 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity Map Distillation for Incremental Object Counting
Apr 11, 2023We investigate the problem of incremental learning for object counting, where a method must learn to count a variety of object classes from a sequence of datasets. A na\"ive approach to incremental object counting would suffer from catastrophic forgetting, where it would suffer from a dramatic performance drop on previous tasks. In this paper, we propose a new exemplar-free functional regularization method, called Density Map Distillation (DMD). During training, we introduce a new counter head for each task and introduce a distillation loss to prevent forgetting of previous tasks. Additionally, we introduce a cross-task adaptor that projects the features of the current backbone to the previous backbone. This projector allows for the learning of new features while the backbone retains the relevant features for previous tasks. Finally, we set up experiments of incremental learning for counting new objects. Results confirm that our method greatly reduces catastrophic forgetting and outperforms existing methods.
Positive Pair Distillation Considered Harmful: Continual Meta Metric Learning for Lifelong Object Re-Identification
Oct 04, 2022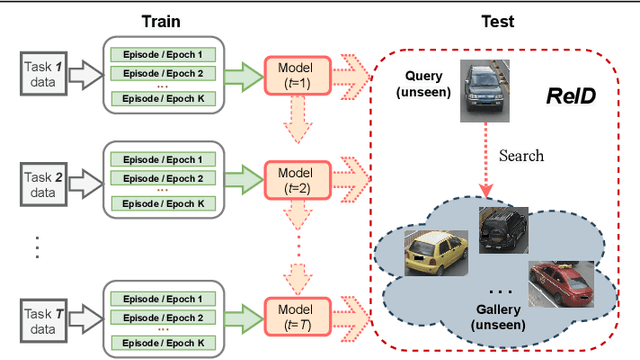
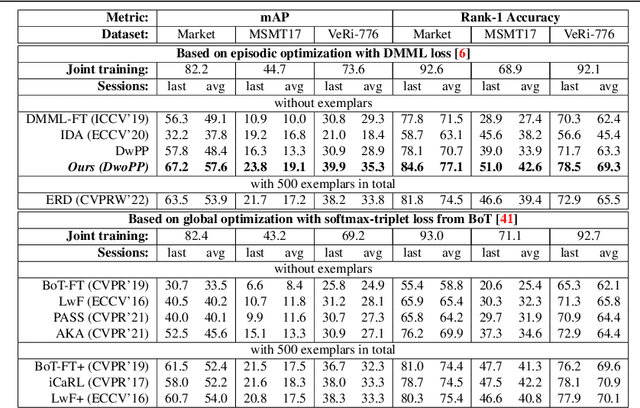
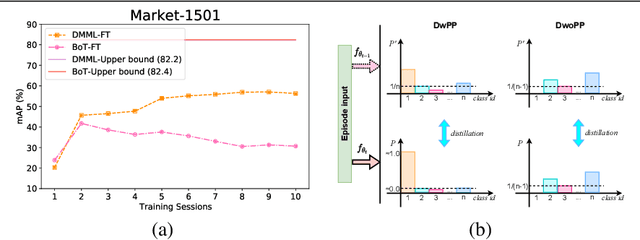

Lifelong object re-identification incrementally learns from a stream of re-identification tasks. The objective is to learn a representation that can be applied to all tasks and that generalizes to previously unseen re-identification tasks. The main challenge is that at inference time the representation must generalize to previously unseen identities. To address this problem, we apply continual meta metric learning to lifelong object re-identification. To prevent forgetting of previous tasks, we use knowledge distillation and explore the roles of positive and negative pairs. Based on our observation that the distillation and metric losses are antagonistic, we propose to remove positive pairs from distillation to robustify model updates. Our method, called Distillation without Positive Pairs (DwoPP), is evaluated on extensive intra-domain experiments on person and vehicle re-identification datasets, as well as inter-domain experiments on the LReID benchmark. Our experiments demonstrate that DwoPP significantly outperforms the state-of-the-art. The code is here: https://github.com/wangkai930418/DwoPP_code
MineGAN++: Mining Generative Models for Efficient Knowledge Transfer to Limited Data Domains
Apr 28, 2021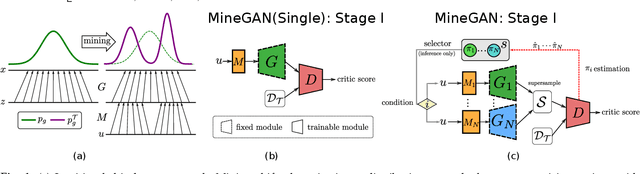
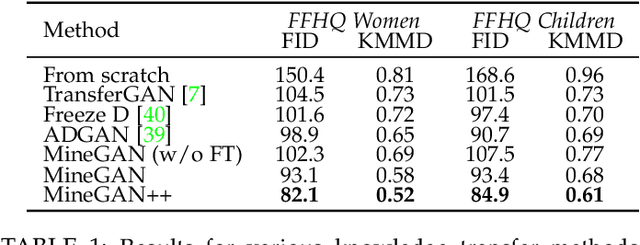
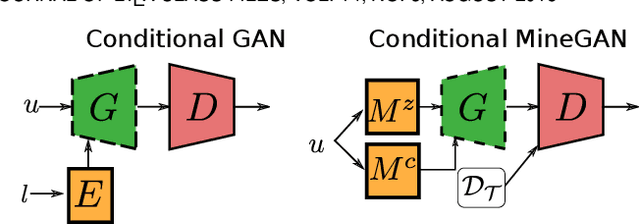

GANs largely increases the potential impact of generative models. Therefore, we propose a novel knowledge transfer method for generative models based on mining the knowledge that is most beneficial to a specific target domain, either from a single or multiple pretrained GANs. This is done using a miner network that identifies which part of the generative distribution of each pretrained GAN outputs samples closest to the target domain. Mining effectively steers GAN sampling towards suitable regions of the latent space, which facilitates the posterior finetuning and avoids pathologies of other methods, such as mode collapse and lack of flexibility. Furthermore, to prevent overfitting on small target domains, we introduce sparse subnetwork selection, that restricts the set of trainable neurons to those that are relevant for the target dataset. We perform comprehensive experiments on several challenging datasets using various GAN architectures (BigGAN, Progressive GAN, and StyleGAN) and show that the proposed method, called MineGAN, effectively transfers knowledge to domains with few target images, outperforming existing methods. In addition, MineGAN can successfully transfer knowledge from multiple pretrained GANs.
Generative Feature Replay For Class-Incremental Learning
Apr 20, 2020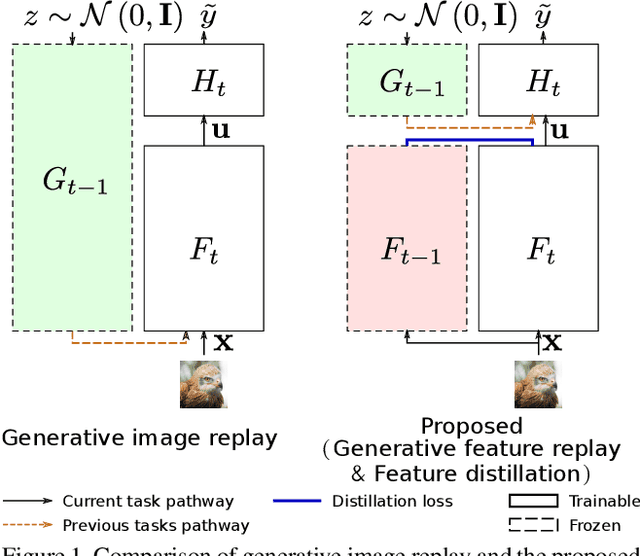

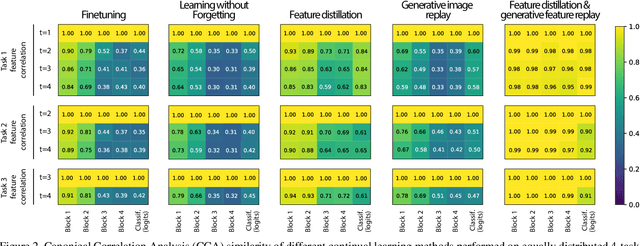
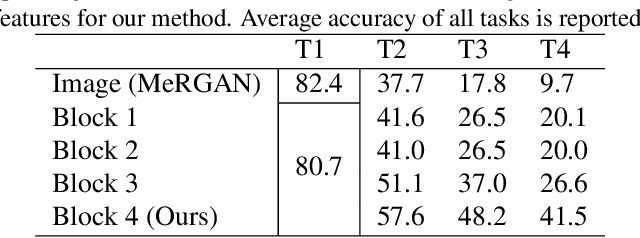
Humans are capable of learning new tasks without forgetting previous ones, while neural networks fail due to catastrophic forgetting between new and previously-learned tasks. We consider a class-incremental setting which means that the task-ID is unknown at inference time. The imbalance between old and new classes typically results in a bias of the network towards the newest ones. This imbalance problem can either be addressed by storing exemplars from previous tasks, or by using image replay methods. However, the latter can only be applied to toy datasets since image generation for complex datasets is a hard problem. We propose a solution to the imbalance problem based on generative feature replay which does not require any exemplars. To do this, we split the network into two parts: a feature extractor and a classifier. To prevent forgetting, we combine generative feature replay in the classifier with feature distillation in the feature extractor. Through feature generation, our method reduces the complexity of generative replay and prevents the imbalance problem. Our approach is computationally efficient and scalable to large datasets. Experiments confirm that our approach achieves state-of-the-art results on CIFAR-100 and ImageNet, while requiring only a fraction of the storage needed for exemplar-based continual learning. Code available at \url{https://github.com/xialeiliu/GFR-IL}.
Memory Replay GANs: learning to generate images from new categories without forgetting
Oct 29, 2018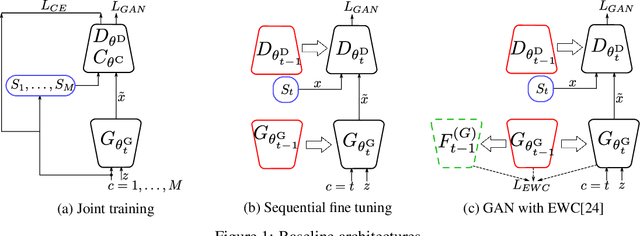

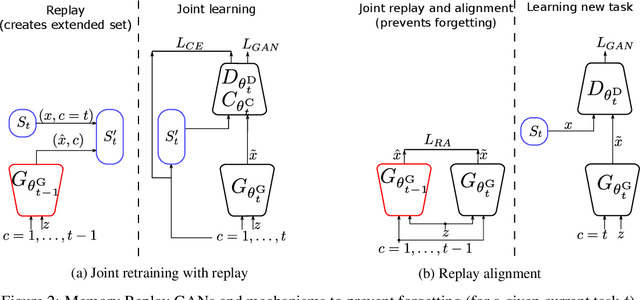

Previous works on sequential learning address the problem of forgetting in discriminative models. In this paper we consider the case of generative models. In particular, we investigate generative adversarial networks (GANs) in the task of learning new categories in a sequential fashion. We first show that sequential fine tuning renders the network unable to properly generate images from previous categories (i.e. forgetting). Addressing this problem, we propose Memory Replay GANs (MeRGANs), a conditional GAN framework that integrates a memory replay generator. We study two methods to prevent forgetting by leveraging these replays, namely joint training with replay and replay alignment. Qualitative and quantitative experimental results in MNIST, SVHN and LSUN datasets show that our memory replay approach can generate competitive images while significantly mitigating the forgetting of previous categories.
Transferring GANs: generating images from limited data
Oct 02, 2018


Transferring the knowledge of pretrained networks to new domains by means of finetuning is a widely used practice for applications based on discriminative models. To the best of our knowledge this practice has not been studied within the context of generative deep networks. Therefore, we study domain adaptation applied to image generation with generative adversarial networks. We evaluate several aspects of domain adaptation, including the impact of target domain size, the relative distance between source and target domain, and the initialization of conditional GANs. Our results show that using knowledge from pretrained networks can shorten the convergence time and can significantly improve the quality of the generated images, especially when the target data is limited. We show that these conclusions can also be drawn for conditional GANs even when the pretrained model was trained without conditioning. Our results also suggest that density may be more important than diversity and a dataset with one or few densely sampled classes may be a better source model than more diverse datasets such as ImageNet or Places.