 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCKMorph: A Comprehensive Morphological Analyzer for Central Kurdish
Sep 17, 2021

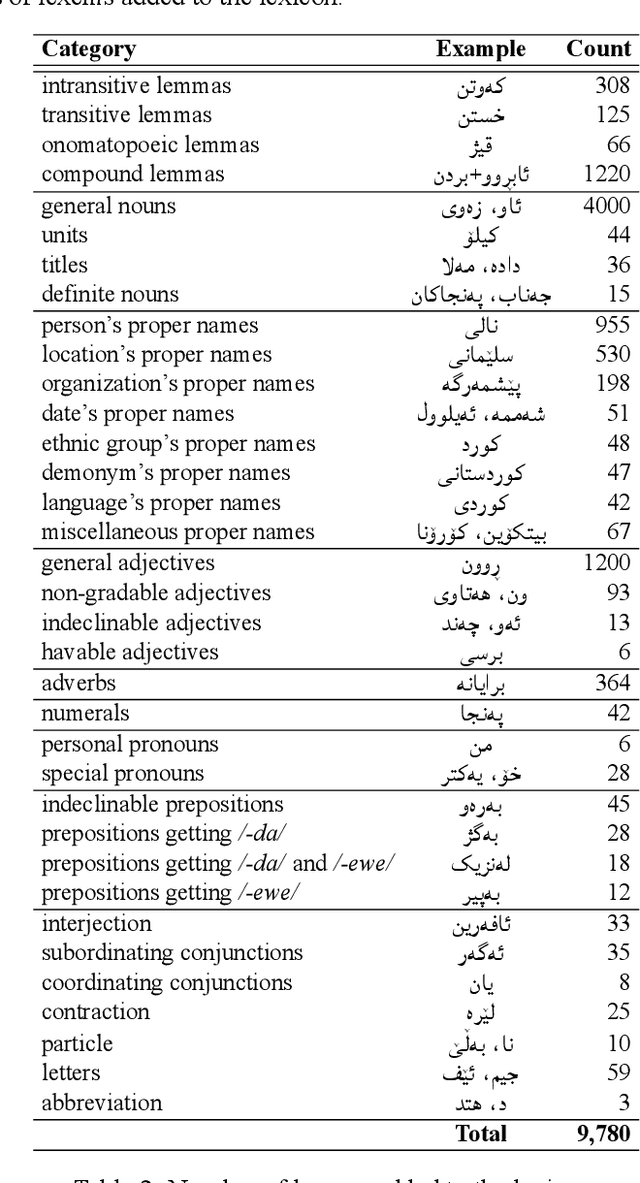
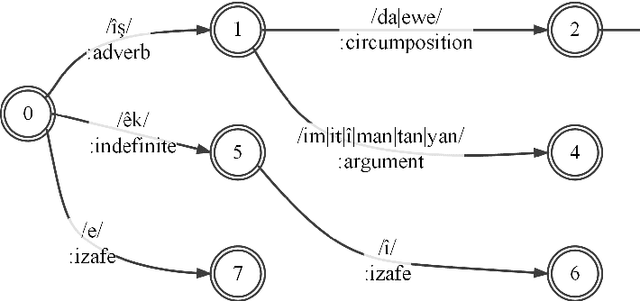
A morphological analyzer, which is a significant component of many natural language processing applications especially for morphologically rich languages, divides an input word into all its composing morphemes and identifies their morphological roles. In this paper, we introduce a comprehensive morphological analyzer for Central Kurdish (CK), a low-resourced language with a rich morphology. Building upon the limited existing literature, we first assembled and systematically categorized a comprehensive collection of the morphological and morphophonological rules of the language. Additionally, we collected and manually labeled a generative lexicon containing nearly 10,000 verb, noun and adjective stems, named entities, and other types of word stems. We used these rule sets and resources to implement CKMorph Analyzer based on finite-state transducers. In order to provide a benchmark for future research, we collected, manually labeled, and publicly shared test sets for evaluating accuracy and coverage of the analyzer. CKMorph was able to correctly analyze 95.9% of the accuracy test set, containing 1,000 CK words morphologically analyzed according to the context. Moreover, CKMorph gave at least one analysis for 95.5% of 4.22M CK tokens of the coverage test set. The demonstration of the application and resources including CK verb database and test sets are openly accessible at https://github.com/CKMorph.
Central Kurdish machine translation: First large scale parallel corpus and experiments
Jun 17, 2021
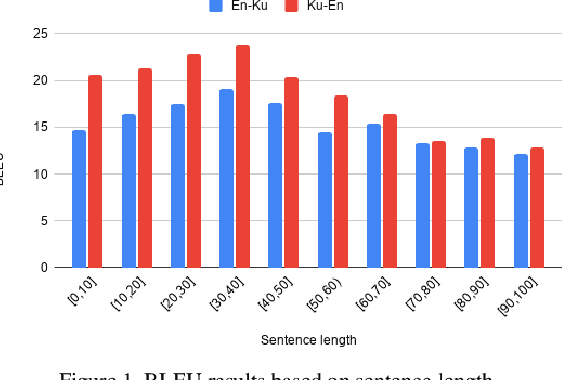
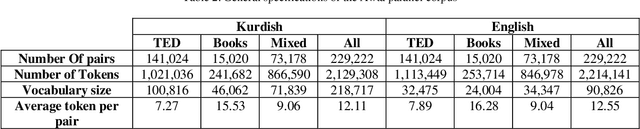
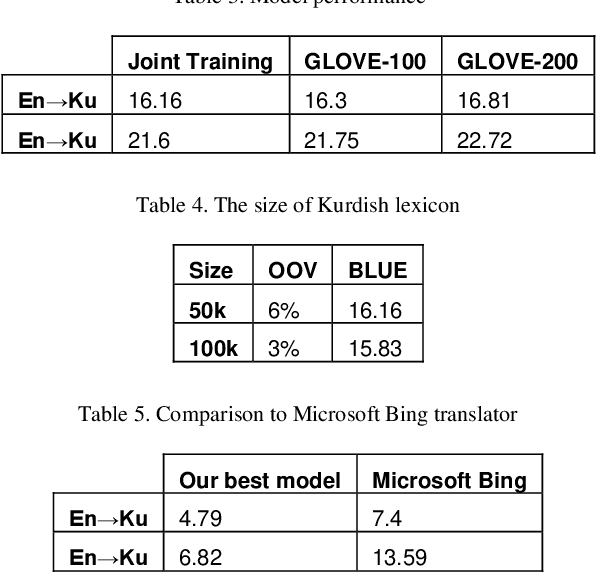
While the computational processing of Kurdish has experienced a relative increase, the machine translation of this language seems to be lacking a considerable body of scientific work. This is in part due to the lack of resources especially curated for this task. In this paper, we present the first large scale parallel corpus of Central Kurdish-English, Awta, containing 229,222 pairs of manually aligned translations. Our corpus is collected from different text genres and domains in an attempt to build more robust and real-world applications of machine translation. We make a portion of this corpus publicly available in order to foster research in this area. Further, we build several neural machine translation models in order to benchmark the task of Kurdish machine translation. Additionally, we perform extensive experimental analysis of results in order to identify the major challenges that Central Kurdish machine translation faces. These challenges include language-dependent and-independent ones as categorized in this paper, the first group of which are aware of Central Kurdish linguistic properties on different morphological, syntactic and semantic levels. Our best performing systems achieve 22.72 and 16.81 in BLEU score for Ku$\rightarrow$EN and En$\rightarrow$Ku, respectively.
Jira: a Kurdish Speech Recognition System Designing and Building Speech Corpus and Pronunciation Lexicon
Feb 15, 2021
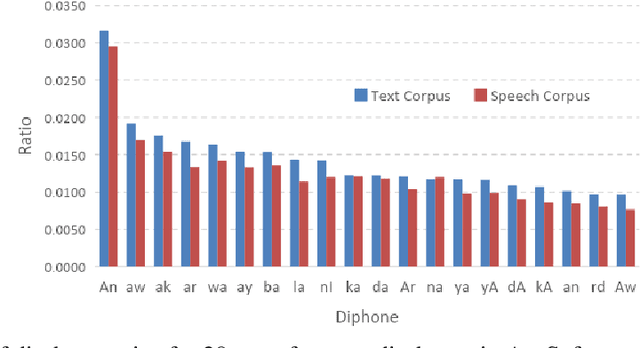

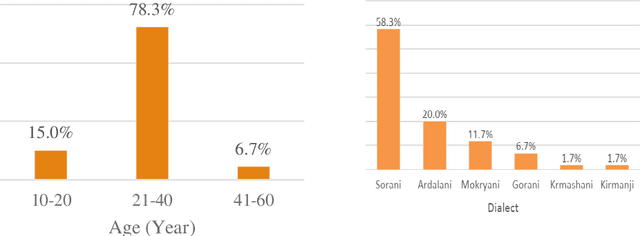
In this paper, we introduce the first large vocabulary speech recognition system (LVSR) for the Central Kurdish language, named Jira. The Kurdish language is an Indo-European language spoken by more than 30 million people in several countries, but due to the lack of speech and text resources, there is no speech recognition system for this language. To fill this gap, we introduce the first speech corpus and pronunciation lexicon for the Kurdish language. Regarding speech corpus, we designed a sentence collection in which the ratio of di-phones in the collection resembles the real data of the Central Kurdish language. The designed sentences are uttered by 576 speakers in a controlled environment with noise-free microphones (called AsoSoft Speech-Office) and in Telegram social network environment using mobile phones (denoted as AsoSoft Speech-Crowdsourcing), resulted in 43.68 hours of speech. Besides, a test set including 11 different document topics is designed and recorded in two corresponding speech conditions (i.e., Office and Crowdsourcing). Furthermore, a 60K pronunciation lexicon is prepared in this research in which we faced several challenges and proposed solutions for them. The Kurdish language has several dialects and sub-dialects that results in many lexical variations. Our methods for script standardization of lexical variations and automatic pronunciation of the lexicon tokens are presented in detail. To setup the recognition engine, we used the Kaldi toolkit. A statistical tri-gram language model that is extracted from the AsoSoft text corpus is used in the system. Several standard recipes including HMM-based models (i.e., mono, tri1, tr2, tri2, tri3), SGMM, and DNN methods are used to generate the acoustic model. These methods are trained with AsoSoft Speech-Office and AsoSoft Speech-Crowdsourcing and a combination of them. The best performance achieved by the SGMM acoustic model which results in 13.9% of the average word error rate (on different document topics) and 4.9% for the general topic.