 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Cross-Modal Distillation for Thermal Infrared Tracking
Jul 31, 2021
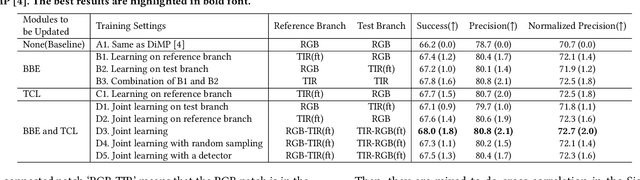
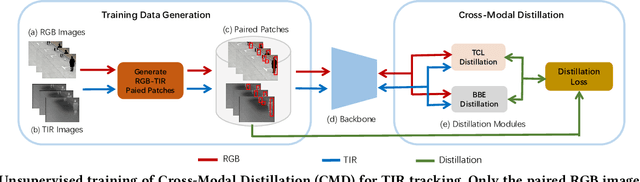
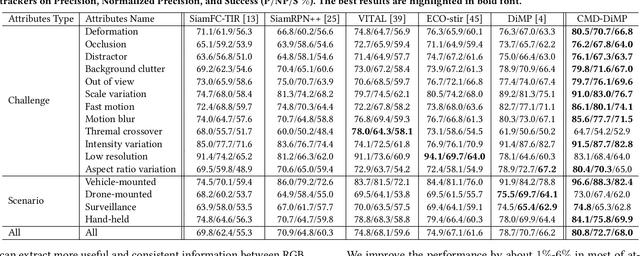
The target representation learned by convolutional neural networks plays an important role in Thermal Infrared (TIR) tracking. Currently, most of the top-performing TIR trackers are still employing representations learned by the model trained on the RGB data. However, this representation does not take into account the information in the TIR modality itself, limiting the performance of TIR tracking. To solve this problem, we propose to distill representations of the TIR modality from the RGB modality with Cross-Modal Distillation (CMD) on a large amount of unlabeled paired RGB-TIR data. We take advantage of the two-branch architecture of the baseline tracker, i.e. DiMP, for cross-modal distillation working on two components of the tracker. Specifically, we use one branch as a teacher module to distill the representation learned by the model into the other branch. Benefiting from the powerful model in the RGB modality, the cross-modal distillation can learn the TIR-specific representation for promoting TIR tracking. The proposed approach can be incorporated into different baseline trackers conveniently as a generic and independent component. Furthermore, the semantic coherence of paired RGB and TIR images is utilized as a supervised signal in the distillation loss for cross-modal knowledge transfer. In practice, three different approaches are explored to generate paired RGB-TIR patches with the same semantics for training in an unsupervised way. It is easy to extend to an even larger scale of unlabeled training data. Extensive experiments on the LSOTB-TIR dataset and PTB-TIR dataset demonstrate that our proposed cross-modal distillation method effectively learns TIR-specific target representations transferred from the RGB modality. Our tracker outperforms the baseline tracker by achieving absolute gains of 2.3% Success, 2.7% Precision, and 2.5% Normalized Precision respectively.
MineGAN++: Mining Generative Models for Efficient Knowledge Transfer to Limited Data Domains
Apr 28, 2021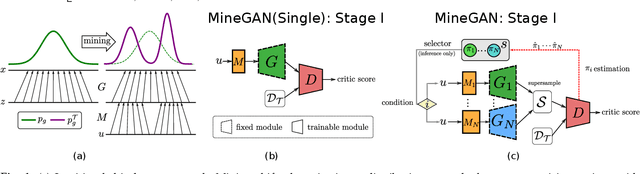
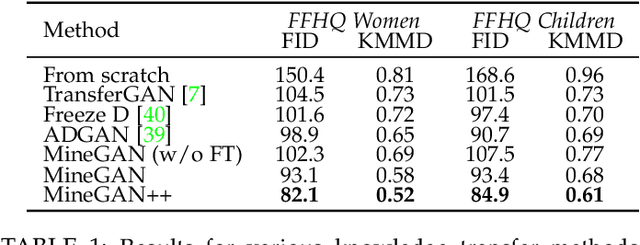
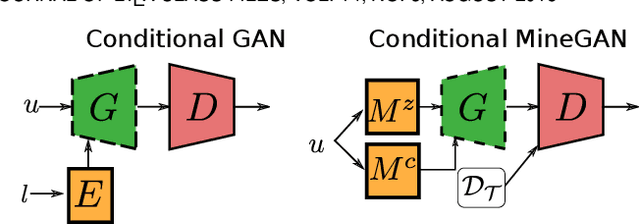

GANs largely increases the potential impact of generative models. Therefore, we propose a novel knowledge transfer method for generative models based on mining the knowledge that is most beneficial to a specific target domain, either from a single or multiple pretrained GANs. This is done using a miner network that identifies which part of the generative distribution of each pretrained GAN outputs samples closest to the target domain. Mining effectively steers GAN sampling towards suitable regions of the latent space, which facilitates the posterior finetuning and avoids pathologies of other methods, such as mode collapse and lack of flexibility. Furthermore, to prevent overfitting on small target domains, we introduce sparse subnetwork selection, that restricts the set of trainable neurons to those that are relevant for the target dataset. We perform comprehensive experiments on several challenging datasets using various GAN architectures (BigGAN, Progressive GAN, and StyleGAN) and show that the proposed method, called MineGAN, effectively transfers knowledge to domains with few target images, outperforming existing methods. In addition, MineGAN can successfully transfer knowledge from multiple pretrained GANs.
Semi-supervised Learning for Few-shot Image-to-Image Translation
Apr 02, 2020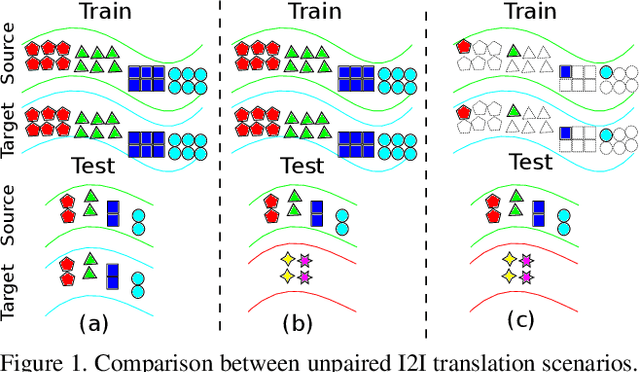
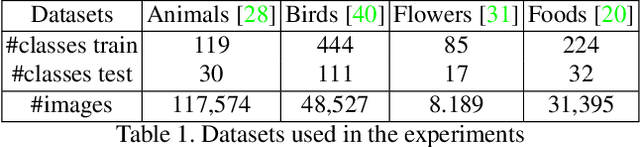
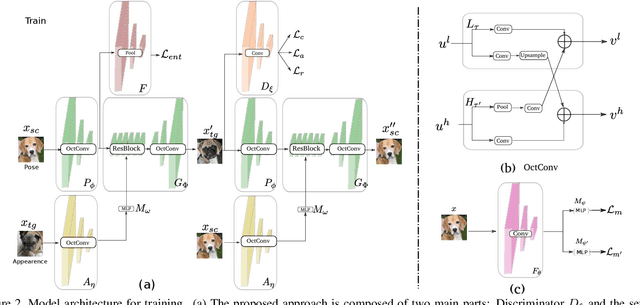
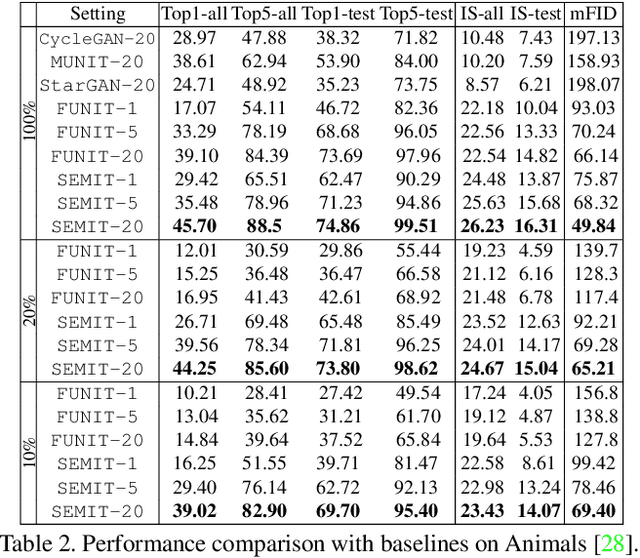
In the last few years, unpaired image-to-image translation has witnessed remarkable progress. Although the latest methods are able to generate realistic images, they crucially rely on a large number of labeled images. Recently, some methods have tackled the challenging setting of few-shot image-to-image translation, reducing the labeled data requirements for the target domain during inference. In this work, we go one step further and reduce the amount of required labeled data also from the source domain during training. To do so, we propose applying semi-supervised learning via a noise-tolerant pseudo-labeling procedure. We also apply a cycle consistency constraint to further exploit the information from unlabeled images, either from the same dataset or external. Additionally, we propose several structural modifications to facilitate the image translation task under these circumstances. Our semi-supervised method for few-shot image translation, called SEMIT, achieves excellent results on four different datasets using as little as 10% of the source labels, and matches the performance of the main fully-supervised competitor using only 20% labeled data. Our code and models are made public at: https://github.com/yaxingwang/SEMIT.
MineGAN: effective knowledge transfer from GANs to target domains with few images
Dec 11, 2019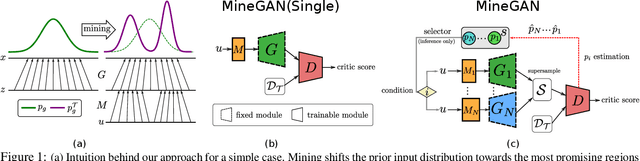

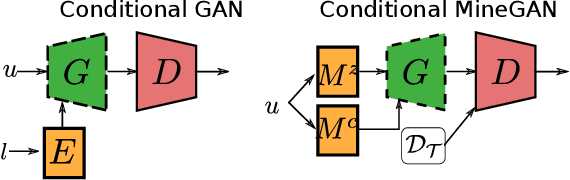
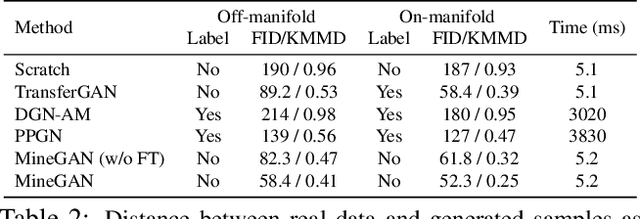
One of the attractive characteristics of deep neural networks is their ability to transfer knowledge obtained in one domain to other related domains. As a result, high-quality networks can be trained in domains with relatively little training data. This property has been extensively studied for discriminative networks but has received significantly less attention for generative models.Given the often enormous effort required to train GANs, both computationally as well as in the dataset collection, the re-use of pretrained GANs is a desirable objective. We propose a novel knowledge transfer method for generative models based on mining the knowledge that is most beneficial to a specific target domain, either from a single or multiple pretrained GANs. This is done using a miner network that identifies which part of the generative distribution of each pretrained GAN outputs samples closest to the target domain. Mining effectively steers GAN sampling towards suitable regions of the latent space, which facilitates the posterior finetuning and avoids pathologies of other methods such as mode collapse and lack of flexibility. We perform experiments on several complex datasets using various GAN architectures (BigGAN, Progressive GAN) and show that the proposed method, called MineGAN, effectively transfers knowledge to domains with few target images, outperforming existing methods. In addition, MineGAN can successfully transfer knowledge from multiple pretrained GANs.
Orderless Recurrent Models for Multi-label Classification
Nov 25, 2019
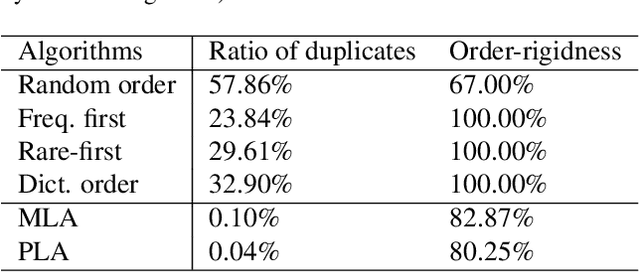
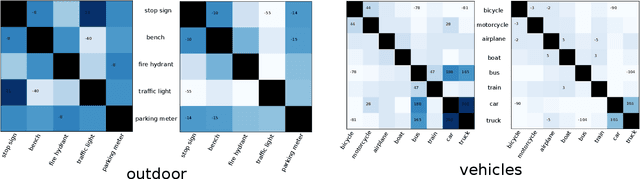
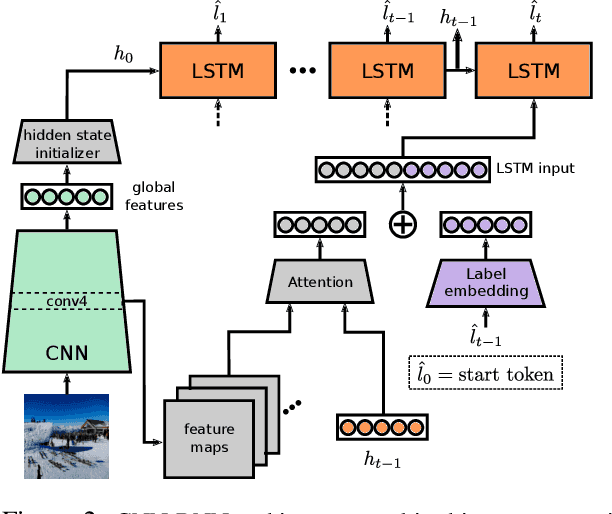
Recurrent neural networks (RNN) are popular for many computer vision tasks, including multi-label classification. Since RNNs produce sequential outputs, labels need to be ordered for the multi-label classification task. Current approaches sort labels according to their frequency, typically ordering them in either rare-first or frequent-first. These imposed orderings do not take into account that the natural order to generate the labels can change for each image, e.g.\ first the dominant object before summing up the smaller objects in the image. Therefore, in this paper, we propose ways to dynamically order the ground truth labels with the predicted label sequence. This allows for the faster training of more optimal LSTM models for multi-label classification. Analysis evidences that our method does not suffer from duplicate generation, something which is common for other models. Furthermore, it outperforms other CNN-RNN models, and we show that a standard architecture of an image encoder and language decoder trained with our proposed loss obtains the state-of-the-art results on the challenging MS-COCO, WIDER Attribute and PA-100K and competitive results on NUS-WIDE.
Active Learning for Deep Detection Neural Networks
Nov 20, 2019

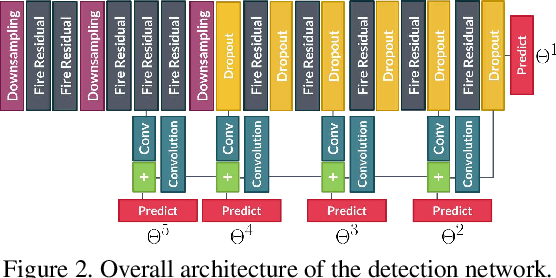
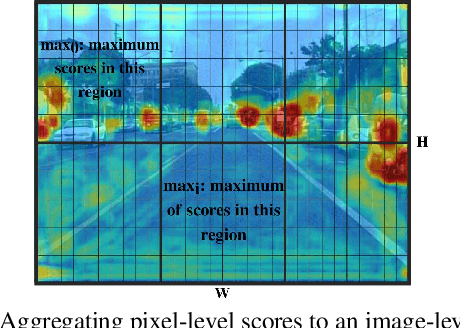
The cost of drawing object bounding boxes (i.e. labeling) for millions of images is prohibitively high. For instance, labeling pedestrians in a regular urban image could take 35 seconds on average. Active learning aims to reduce the cost of labeling by selecting only those images that are informative to improve the detection network accuracy. In this paper, we propose a method to perform active learning of object detectors based on convolutional neural networks. We propose a new image-level scoring process to rank unlabeled images for their automatic selection, which clearly outperforms classical scores. The proposed method can be applied to videos and sets of still images. In the former case, temporal selection rules can complement our scoring process. As a relevant use case, we extensively study the performance of our method on the task of pedestrian detection. Overall, the experiments show that the proposed method performs better than random selection. Our codes are publicly available at www.gitlab.com/haghdam/deep_active_learning.
Learning the Model Update for Siamese Trackers
Sep 06, 2019
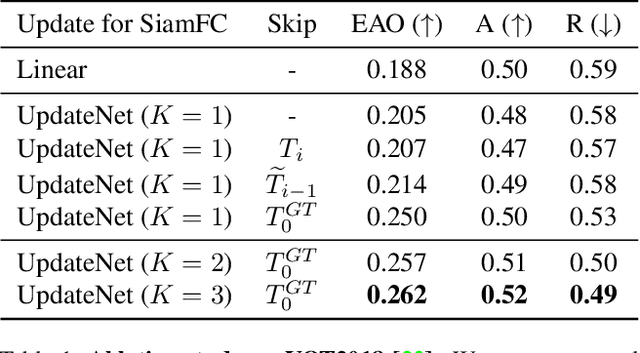
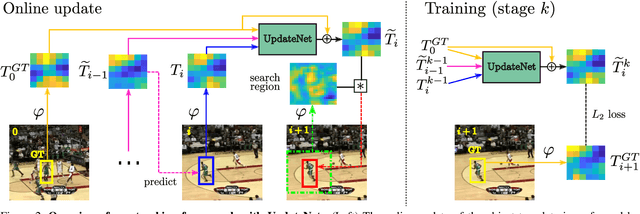
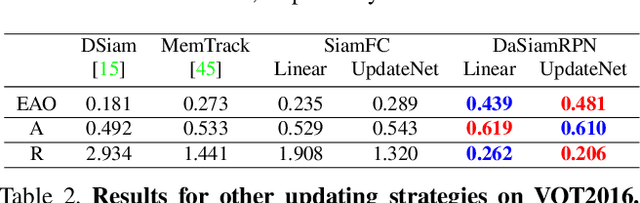
Siamese approaches address the visual tracking problem by extracting an appearance template from the current frame, which is used to localize the target in the next frame. In general, this template is linearly combined with the accumulated template from the previous frame, resulting in an exponential decay of information over time. While such an approach to updating has led to improved results, its simplicity limits the potential gain likely to be obtained by learning to update. Therefore, we propose to replace the handcrafted update function with a method which learns to update. We use a convolutional neural network, called UpdateNet, which given the initial template, the accumulated template and the template of the current frame aims to estimate the optimal template for the next frame. The UpdateNet is compact and can easily be integrated into existing Siamese trackers. We demonstrate the generality of the proposed approach by applying it to two Siamese trackers, SiamFC and DaSiamRPN. Extensive experiments on VOT2016, VOT2018, LaSOT, and TrackingNet datasets demonstrate that our UpdateNet effectively predicts the new target template, outperforming the standard linear update. On the large-scale TrackingNet dataset, our UpdateNet improves the results of DaSiamRPN with an absolute gain of 3.9% in terms of success score.
Temporal Coherence for Active Learning in Videos
Aug 30, 2019
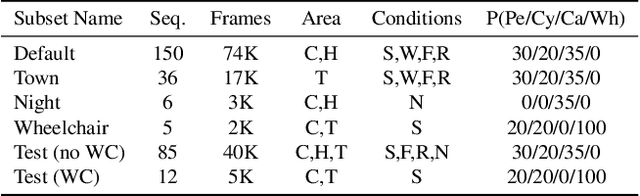
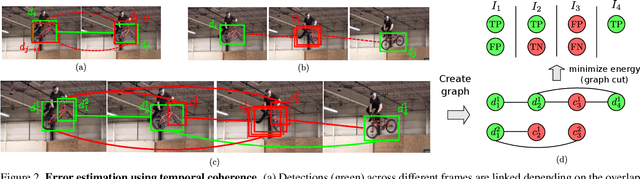
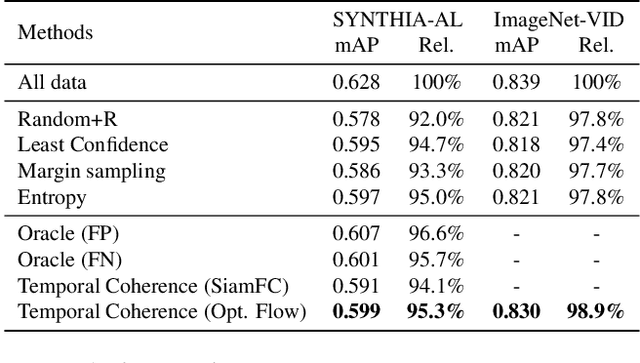
Autonomous driving systems require huge amounts of data to train. Manual annotation of this data is time-consuming and prohibitively expensive since it involves human resources. Therefore, active learning emerged as an alternative to ease this effort and to make data annotation more manageable. In this paper, we introduce a novel active learning approach for object detection in videos by exploiting temporal coherence. Our active learning criterion is based on the estimated number of errors in terms of false positives and false negatives. The detections obtained by the object detector are used to define the nodes of a graph and tracked forward and backward to temporally link the nodes. Minimizing an energy function defined on this graphical model provides estimates of both false positives and false negatives. Additionally, we introduce a synthetic video dataset, called SYNTHIA-AL, specially designed to evaluate active learning for video object detection in road scenes. Finally, we show that our approach outperforms active learning baselines tested on two datasets.
Multi-Modal Fusion for End-to-End RGB-T Tracking
Aug 30, 2019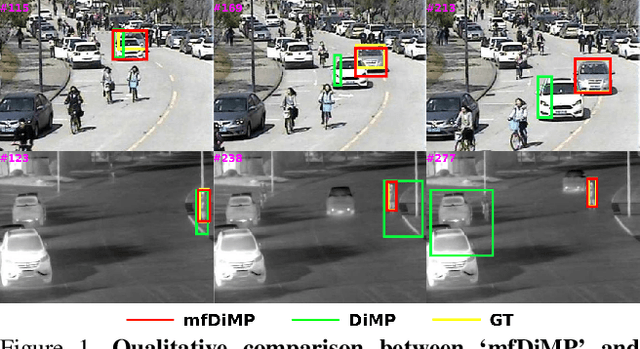
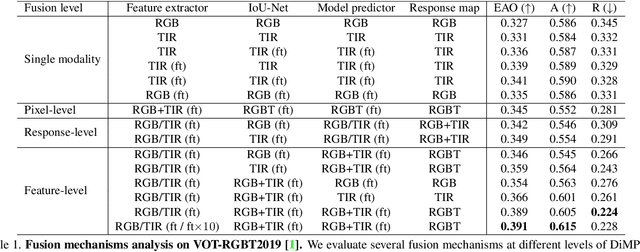
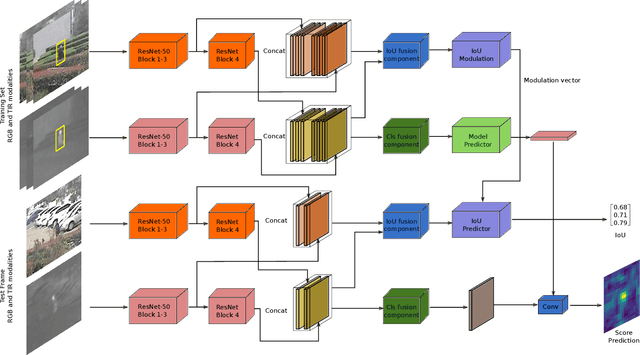
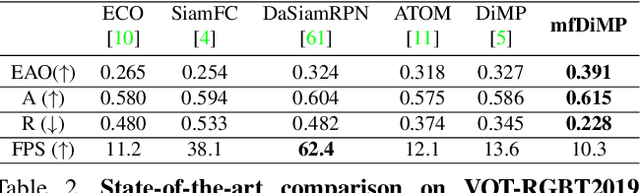
We propose an end-to-end tracking framework for fusing the RGB and TIR modalities in RGB-T tracking. Our baseline tracker is DiMP (Discriminative Model Prediction), which employs a carefully designed target prediction network trained end-to-end using a discriminative loss. We analyze the effectiveness of modality fusion in each of the main components in DiMP, i.e. feature extractor, target estimation network, and classifier. We consider several fusion mechanisms acting at different levels of the framework, including pixel-level, feature-level and response-level. Our tracker is trained in an end-to-end manner, enabling the components to learn how to fuse the information from both modalities. As data to train our model, we generate a large-scale RGB-T dataset by considering an annotated RGB tracking dataset (GOT-10k) and synthesizing paired TIR images using an image-to-image translation approach. We perform extensive experiments on VOT-RGBT2019 dataset and RGBT210 dataset, evaluating each type of modality fusing on each model component. The results show that the proposed fusion mechanisms improve the performance of the single modality counterparts. We obtain our best results when fusing at the feature-level on both the IoU-Net and the model predictor, obtaining an EAO score of 0.391 on VOT-RGBT2019 dataset. With this fusion mechanism we achieve the state-of-the-art performance on RGBT210 dataset.
SDIT: Scalable and Diverse Cross-domain Image Translation
Aug 19, 2019
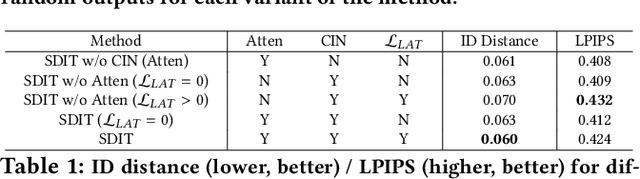
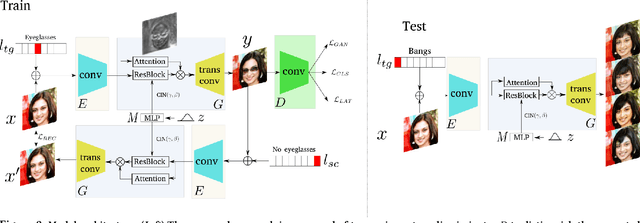

Recently, image-to-image translation research has witnessed remarkable progress. Although current approaches successfully generate diverse outputs or perform scalable image transfer, these properties have not been combined into a single method. To address this limitation, we propose SDIT: Scalable and Diverse image-to-image translation. These properties are combined into a single generator. The diversity is determined by a latent variable which is randomly sampled from a normal distribution. The scalability is obtained by conditioning the network on the domain attributes. Additionally, we also exploit an attention mechanism that permits the generator to focus on the domain-specific attribute. We empirically demonstrate the performance of the proposed method on face mapping and other datasets beyond faces.