 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised learning with diffusion-based multichannel speech enhancement for speaker verification under noisy conditions
Jul 05, 2023The paper introduces Diff-Filter, a multichannel speech enhancement approach based on the diffusion probabilistic model, for improving speaker verification performance under noisy and reverberant conditions. It also presents a new two-step training procedure that takes the benefit of self-supervised learning. In the first stage, the Diff-Filter is trained by conducting timedomain speech filtering using a scoring-based diffusion model. In the second stage, the Diff-Filter is jointly optimized with a pre-trained ECAPA-TDNN speaker verification model under a self-supervised learning framework. We present a novel loss based on equal error rate. This loss is used to conduct selfsupervised learning on a dataset that is not labelled in terms of speakers. The proposed approach is evaluated on MultiSV, a multichannel speaker verification dataset, and shows significant improvements in performance under noisy multichannel conditions.
Evaluation of Speaker Anonymization on Emotional Speech
Apr 15, 2023Speech data carries a range of personal information, such as the speaker's identity and emotional state. These attributes can be used for malicious purposes. With the development of virtual assistants, a new generation of privacy threats has emerged. Current studies have addressed the topic of preserving speech privacy. One of them, the VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology. The task selected for the VoicePrivacy 2020 Challenge (VPC) is about speaker anonymization. The goal is to hide the source speaker's identity while preserving the linguistic information. The baseline of the VPC makes use of a voice conversion. This paper studies the impact of the speaker anonymization baseline system of the VPC on emotional information present in speech utterances. Evaluation is performed following the VPC rules regarding the attackers' knowledge about the anonymization system. Our results show that the VPC baseline system does not suppress speakers' emotions against informed attackers. When comparing anonymized speech to original speech, the emotion recognition performance is degraded by 15\% relative to IEMOCAP data, similar to the degradation observed for automatic speech recognition used to evaluate the preservation of the linguistic information.
How to Leverage DNN-based speech enhancement for multi-channel speaker verification?
Oct 17, 2022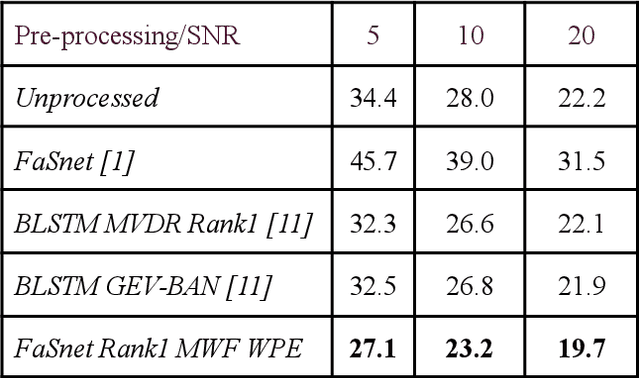
Speaker verification (SV) suffers from unsatisfactory performance in far-field scenarios due to environmental noise andthe adverse impact of room reverberation. This work presents a benchmark of multichannel speech enhancement for far-fieldspeaker verification. One approach is a deep neural network-based, and the other is a combination of deep neural network andsignal processing. We integrated a DNN architecture with signal processing techniques to carry out various experiments. Ourapproach is compared to the existing state-of-the-art approaches. We examine the importance of enrollment in pre-processing,which has been largely overlooked in previous studies. Experimental evaluation shows that pre-processing can improve the SVperformance as long as the enrollment files are processed similarly to the test data and that test and enrollment occur within similarSNR ranges. Considerable improvement is obtained on the generated and all the noise conditions of the VOiCES dataset.
Are disentangled representations all you need to build speaker anonymization systems?
Aug 24, 2022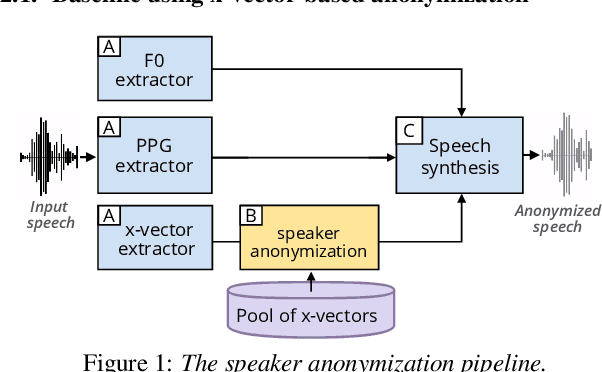
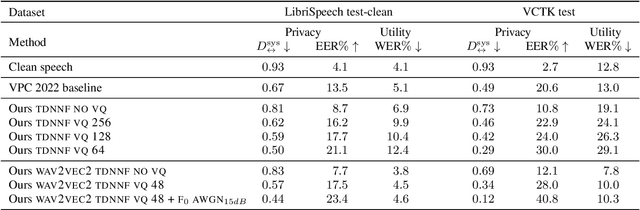
Speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns when speech data get collected. Speaker anonymization aims to transform a speech signal to remove the source speaker's identity while leaving the spoken content unchanged. Current methods perform the transformation by relying on content/speaker disentanglement and voice conversion. Usually, an acoustic model from an automatic speech recognition system extracts the content representation while an x-vector system extracts the speaker representation. Prior work has shown that the extracted features are not perfectly disentangled. This paper tackles how to improve features disentanglement, and thus the converted anonymized speech. We propose enhancing the disentanglement by removing speaker information from the acoustic model using vector quantization. Evaluation done using the VoicePrivacy 2022 toolkit showed that vector quantization helps conceal the original speaker identity while maintaining utility for speech recognition.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022

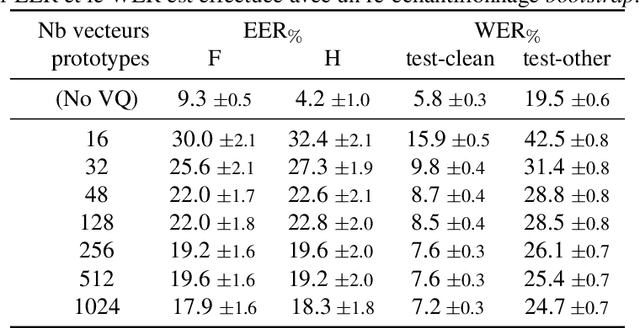
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).
On the invertibility of a voice privacy system using embedding alignement
Oct 08, 2021
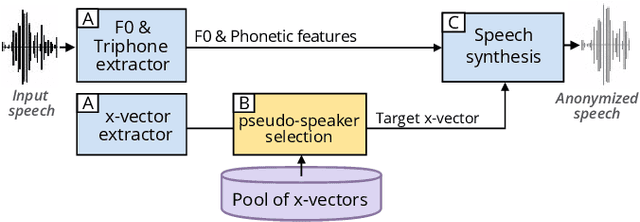
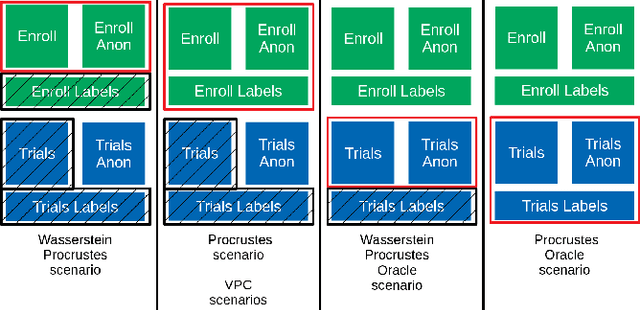
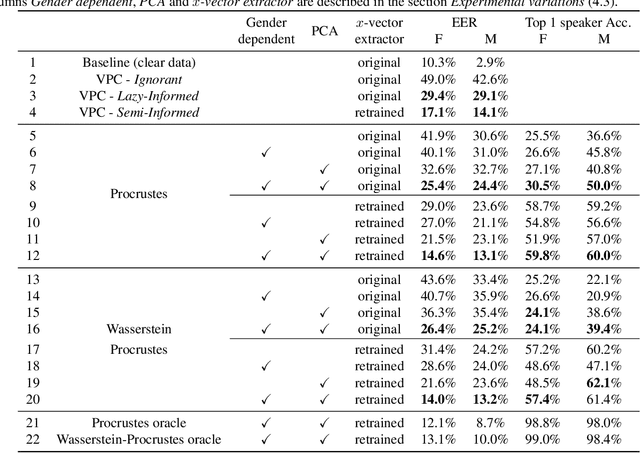
This paper explores various attack scenarios on a voice anonymization system using embeddings alignment techniques. We use Wasserstein-Procrustes (an algorithm initially designed for unsupervised translation) or Procrustes analysis to match two sets of x-vectors, before and after voice anonymization, to mimic this transformation as a rotation function. We compute the optimal rotation and compare the results of this approximation to the official Voice Privacy Challenge results. We show that a complex system like the baseline of the Voice Privacy Challenge can be approximated by a rotation, estimated using a limited set of x-vectors. This paper studies the space of solutions for voice anonymization within the specific scope of rotations. Rotations being reversible, the proposed method can recover up to 62% of the speaker identities from anonymized embeddings.
Evaluating X-vector-based Speaker Anonymization under White-box Assessment
Sep 30, 2021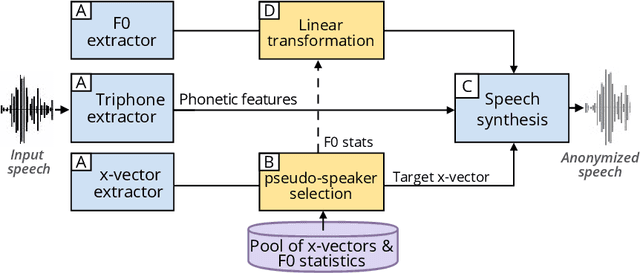

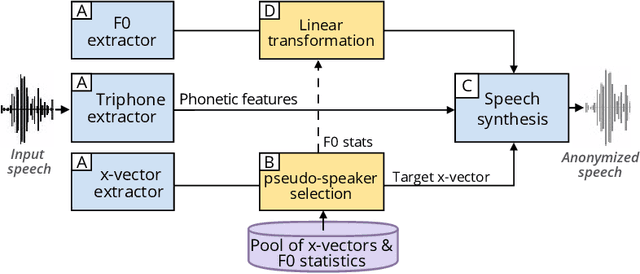
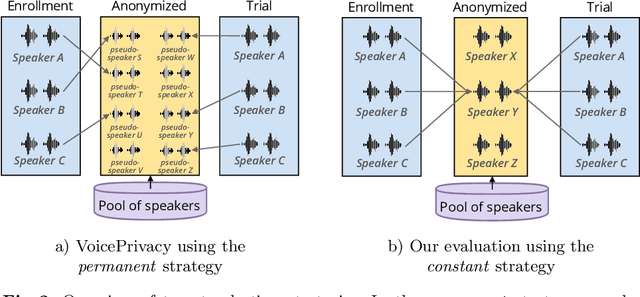
In the scenario of the Voice Privacy challenge, anonymization is achieved by converting all utterances from a source speaker to match the same target identity; this identity being randomly selected. In this context, an attacker with maximum knowledge about the anonymization system can not infer the target identity. This article proposed to constrain the target selection to a specific identity, i.e., removing the random selection of identity, to evaluate the extreme threat under a whitebox assessment (the attacker has complete knowledge about the system). Targeting a unique identity also allows us to investigate whether some target's identities are better than others to anonymize a given speaker.
A Study of F0 Modification for X-Vector Based Speech Pseudonymization Across Gender
Jan 21, 2021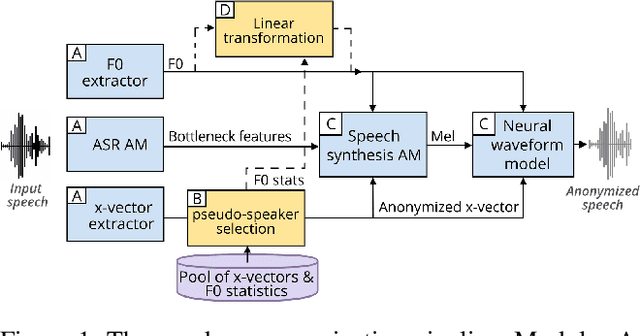


Speech pseudonymization aims at altering a speech signal to map the identifiable personal characteristics of a given speaker to another identity. In other words, it aims to hide the source speaker identity while preserving the intelligibility of the spoken content. This study takes place in the VoicePrivacy 2020 challenge framework, where the baseline system performs pseudonymization by modifying x-vector information to match a target speaker while keeping the fundamental frequency (F0) unchanged. We propose to alter other paralin-guistic features, here F0, and analyze the impact of this modification across gender. We found that the proposed F0 modification always improves pseudonymization We observed that both source and target speaker genders affect the performance gain when modifying the F0.