 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-incremental learning: survey and performance evaluation
Oct 28, 2020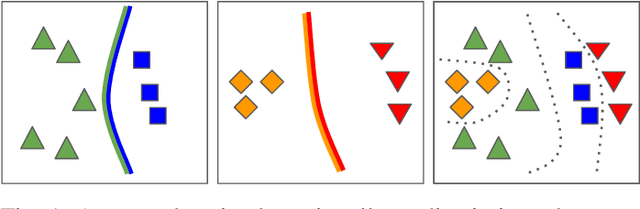
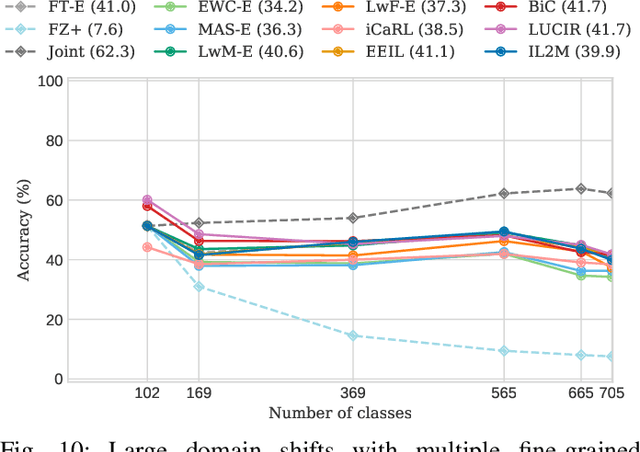
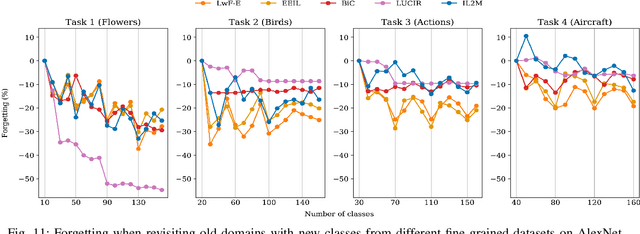
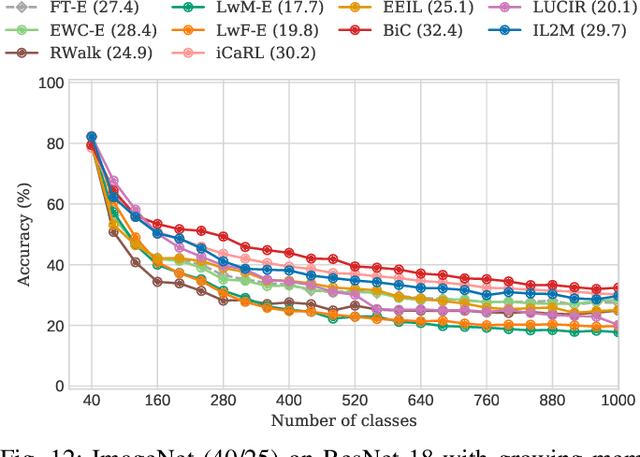
For future learning systems incremental learning is desirable, because it allows for: efficient resource usage by eliminating the need to retrain from scratch at the arrival of new data; reduced memory usage by preventing or limiting the amount of data required to be stored -- also important when privacy limitations are imposed; and learning that more closely resembles human learning. The main challenge for incremental learning is catastrophic forgetting, which refers to the precipitous drop in performance on previously learned tasks after learning a new one. Incremental learning of deep neural networks has seen explosive growth in recent years. Initial work focused on task incremental learning, where a task-ID is provided at inference time. Recently we have seen a shift towards class-incremental learning where the learner must classify at inference time between all classes seen in previous tasks without recourse to a task-ID. In this paper, we provide a complete survey of existing methods for incremental learning, and in particular we perform an extensive experimental evaluation on twelve class-incremental methods. We consider several new experimental scenarios, including a comparison of class-incremental methods on multiple large-scale datasets, investigation into small and large domain shifts, and comparison on various network architectures.
Generative Feature Replay For Class-Incremental Learning
Apr 20, 2020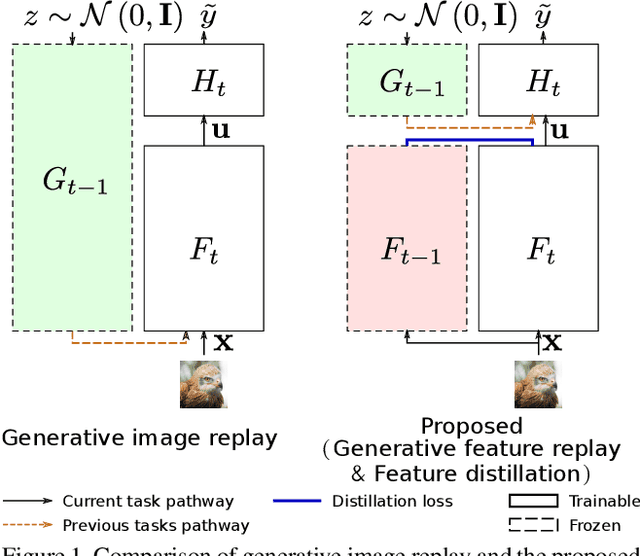

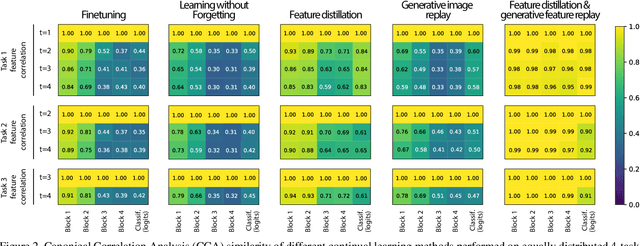
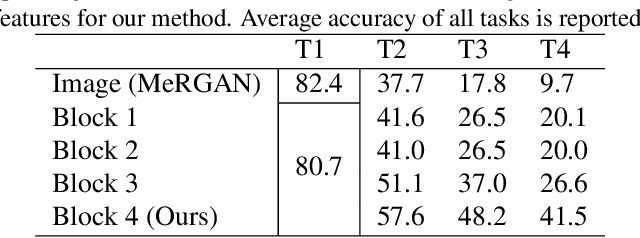
Humans are capable of learning new tasks without forgetting previous ones, while neural networks fail due to catastrophic forgetting between new and previously-learned tasks. We consider a class-incremental setting which means that the task-ID is unknown at inference time. The imbalance between old and new classes typically results in a bias of the network towards the newest ones. This imbalance problem can either be addressed by storing exemplars from previous tasks, or by using image replay methods. However, the latter can only be applied to toy datasets since image generation for complex datasets is a hard problem. We propose a solution to the imbalance problem based on generative feature replay which does not require any exemplars. To do this, we split the network into two parts: a feature extractor and a classifier. To prevent forgetting, we combine generative feature replay in the classifier with feature distillation in the feature extractor. Through feature generation, our method reduces the complexity of generative replay and prevents the imbalance problem. Our approach is computationally efficient and scalable to large datasets. Experiments confirm that our approach achieves state-of-the-art results on CIFAR-100 and ImageNet, while requiring only a fraction of the storage needed for exemplar-based continual learning. Code available at \url{https://github.com/xialeiliu/GFR-IL}.
Learning to adapt class-specific features across domains for semantic segmentation
Jan 22, 2020


Recent advances in unsupervised domain adaptation have shown the effectiveness of adversarial training to adapt features across domains, endowing neural networks with the capability of being tested on a target domain without requiring any training annotations in this domain. The great majority of existing domain adaptation models rely on image translation networks, which often contain a huge amount of domain-specific parameters. Additionally, the feature adaptation step often happens globally, at a coarse level, hindering its applicability to tasks such as semantic segmentation, where details are of crucial importance to provide sharp results. In this thesis, we present a novel architecture, which learns to adapt features across domains by taking into account per class information. To that aim, we design a conditional pixel-wise discriminator network, whose output is conditioned on the segmentation masks. Moreover, following recent advances in image translation, we adopt the recently introduced StarGAN architecture as image translation backbone, since it is able to perform translations across multiple domains by means of a single generator network. Preliminary results on a segmentation task designed to assess the effectiveness of the proposed approach highlight the potential of the model, improving upon strong baselines and alternative designs.