 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Leverage DNN-based speech enhancement for multi-channel speaker verification?
Paper and Code
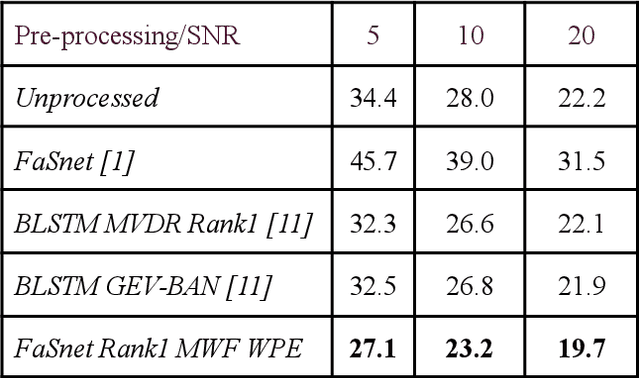
Speaker verification (SV) suffers from unsatisfactory performance in far-field scenarios due to environmental noise andthe adverse impact of room reverberation. This work presents a benchmark of multichannel speech enhancement for far-fieldspeaker verification. One approach is a deep neural network-based, and the other is a combination of deep neural network andsignal processing. We integrated a DNN architecture with signal processing techniques to carry out various experiments. Ourapproach is compared to the existing state-of-the-art approaches. We examine the importance of enrollment in pre-processing,which has been largely overlooked in previous studies. Experimental evaluation shows that pre-processing can improve the SVperformance as long as the enrollment files are processed similarly to the test data and that test and enrollment occur within similarSNR ranges. Considerable improvement is obtained on the generated and all the noise conditions of the VOiCES dataset.