 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeffreys divergence-based regularization of neural network output distribution applied to speaker recognition
Paper and Code
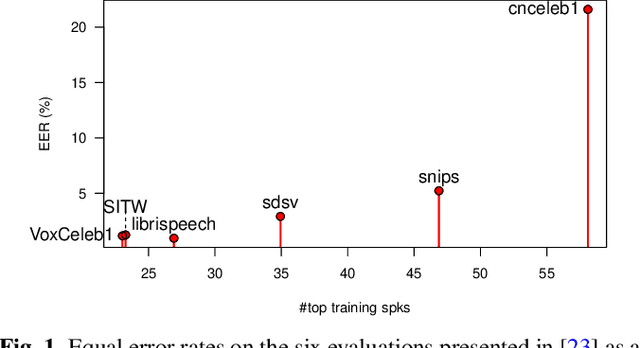

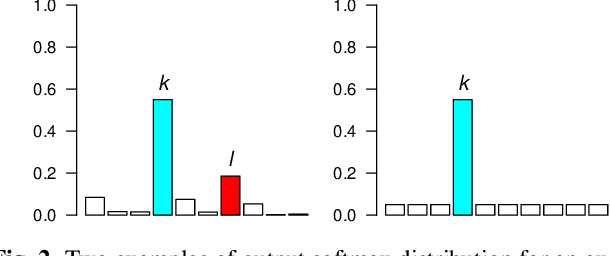
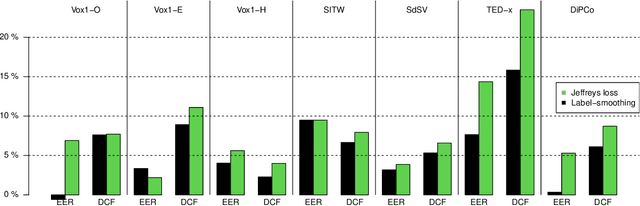
A new loss function for speaker recognition with deep neural network is proposed, based on Jeffreys Divergence. Adding this divergence to the cross-entropy loss function allows to maximize the target value of the output distribution while smoothing the non-target values. This objective function provides highly discriminative features. Beyond this effect, we propose a theoretical justification of its effectiveness and try to understand how this loss function affects the model, in particular the impact on dataset types (i.e. in-domain or out-of-domain w.r.t the training corpus). Our experiments show that Jeffreys loss consistently outperforms the state-of-the-art for speaker recognition, especially on out-of-domain data, and helps limit false alarms.