Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric and trial-dependent modeling: the contribution of LIA to SdSV Challenge Task 2
Paper and Code
Mar 28, 2024
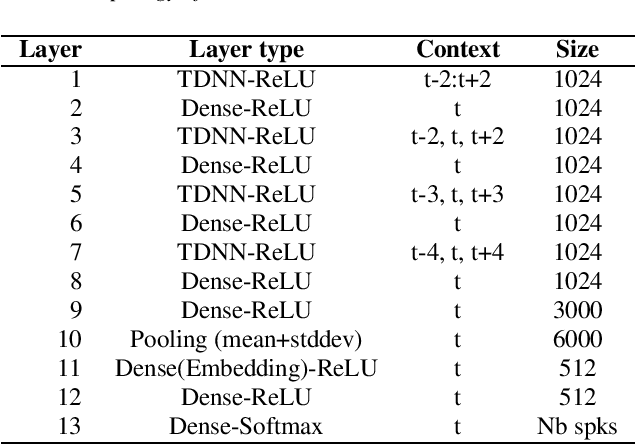

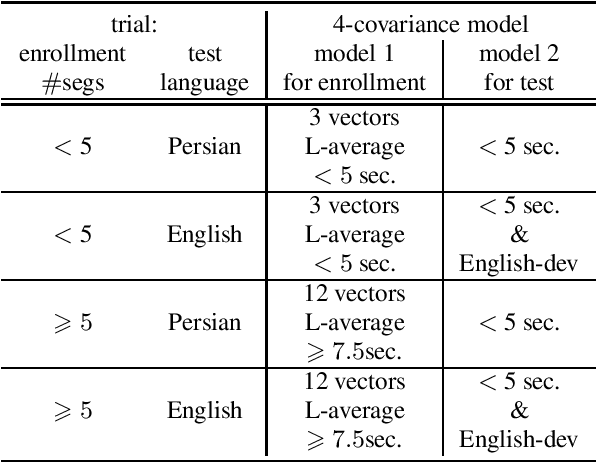
The SdSv challenge Task 2 provided an opportunity to assess efficiency and robustness of modern text-independent speaker verification systems. But it also made it possible to test new approaches, capable of taking into account the main issues of this challenge (duration, language, ...). This paper describes the contributions of our laboratory to the speaker recognition field. These contributions highlight two other challenges in addition to short-duration and language: the mismatch between enrollment and test data and the one between subsets of the evaluation trial dataset. The proposed approaches experimentally show their relevance and efficiency on the SdSv evaluation, and could be of interest in many real-life applications.
* LIA system description for the Short Duration Speaker Verification
(SdSv) challenge 2020 Task 2
View paper on