 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying squeeze-and-excitation used in CNN for speaker verification
Paper and Code
Sep 13, 2021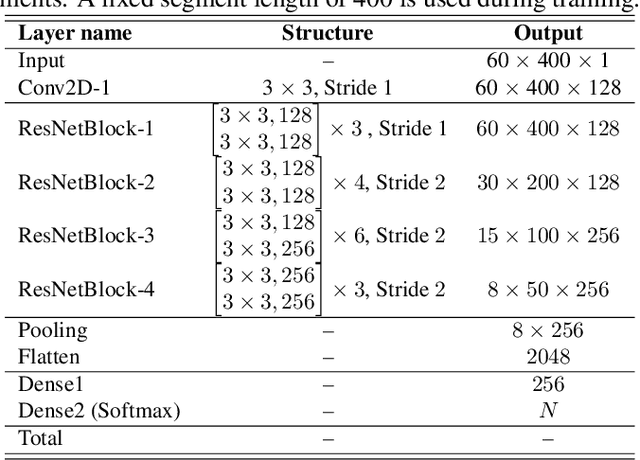
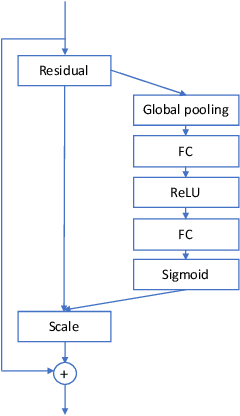


In speaker verification, the extraction of voice representations is mainly based on the Residual Neural Network (ResNet) architecture. ResNet is built upon convolution layers which learn filters to capture local spatial patterns along all the input, then generate feature maps that jointly encode the spatial and channel information. Unfortunately, all feature maps in a convolution layer are learnt independently (the convolution layer does not exploit the dependencies between feature maps) and locally. This problem has first been tackled in image processing. A channel attention mechanism, called squeeze-and-excitation (SE), has recently been proposed in convolution layers and applied to speaker verification. This mechanism re-weights the information extracted across features maps. In this paper, we first propose an original qualitative study about the influence and the role of the SE mechanism applied to the speaker verification task at different stages of the ResNet, and then evaluate several SE architectures. We finally propose to improve the SE approach with a new pool- ing variant based on the concatenation of mean- and standard- deviation-pooling. Results showed that applying SE only on the first stages of the ResNet allows to better capture speaker information for the verification task, and that significant discrimination gains on Voxceleb1-E, Voxceleb1-H and SITW evaluation tasks have been noted using the proposed pooling variant.