 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Disentanglement of Speaker Representation for Attribute-Driven Privacy Preservation
Paper and Code
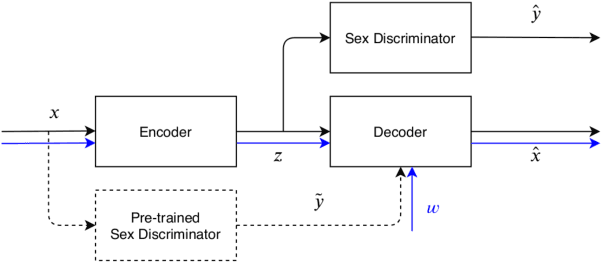

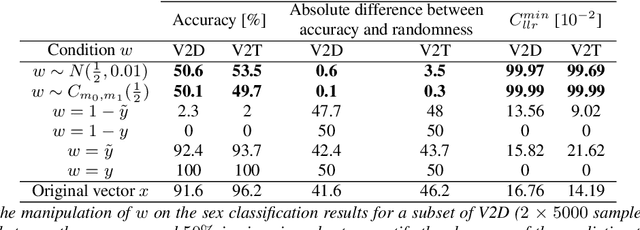
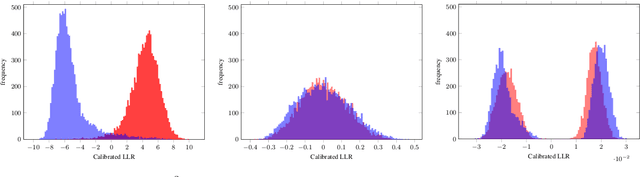
With the increasing interest over speech technologies, numerous Automatic Speaker Verification (ASV) systems are employed to perform person identification. In the latter context, the systems rely on neural embeddings as a speaker representation. Nonetheless, such representations may contain privacy sensitive information about the speakers (e.g. age, sex, ethnicity, ...). In this paper, we introduce the concept of attribute-driven privacy preservation that enables a person to hide one or a few personal aspects to the authentication component. As a first solution we define an adversarial autoencoding method that disentangles a given speaker attribute from its neural representation. The proposed approach is assessed with a focus on the sex attribute. Experiments carried out using the VoxCeleb data sets have shown that the defined model enables the manipulation (i.e. variation or hiding) of this attribute while preserving good ASV performance.