 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Third VoicePrivacy Challenge: Preserving Emotional Expressiveness and Linguistic Content in Voice Anonymization
Jan 17, 2026We present results and analyses from the third VoicePrivacy Challenge held in 2024, which focuses on advancing voice anonymization technologies. The task was to develop a voice anonymization system for speech data that conceals a speaker's voice identity while preserving linguistic content and emotional state. We provide a systematic overview of the challenge framework, including detailed descriptions of the anonymization task and datasets used for both system development and evaluation. We outline the attack model and objective evaluation metrics for assessing privacy protection (concealing speaker voice identity) and utility (content and emotional state preservation). We describe six baseline anonymization systems and summarize the innovative approaches developed by challenge participants. Finally, we provide key insights and observations to guide the design of future VoicePrivacy challenges and identify promising directions for voice anonymization research.
The Risks and Detection of Overestimated Privacy Protection in Voice Anonymisation
Jul 30, 2025Voice anonymisation aims to conceal the voice identity of speakers in speech recordings. Privacy protection is usually estimated from the difficulty of using a speaker verification system to re-identify the speaker post-anonymisation. Performance assessments are therefore dependent on the verification model as well as the anonymisation system. There is hence potential for privacy protection to be overestimated when the verification system is poorly trained, perhaps with mismatched data. In this paper, we demonstrate the insidious risk of overestimating anonymisation performance and show examples of exaggerated performance reported in the literature. For the worst case we identified, performance is overestimated by 74% relative. We then introduce a means to detect when performance assessment might be untrustworthy and show that it can identify all overestimation scenarios presented in the paper. Our solution is openly available as a fork of the 2024 VoicePrivacy Challenge evaluation toolkit.
The VoicePrivacy 2022 Challenge: Progress and Perspectives in Voice Anonymisation
Jul 16, 2024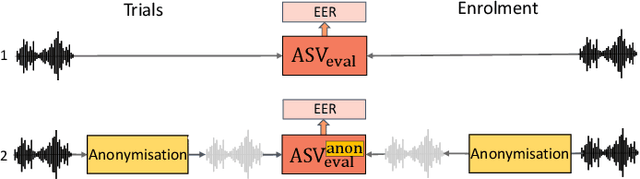
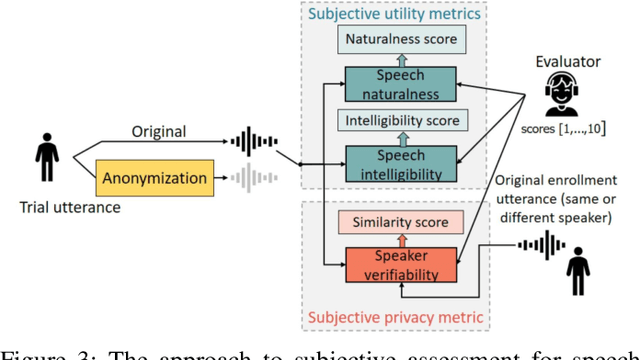
The VoicePrivacy Challenge promotes the development of voice anonymisation solutions for speech technology. In this paper we present a systematic overview and analysis of the second edition held in 2022. We describe the voice anonymisation task and datasets used for system development and evaluation, present the different attack models used for evaluation, and the associated objective and subjective metrics. We describe three anonymisation baselines, provide a summary description of the anonymisation systems developed by challenge participants, and report objective and subjective evaluation results for all. In addition, we describe post-evaluation analyses and a summary of related work reported in the open literature. Results show that solutions based on voice conversion better preserve utility, that an alternative which combines automatic speech recognition with synthesis achieves greater privacy, and that a privacy-utility trade-off remains inherent to current anonymisation solutions. Finally, we present our ideas and priorities for future VoicePrivacy Challenge editions.
The VoicePrivacy 2024 Challenge Evaluation Plan
Apr 03, 2024
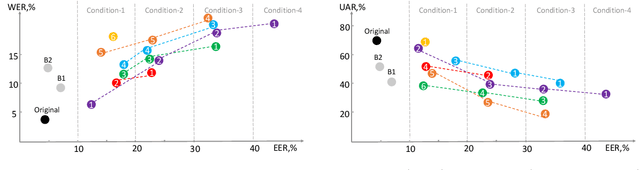
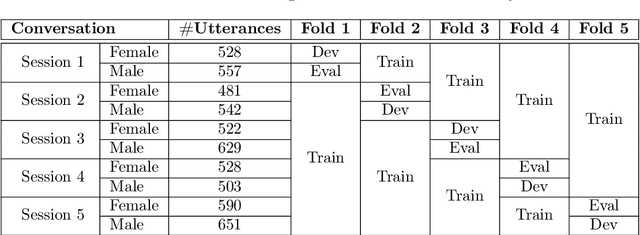
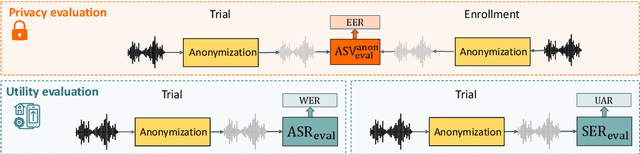
The task of the challenge is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content and emotional states. The organizers provide development and evaluation datasets and evaluation scripts, as well as baseline anonymization systems and a list of training resources formed on the basis of the participants' requests. Participants apply their developed anonymization systems, run evaluation scripts and submit evaluation results and anonymized speech data to the organizers. Results will be presented at a workshop held in conjunction with Interspeech 2024 to which all participants are invited to present their challenge systems and to submit additional workshop papers.
Anonymizing Speech: Evaluating and Designing Speaker Anonymization Techniques
Aug 05, 2023


The growing use of voice user interfaces has led to a surge in the collection and storage of speech data. While data collection allows for the development of efficient tools powering most speech services, it also poses serious privacy issues for users as centralized storage makes private personal speech data vulnerable to cyber threats. With the increasing use of voice-based digital assistants like Amazon's Alexa, Google's Home, and Apple's Siri, and with the increasing ease with which personal speech data can be collected, the risk of malicious use of voice-cloning and speaker/gender/pathological/etc. recognition has increased. This thesis proposes solutions for anonymizing speech and evaluating the degree of the anonymization. In this work, anonymization refers to making personal speech data unlinkable to an identity while maintaining the usefulness (utility) of the speech signal (e.g., access to linguistic content). We start by identifying several challenges that evaluation protocols need to consider to evaluate the degree of privacy protection properly. We clarify how anonymization systems must be configured for evaluation purposes and highlight that many practical deployment configurations do not permit privacy evaluation. Furthermore, we study and examine the most common voice conversion-based anonymization system and identify its weak points before suggesting new methods to overcome some limitations. We isolate all components of the anonymization system to evaluate the degree of speaker PPI associated with each of them. Then, we propose several transformation methods for each component to reduce as much as possible speaker PPI while maintaining utility. We promote anonymization algorithms based on quantization-based transformation as an alternative to the most-used and well-known noise-based approach. Finally, we endeavor a new attack method to invert anonymization.
Evaluation of Speaker Anonymization on Emotional Speech
Apr 15, 2023Speech data carries a range of personal information, such as the speaker's identity and emotional state. These attributes can be used for malicious purposes. With the development of virtual assistants, a new generation of privacy threats has emerged. Current studies have addressed the topic of preserving speech privacy. One of them, the VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology. The task selected for the VoicePrivacy 2020 Challenge (VPC) is about speaker anonymization. The goal is to hide the source speaker's identity while preserving the linguistic information. The baseline of the VPC makes use of a voice conversion. This paper studies the impact of the speaker anonymization baseline system of the VPC on emotional information present in speech utterances. Evaluation is performed following the VPC rules regarding the attackers' knowledge about the anonymization system. Our results show that the VPC baseline system does not suppress speakers' emotions against informed attackers. When comparing anonymized speech to original speech, the emotion recognition performance is degraded by 15\% relative to IEMOCAP data, similar to the degradation observed for automatic speech recognition used to evaluate the preservation of the linguistic information.
Are disentangled representations all you need to build speaker anonymization systems?
Aug 24, 2022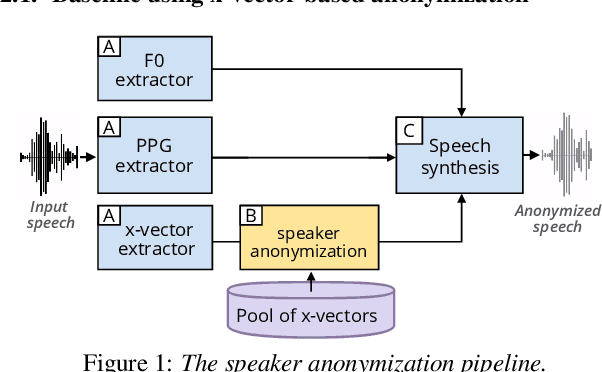
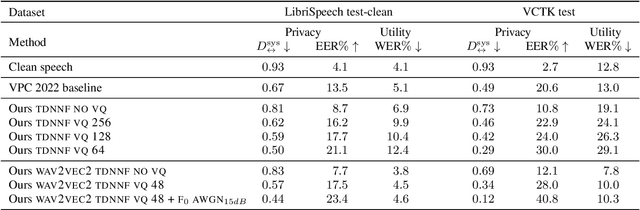
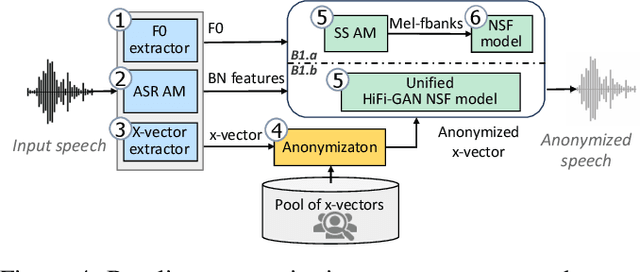
Speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns when speech data get collected. Speaker anonymization aims to transform a speech signal to remove the source speaker's identity while leaving the spoken content unchanged. Current methods perform the transformation by relying on content/speaker disentanglement and voice conversion. Usually, an acoustic model from an automatic speech recognition system extracts the content representation while an x-vector system extracts the speaker representation. Prior work has shown that the extracted features are not perfectly disentangled. This paper tackles how to improve features disentanglement, and thus the converted anonymized speech. We propose enhancing the disentanglement by removing speaker information from the acoustic model using vector quantization. Evaluation done using the VoicePrivacy 2022 toolkit showed that vector quantization helps conceal the original speaker identity while maintaining utility for speech recognition.
The VoicePrivacy 2022 Challenge Evaluation Plan
Mar 27, 2022
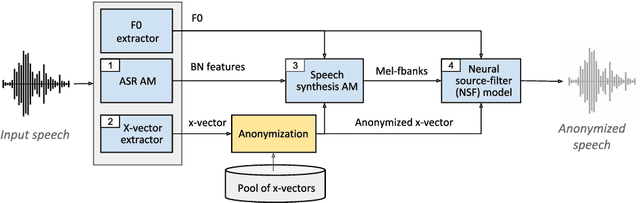
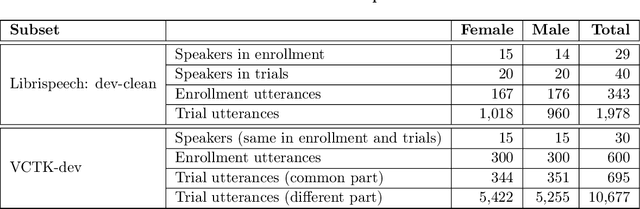
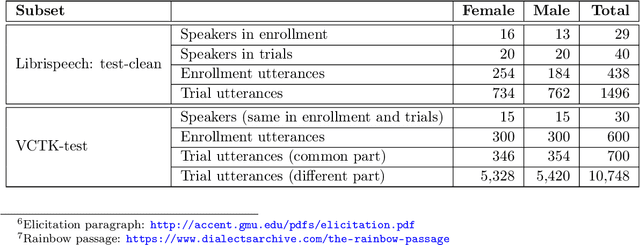
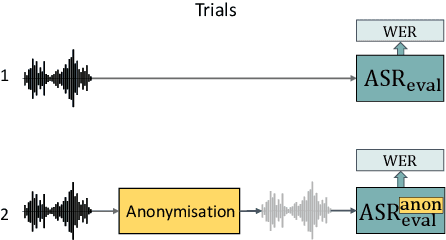
For new participants - Executive summary: (1) The task is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content, paralinguistic attributes, intelligibility and naturalness. (2) Training, development and evaluation datasets are provided in addition to 3 different baseline anonymization systems, evaluation scripts, and metrics. Participants apply their developed anonymization systems, run evaluation scripts and submit objective evaluation results and anonymized speech data to the organizers. (3) Results will be presented at a workshop held in conjunction with INTERSPEECH 2022 to which all participants are invited to present their challenge systems and to submit additional workshop papers. For readers familiar with the VoicePrivacy Challenge - Changes w.r.t. 2020: (1) A stronger, semi-informed attack model in the form of an automatic speaker verification (ASV) system trained on anonymized (per-utterance) speech data. (2) Complementary metrics comprising the equal error rate (EER) as a privacy metric, the word error rate (WER) as a primary utility metric, and the pitch correlation and gain of voice distinctiveness as secondary utility metrics. (3) A new ranking policy based upon a set of minimum target privacy requirements.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022
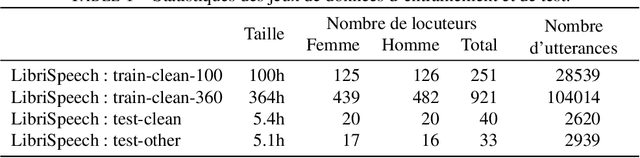

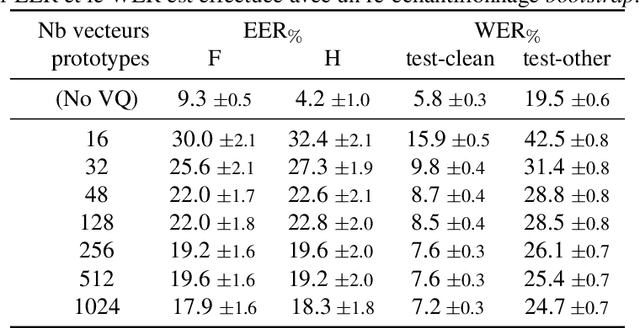
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).
On the invertibility of a voice privacy system using embedding alignement
Oct 08, 2021
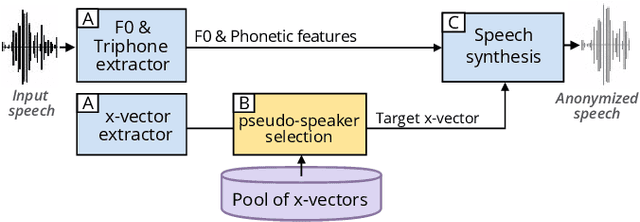
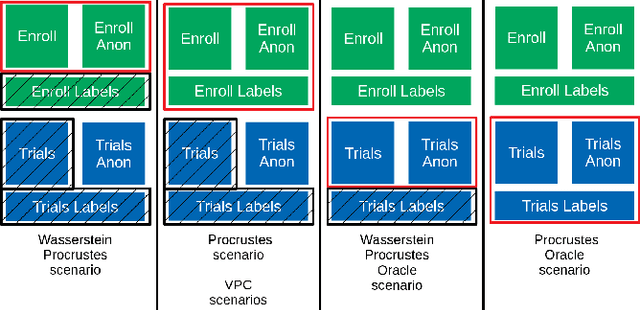
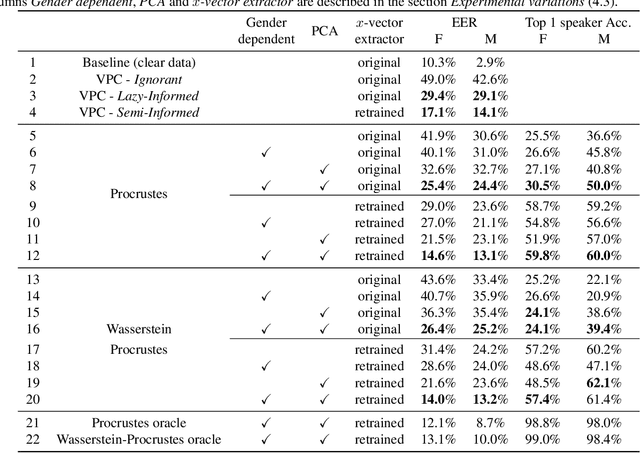
This paper explores various attack scenarios on a voice anonymization system using embeddings alignment techniques. We use Wasserstein-Procrustes (an algorithm initially designed for unsupervised translation) or Procrustes analysis to match two sets of x-vectors, before and after voice anonymization, to mimic this transformation as a rotation function. We compute the optimal rotation and compare the results of this approximation to the official Voice Privacy Challenge results. We show that a complex system like the baseline of the Voice Privacy Challenge can be approximated by a rotation, estimated using a limited set of x-vectors. This paper studies the space of solutions for voice anonymization within the specific scope of rotations. Rotations being reversible, the proposed method can recover up to 62% of the speaker identities from anonymized embeddings.