 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Graph Transformers
Paper and Code
Apr 17, 2025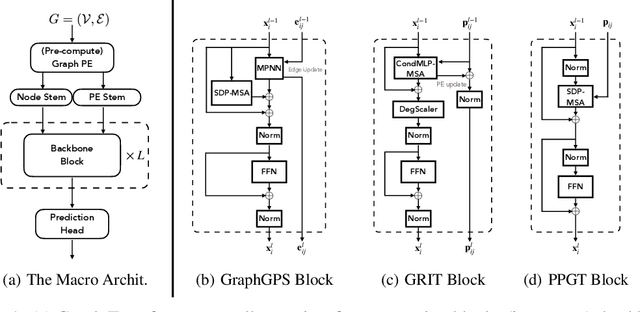
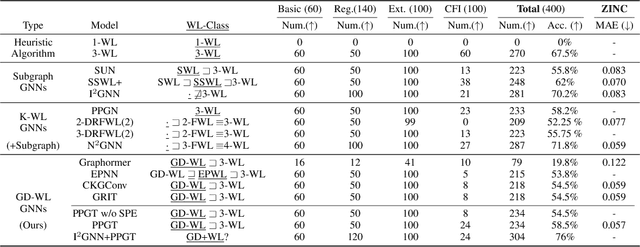
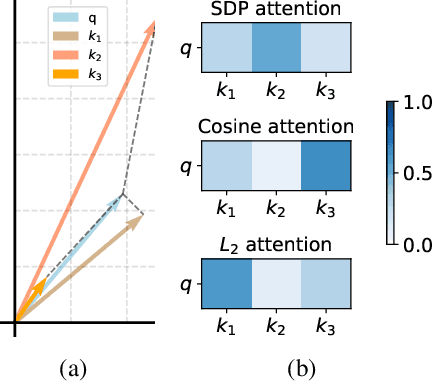
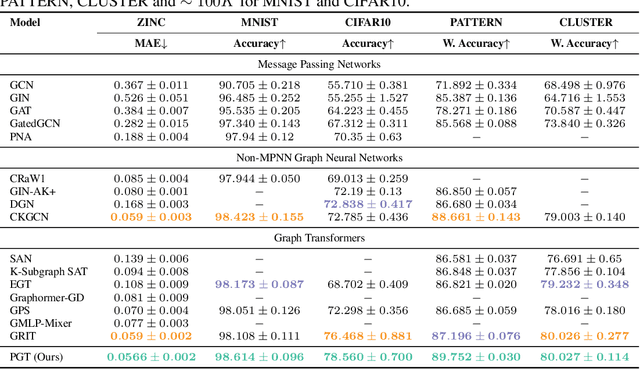
Transformers have attained outstanding performance across various modalities, employing scaled-dot-product (SDP) attention mechanisms. Researchers have attempted to migrate Transformers to graph learning, but most advanced Graph Transformers are designed with major architectural differences, either integrating message-passing or incorporating sophisticated attention mechanisms. These complexities prevent the easy adoption of Transformer training advances. We propose three simple modifications to the plain Transformer to render it applicable to graphs without introducing major architectural distortions. Specifically, we advocate for the use of (1) simplified $L_2$ attention to measure the magnitude closeness of tokens; (2) adaptive root-mean-square normalization to preserve token magnitude information; and (3) a relative positional encoding bias with a shared encoder. Significant performance gains across a variety of graph datasets justify the effectiveness of our proposed modifications. Furthermore, empirical evaluation on the expressiveness benchmark reveals noteworthy realized expressiveness in the graph isomorphism.