 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework for Image-to-image Translation and Image Compression
Nov 25, 2021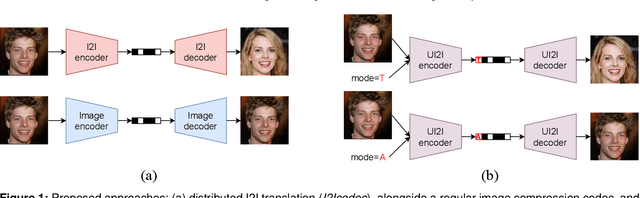
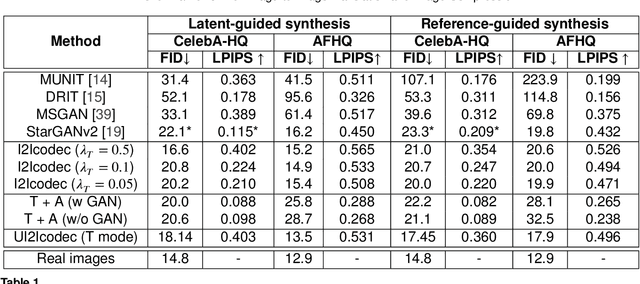


Data-driven paradigms using machine learning are becoming ubiquitous in image processing and communications. In particular, image-to-image (I2I) translation is a generic and widely used approach to image processing problems, such as image synthesis, style transfer, and image restoration. At the same time, neural image compression has emerged as a data-driven alternative to traditional coding approaches in visual communications. In this paper, we study the combination of these two paradigms into a joint I2I compression and translation framework, focusing on multi-domain image synthesis. We first propose distributed I2I translation by integrating quantization and entropy coding into an I2I translation framework (i.e. I2Icodec). In practice, the image compression functionality (i.e. autoencoding) is also desirable, requiring to deploy alongside I2Icodec a regular image codec. Thus, we further propose a unified framework that allows both translation and autoencoding capabilities in a single codec. Adaptive residual blocks conditioned on the translation/compression mode provide flexible adaptation to the desired functionality. The experiments show promising results in both I2I translation and image compression using a single model.
Variable Rate Deep Image Compression with Modulated Autoencoder
Dec 11, 2019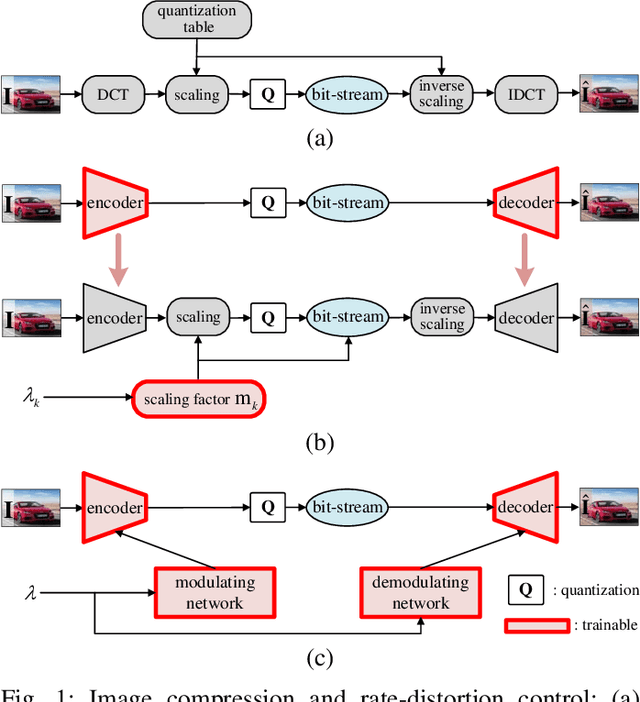

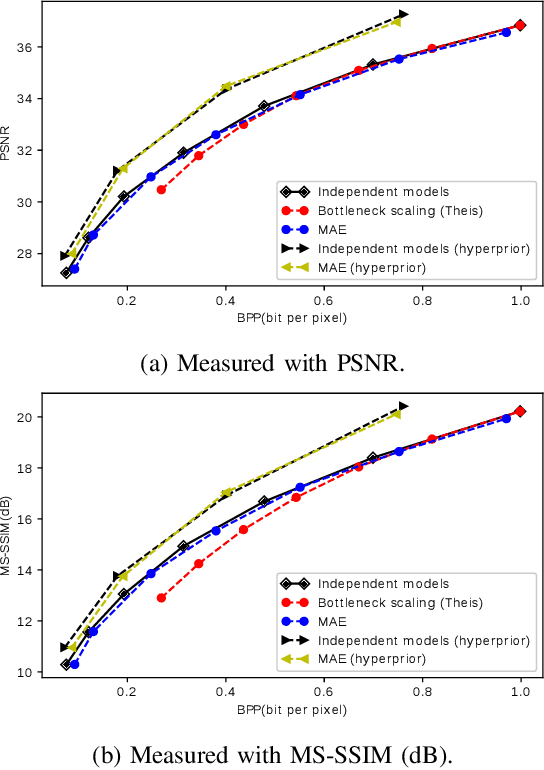
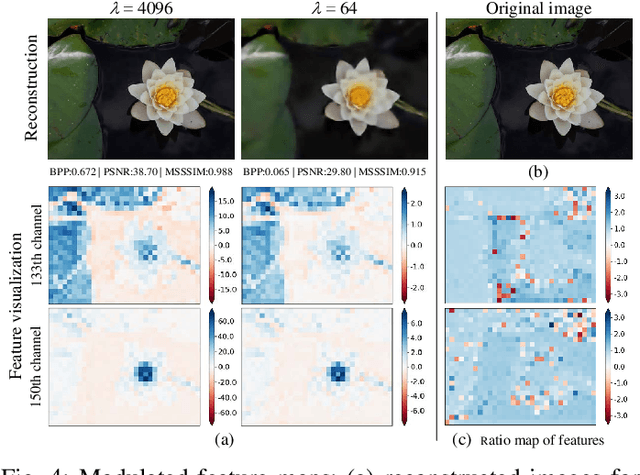
Variable rate is a requirement for flexible and adaptable image and video compression. However, deep image compression methods are optimized for a single fixed rate-distortion tradeoff. While this can be addressed by training multiple models for different tradeoffs, the memory requirements increase proportionally to the number of models. Scaling the bottleneck representation of a shared autoencoder can provide variable rate compression with a single shared autoencoder. However, the R-D performance using this simple mechanism degrades in low bitrates, and also shrinks the effective range of bit rates. Addressing these limitations, we formulate the problem of variable rate-distortion optimization for deep image compression, and propose modulated autoencoders (MAEs), where the representations of a shared autoencoder are adapted to the specific rate-distortion tradeoff via a modulation network. Jointly training this modulated autoencoder and modulation network provides an effective way to navigate the R-D operational curve. Our experiments show that the proposed method can achieve almost the same R-D performance of independent models with significantly fewer parameters.
Temporal Coherence for Active Learning in Videos
Aug 30, 2019
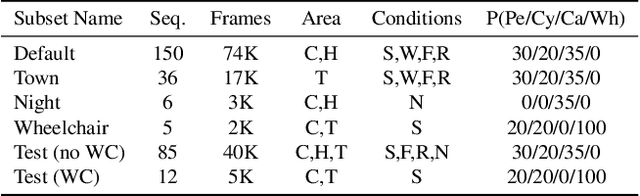
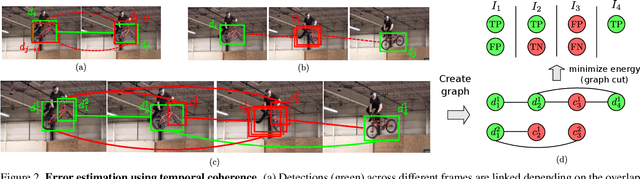
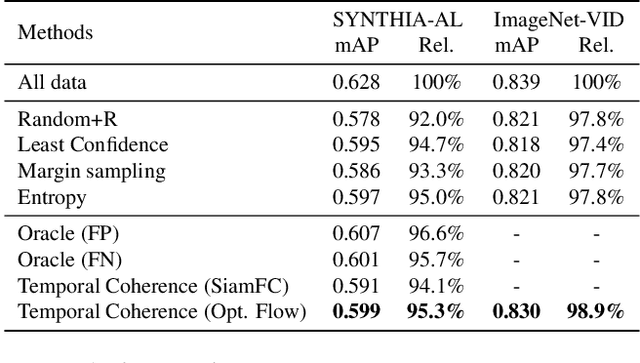
Autonomous driving systems require huge amounts of data to train. Manual annotation of this data is time-consuming and prohibitively expensive since it involves human resources. Therefore, active learning emerged as an alternative to ease this effort and to make data annotation more manageable. In this paper, we introduce a novel active learning approach for object detection in videos by exploiting temporal coherence. Our active learning criterion is based on the estimated number of errors in terms of false positives and false negatives. The detections obtained by the object detector are used to define the nodes of a graph and tracked forward and backward to temporally link the nodes. Minimizing an energy function defined on this graphical model provides estimates of both false positives and false negatives. Additionally, we introduce a synthetic video dataset, called SYNTHIA-AL, specially designed to evaluate active learning for video object detection in road scenes. Finally, we show that our approach outperforms active learning baselines tested on two datasets.