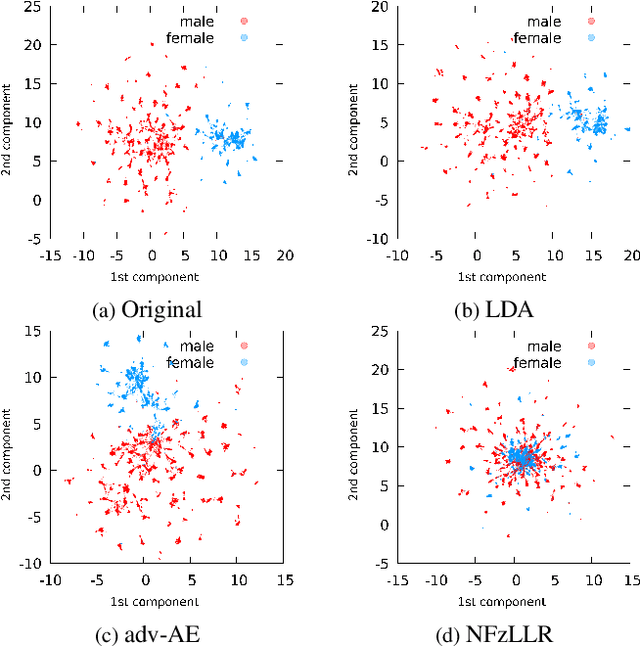
Attribute-driven privacy aims to conceal a single user's attribute, contrary to anonymisation that tries to hide the full identity of the user in some data. When the attribute to protect from malicious inferences is binary, perfect privacy requires the log-likelihood-ratio to be zero resulting in no strength-of-evidence. This work presents an approach based on normalizing flow that maps a feature vector into a latent space where the strength-of-evidence, related to the binary attribute, and an independent residual are disentangled. It can be seen as a non-linear discriminant analysis where the mapping is invertible allowing generation by mapping the latent variable back to the original space. This framework allows to manipulate the log-likelihood-ratio of the data and thus to set it to zero for privacy. We show the applicability of the approach on an attribute-driven privacy task where the sex information is removed from speaker embeddings. Results on VoxCeleb2 dataset show the efficiency of the method that outperforms in terms of privacy and utility our previous experiments based on adversarial disentanglement.
Studying squeeze-and-excitation used in CNN for speaker verification
Sep 13, 2021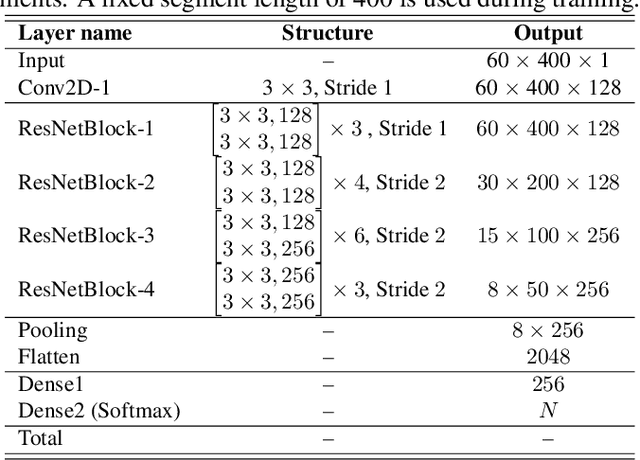
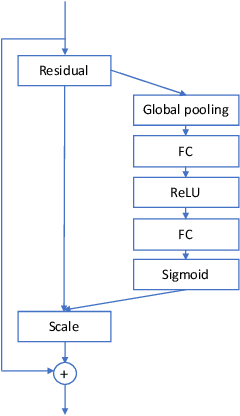


In speaker verification, the extraction of voice representations is mainly based on the Residual Neural Network (ResNet) architecture. ResNet is built upon convolution layers which learn filters to capture local spatial patterns along all the input, then generate feature maps that jointly encode the spatial and channel information. Unfortunately, all feature maps in a convolution layer are learnt independently (the convolution layer does not exploit the dependencies between feature maps) and locally. This problem has first been tackled in image processing. A channel attention mechanism, called squeeze-and-excitation (SE), has recently been proposed in convolution layers and applied to speaker verification. This mechanism re-weights the information extracted across features maps. In this paper, we first propose an original qualitative study about the influence and the role of the SE mechanism applied to the speaker verification task at different stages of the ResNet, and then evaluate several SE architectures. We finally propose to improve the SE approach with a new pool- ing variant based on the concatenation of mean- and standard- deviation-pooling. Results showed that applying SE only on the first stages of the ResNet allows to better capture speaker information for the verification task, and that significant discrimination gains on Voxceleb1-E, Voxceleb1-H and SITW evaluation tasks have been noted using the proposed pooling variant.
Study on the temporal pooling used in deep neural networks for speaker verification
May 10, 2021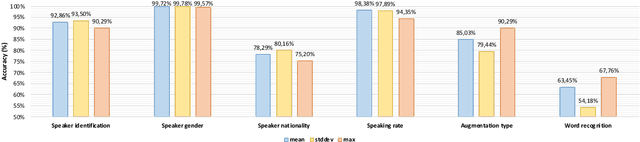
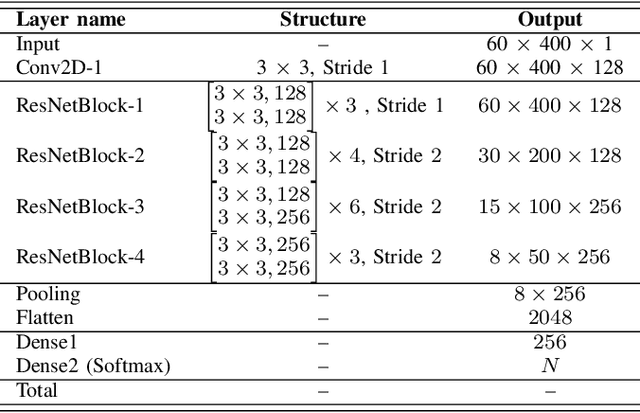
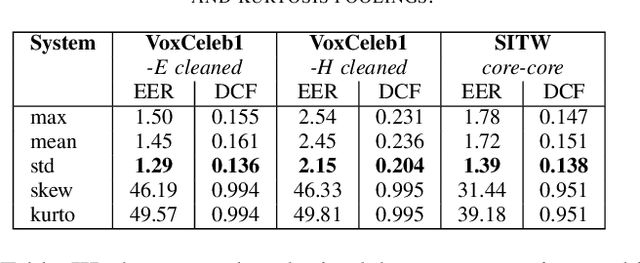
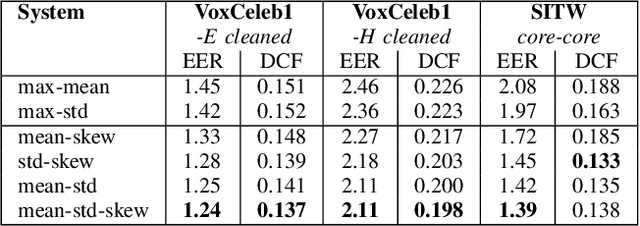
The x-vector architecture has recently achieved state-of-the-art results on the speaker verification task. This architecture incorporates a central layer, referred to as temporal pooling, which stacks statistical parameters of the acoustic frame distribution. This work proposes to highlight the significant effect of the temporal pooling content on the training dynamics and task performance. An evaluation with different pooling layers is conducted, that is, including different statistical measures of central tendency. Notably, 3rd and 4th moment-based statistics (skewness and kurtosis) are also tested to complete the usual mean and standard-deviation parameters. Our experiments show the influence of the pooling layer content in terms of speaker verification performance, but also for several classification tasks (speaker, channel or text related), and allow to better reveal the presence of external information to the speaker identity depending on the layer content.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019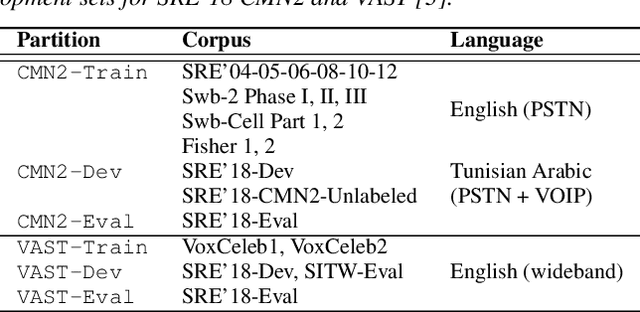
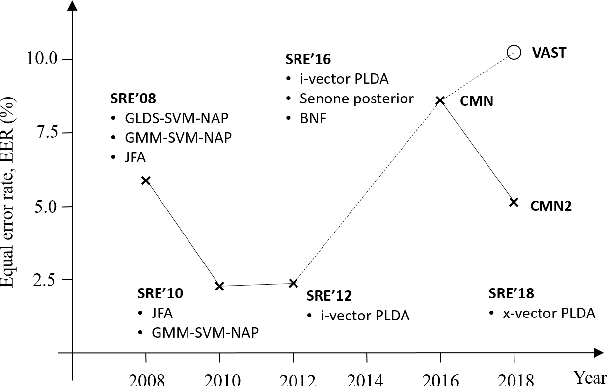
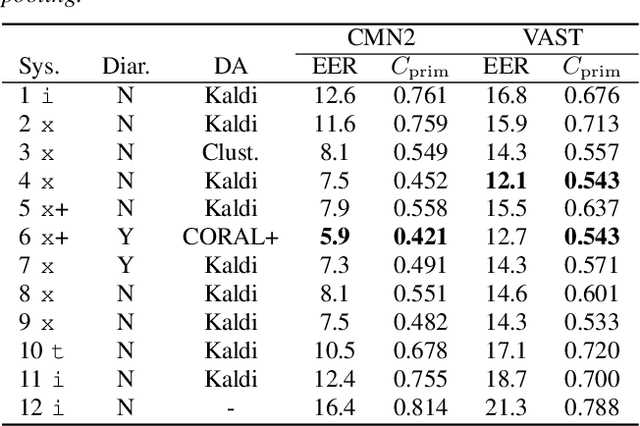
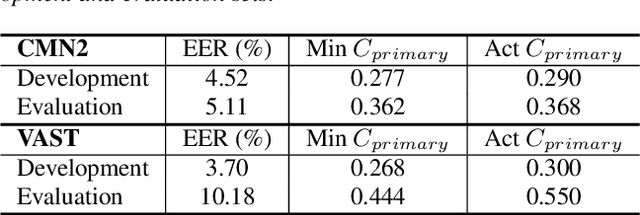
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.