 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDIT: Scalable and Diverse Cross-domain Image Translation
Paper and Code

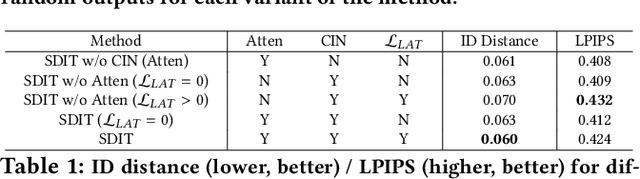
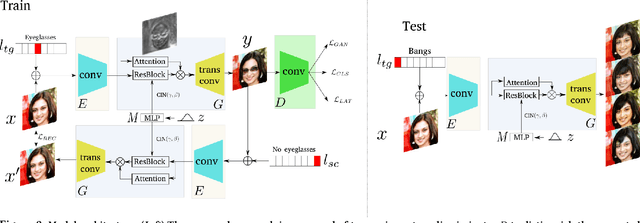

Recently, image-to-image translation research has witnessed remarkable progress. Although current approaches successfully generate diverse outputs or perform scalable image transfer, these properties have not been combined into a single method. To address this limitation, we propose SDIT: Scalable and Diverse image-to-image translation. These properties are combined into a single generator. The diversity is determined by a latent variable which is randomly sampled from a normal distribution. The scalability is obtained by conditioning the network on the domain attributes. Additionally, we also exploit an attention mechanism that permits the generator to focus on the domain-specific attribute. We empirically demonstrate the performance of the proposed method on face mapping and other datasets beyond faces.