 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive 3D Shape Reconstruction from Vision and Touch
Jul 20, 2021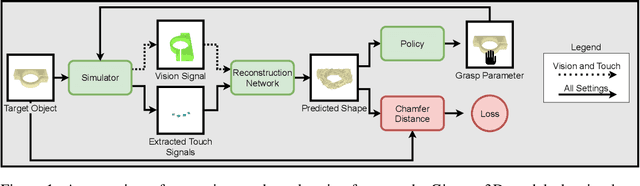
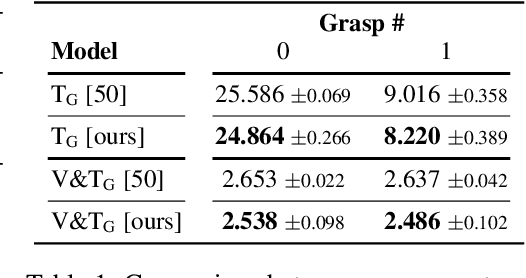
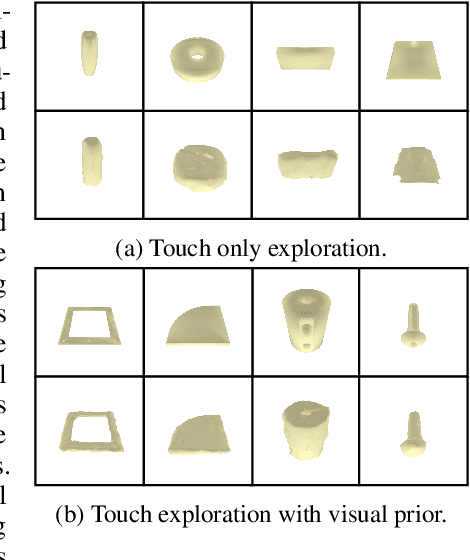
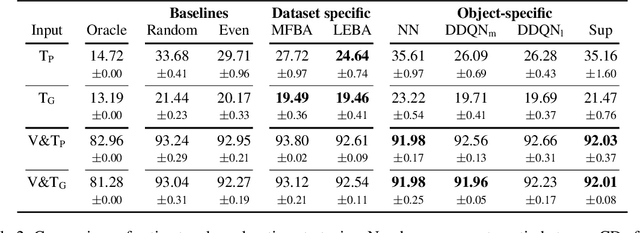
Humans build 3D understandings of the world through active object exploration, using jointly their senses of vision and touch. However, in 3D shape reconstruction, most recent progress has relied on static datasets of limited sensory data such as RGB images, depth maps or haptic readings, leaving the active exploration of the shape largely unexplored. In active touch sensing for 3D reconstruction, the goal is to actively select the tactile readings that maximize the improvement in shape reconstruction accuracy. However, the development of deep learning-based active touch models is largely limited by the lack of frameworks for shape exploration. In this paper, we focus on this problem and introduce a system composed of: 1) a haptic simulator leveraging high spatial resolution vision-based tactile sensors for active touching of 3D objects; 2) a mesh-based 3D shape reconstruction model that relies on tactile or visuotactile signals; and 3) a set of data-driven solutions with either tactile or visuotactile priors to guide the shape exploration. Our framework enables the development of the first fully data-driven solutions to active touch on top of learned models for object understanding. Our experiments show the benefits of such solutions in the task of 3D shape understanding where our models consistently outperform natural baselines. We provide our framework as a tool to foster future research in this direction.
Active MR k-space Sampling with Reinforcement Learning
Jul 20, 2020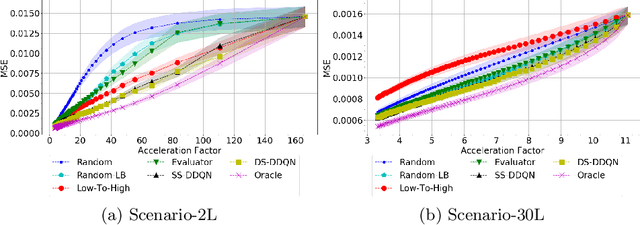
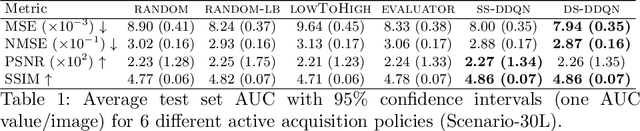
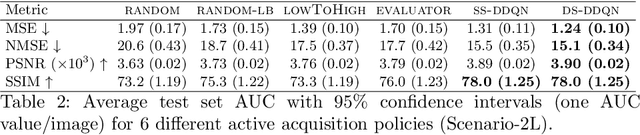
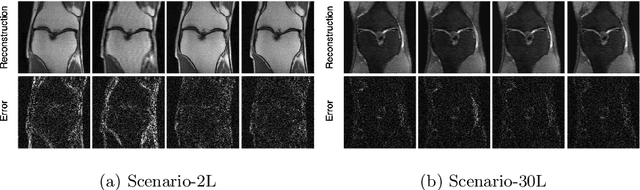
Deep learning approaches have recently shown great promise in accelerating magnetic resonance image (MRI) acquisition. The majority of existing work have focused on designing better reconstruction models given a pre-determined acquisition trajectory, ignoring the question of trajectory optimization. In this paper, we focus on learning acquisition trajectories given a fixed image reconstruction model. We formulate the problem as a sequential decision process and propose the use of reinforcement learning to solve it. Experiments on a large scale public MRI dataset of knees show that our proposed models significantly outperform the state-of-the-art in active MRI acquisition, over a large range of acceleration factors.
3D Shape Reconstruction from Vision and Touch
Jul 07, 2020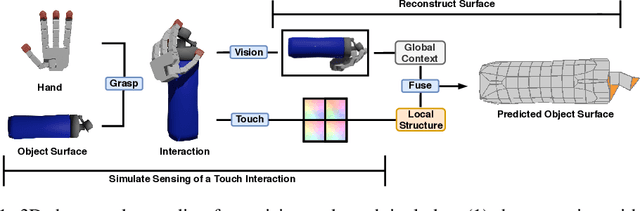

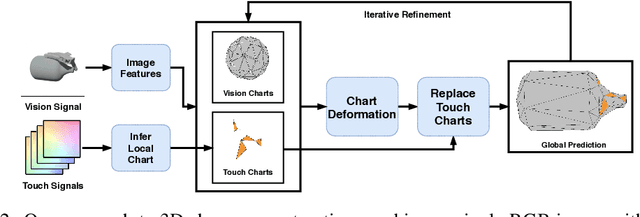

When a toddler is presented a new toy, their instinctual behaviour is to pick it up and inspect it with their hand and eyes in tandem, clearly searching over its surface to properly understand what they are playing with. Here, touch provides high fidelity localized information while vision provides complementary global context. However, in 3D shape reconstruction, the complementary fusion of visual and haptic modalities remains largely unexplored. In this paper, we study this problem and present an effective chart-based approach to fusing vision and touch, which leverages advances in graph convolutional networks. To do so, we introduce a dataset of simulated touch and vision signals from the interaction between a robotic hand and a large array of 3D objects. Our results show that (1) leveraging both vision and touch signals consistently improves single-modality baselines; (2) our approach outperforms alternative modality fusion methods and strongly benefits from the proposed chart-based structure; (3) the reconstruction quality increases with the number of grasps provided; and (4) the touch information not only enhances the reconstruction at the touch site but also extrapolates to its local neighborhood.
Learning to adapt class-specific features across domains for semantic segmentation
Jan 22, 2020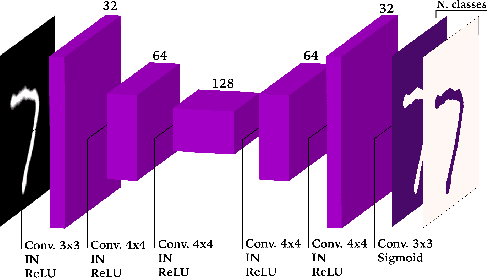


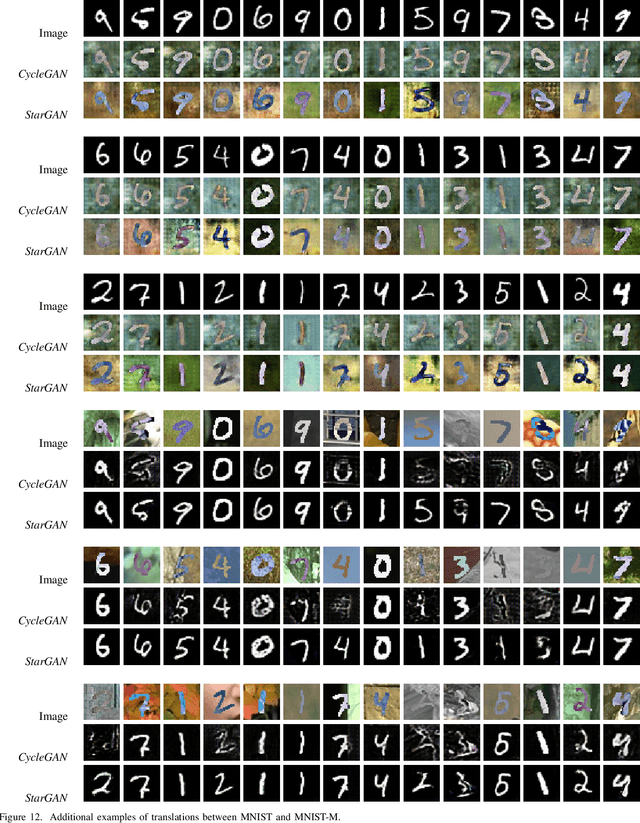
Recent advances in unsupervised domain adaptation have shown the effectiveness of adversarial training to adapt features across domains, endowing neural networks with the capability of being tested on a target domain without requiring any training annotations in this domain. The great majority of existing domain adaptation models rely on image translation networks, which often contain a huge amount of domain-specific parameters. Additionally, the feature adaptation step often happens globally, at a coarse level, hindering its applicability to tasks such as semantic segmentation, where details are of crucial importance to provide sharp results. In this thesis, we present a novel architecture, which learns to adapt features across domains by taking into account per class information. To that aim, we design a conditional pixel-wise discriminator network, whose output is conditioned on the segmentation masks. Moreover, following recent advances in image translation, we adopt the recently introduced StarGAN architecture as image translation backbone, since it is able to perform translations across multiple domains by means of a single generator network. Preliminary results on a segmentation task designed to assess the effectiveness of the proposed approach highlight the potential of the model, improving upon strong baselines and alternative designs.
On the Evaluation of Conditional GANs
Jul 11, 2019

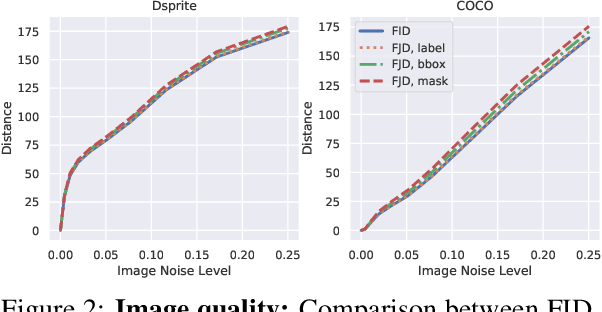
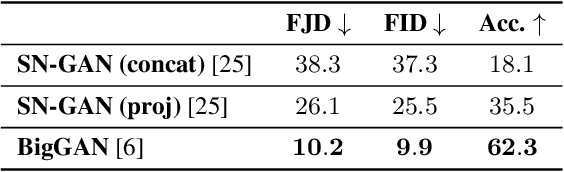
Conditional Generative Adversarial Networks (cGANs) are finding increasingly widespread use in many application domains. Despite outstanding progress, quantitative evaluation of such models often involves multiple distinct metrics to assess different desirable properties such as image quality, intra-conditioning diversity, and conditional consistency, making model benchmarking challenging. In this paper, we propose the Frechet Joint Distance (FJD), which implicitly captures the above mentioned properties in a single metric. FJD is defined as the Frechet Distance of the joint distribution of images and conditionings, making it less sensitive to the often limited per-conditioning sample size. As a result, it scales more gracefully to stronger forms of conditioning such as pixel-wise or multi-modal conditioning. We evaluate FJD on a modified version of the dSprite dataset as well as on the large scale COCO-Stuff dataset, and consistently highlight its benefits when compared to currently established metrics. Moreover, we use the newly introduced metric to compare existing cGAN-based models, with varying conditioning strengths, and show that FJD can be used as a promising single metric for model benchmarking.
Elucidating image-to-set prediction: An analysis of models, losses and datasets
Apr 11, 2019
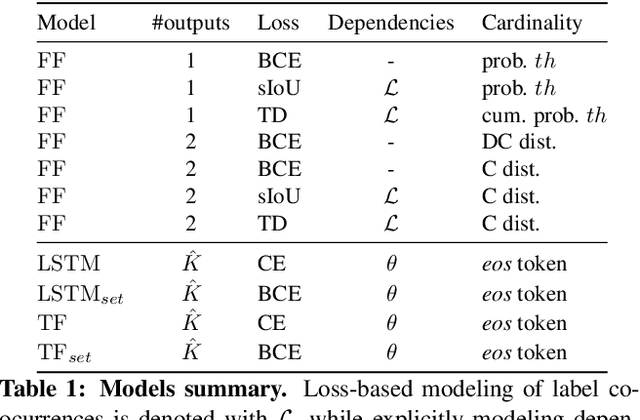
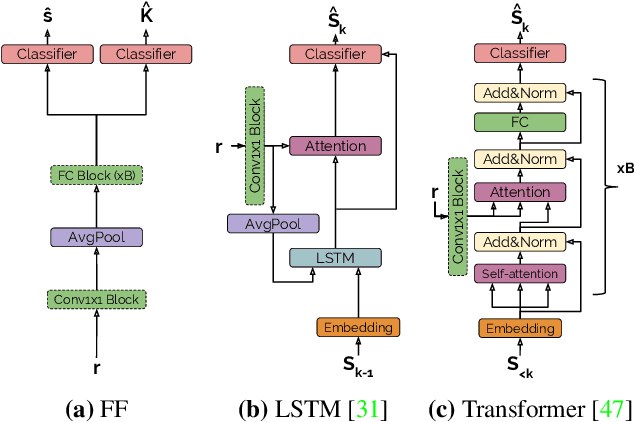

In recent years, we have experienced a flurry of contributions in the multi-label classification literature. This problem has been framed under different perspectives, from predicting independent labels, to modeling label co-occurrences via architectural and/or loss function design. Despite great progress, it is still unclear which modeling choices are best suited to address this task, partially due to the lack of well defined benchmarks. Therefore, in this paper, we provide an in-depth analysis on five different computer vision datasets of increasing task complexity that are suitable for multi-label clasification (VOC, COCO, NUS-WIDE, ADE20k and Recipe1M). Our results show that (1) modeling label co-occurrences and predicting the number of labels that appear in the image is important, especially in high-dimensional output spaces; (2) carefully tuning hyper-parameters for very simple baselines leads to significant improvements, comparable to previously reported results; and (3) as a consequence of our analysis, we achieve state-of-the-art results on 3 datasets for which a fair comparison to previously published methods is feasible.
Reducing Uncertainty in Undersampled MRI Reconstruction with Active Acquisition
Feb 08, 2019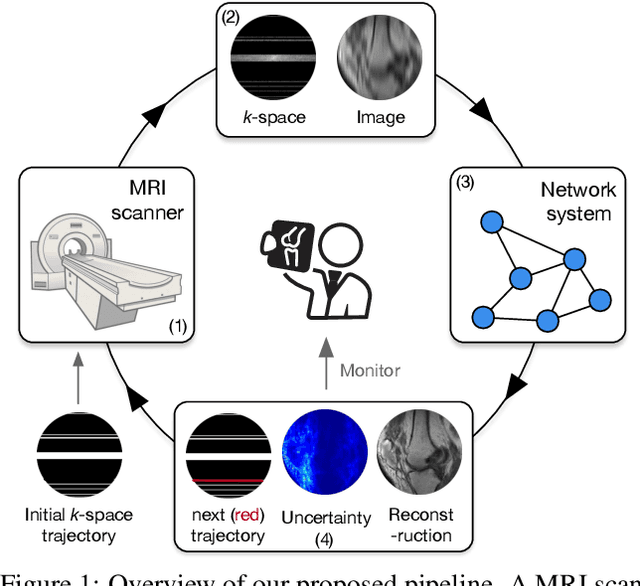
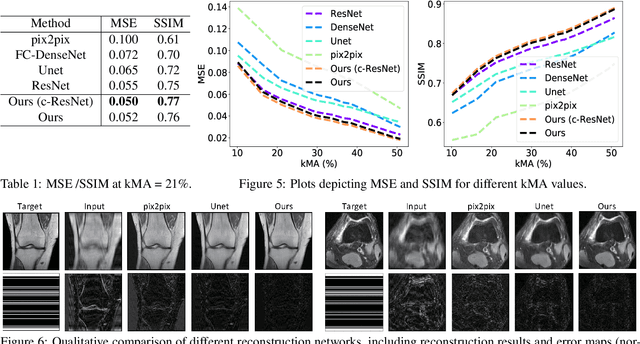
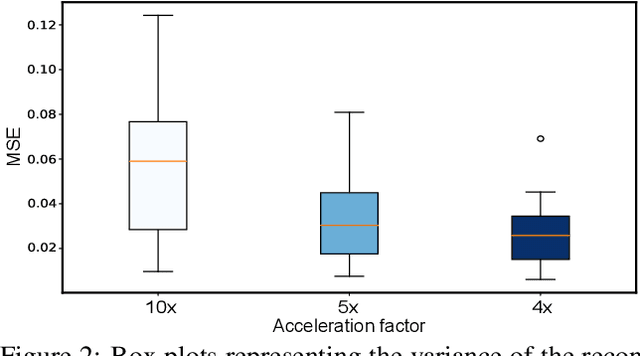
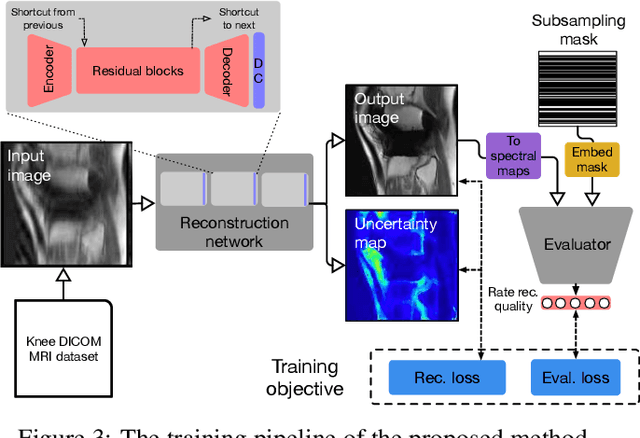
The goal of MRI reconstruction is to restore a high fidelity image from partially observed measurements. This partial view naturally induces reconstruction uncertainty that can only be reduced by acquiring additional measurements. In this paper, we present a novel method for MRI reconstruction that, at inference time, dynamically selects the measurements to take and iteratively refines the prediction in order to best reduce the reconstruction error and, thus, its uncertainty. We validate our method on a large scale knee MRI dataset, as well as on ImageNet. Results show that (1) our system successfully outperforms active acquisition baselines; (2) our uncertainty estimates correlate with error maps; and (3) our ResNet-based architecture surpasses standard pixel-to-pixel models in the task of MRI reconstruction. The proposed method not only shows high-quality reconstructions but also paves the road towards more applicable solutions for accelerating MRI.
GEOMetrics: Exploiting Geometric Structure for Graph-Encoded Objects
Jan 31, 2019
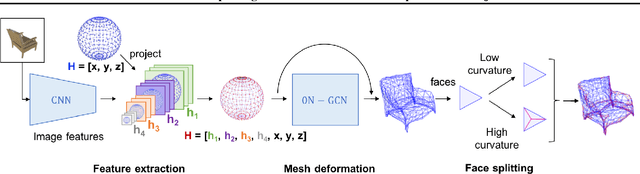

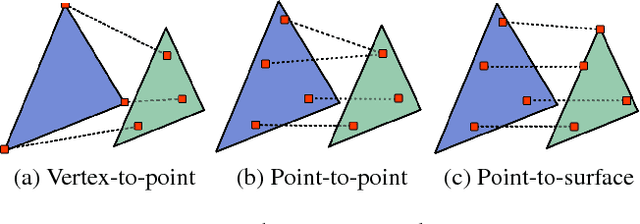
Mesh models are a promising approach for encoding the structure of 3D objects. Current mesh reconstruction systems predict uniformly distributed vertex locations of a predetermined graph through a series of graph convolutions, leading to compromises with respect to performance or resolution. In this paper, we argue that the graph representation of geometric objects allows for additional structure, which should be leveraged for enhanced reconstruction. Thus, we propose a system which properly benefits from the advantages of the geometric structure of graph encoded objects by introducing (1) a graph convolutional update preserving vertex information; (2) an adaptive splitting heuristic allowing detail to emerge; and (3) a training objective operating both on the local surfaces defined by vertices as well as the global structure defined by the mesh. Our proposed method is evaluated on the task of 3D object reconstruction from images with the ShapeNet dataset, where we demonstrate state of the art performance, both visually and numerically, while having far smaller space requirements by generating adaptive meshes
Inverse Cooking: Recipe Generation from Food Images
Dec 14, 2018



People enjoy food photography because they appreciate food. Behind each meal there is a story described in a complex recipe and, unfortunately, by simply looking at a food image we do not have access to its preparation process. Therefore, in this paper we introduce an inverse cooking system that recreates cooking recipes given food images. Our system predicts ingredients as sets by means of a novel architecture, modeling their dependencies without imposing any order, and then generates cooking instructions by attending to both image and its inferred ingredients simultaneously. We extensively evaluate the whole system on the large-scale Recipe1M dataset and show that (1) we improve performance w.r.t. previous baselines for ingredient prediction; (2) we are able to obtain high quality recipes by leveraging both image and ingredients; (3) our system is able to produce more compelling recipes than retrieval-based approaches according to human judgment.
fastMRI: An Open Dataset and Benchmarks for Accelerated MRI
Nov 21, 2018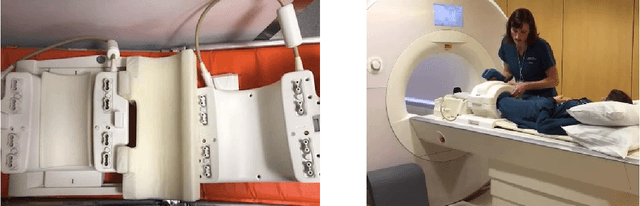
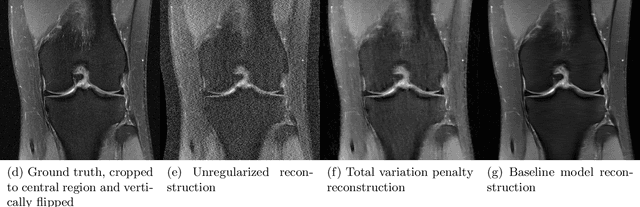
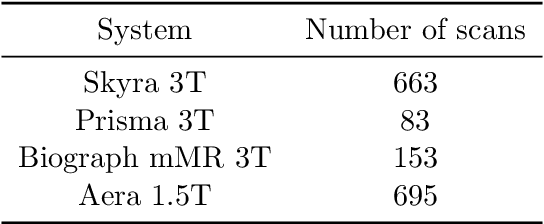
Accelerating Magnetic Resonance Imaging (MRI) by taking fewer measurements has the potential to reduce medical costs, minimize stress to patients and make MRI possible in applications where it is currently prohibitively slow or expensive. We introduce the fastMRI dataset, a large-scale collection of both raw MR measurements and clinical MR images, that can be used for training and evaluation of machine-learning approaches to MR image reconstruction. By introducing standardized evaluation criteria and a freely-accessible dataset, our goal is to help the community make rapid advances in the state of the art for MR image reconstruction. We also provide a self-contained introduction to MRI for machine learning researchers with no medical imaging background.