 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Deep Detection Neural Networks
Nov 20, 2019

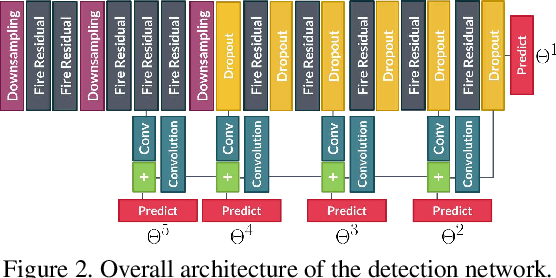
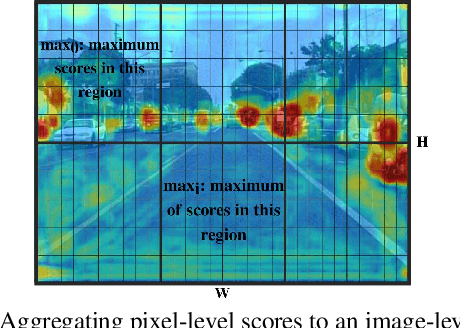
The cost of drawing object bounding boxes (i.e. labeling) for millions of images is prohibitively high. For instance, labeling pedestrians in a regular urban image could take 35 seconds on average. Active learning aims to reduce the cost of labeling by selecting only those images that are informative to improve the detection network accuracy. In this paper, we propose a method to perform active learning of object detectors based on convolutional neural networks. We propose a new image-level scoring process to rank unlabeled images for their automatic selection, which clearly outperforms classical scores. The proposed method can be applied to videos and sets of still images. In the former case, temporal selection rules can complement our scoring process. As a relevant use case, we extensively study the performance of our method on the task of pedestrian detection. Overall, the experiments show that the proposed method performs better than random selection. Our codes are publicly available at www.gitlab.com/haghdam/deep_active_learning.
Temporal Coherence for Active Learning in Videos
Aug 30, 2019
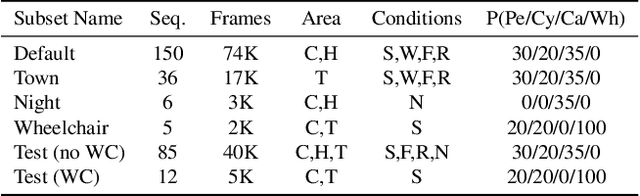
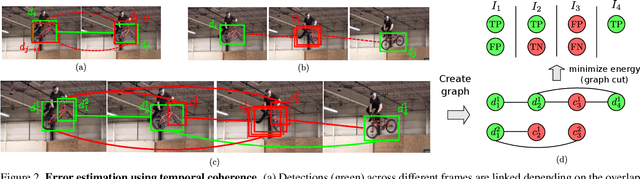
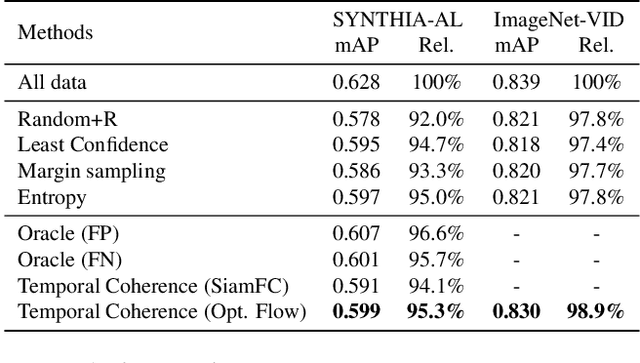
Autonomous driving systems require huge amounts of data to train. Manual annotation of this data is time-consuming and prohibitively expensive since it involves human resources. Therefore, active learning emerged as an alternative to ease this effort and to make data annotation more manageable. In this paper, we introduce a novel active learning approach for object detection in videos by exploiting temporal coherence. Our active learning criterion is based on the estimated number of errors in terms of false positives and false negatives. The detections obtained by the object detector are used to define the nodes of a graph and tracked forward and backward to temporally link the nodes. Minimizing an energy function defined on this graphical model provides estimates of both false positives and false negatives. Additionally, we introduce a synthetic video dataset, called SYNTHIA-AL, specially designed to evaluate active learning for video object detection in road scenes. Finally, we show that our approach outperforms active learning baselines tested on two datasets.
Analyzing Stability of Convolutional Neural Networks in the Frequency Domain
Nov 16, 2015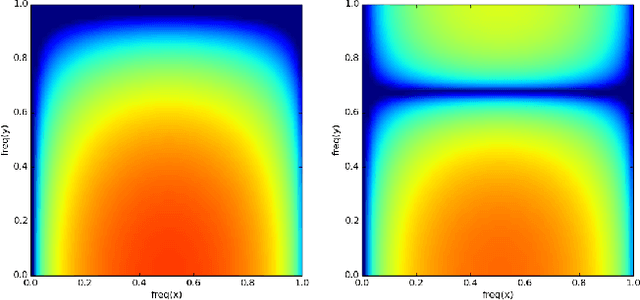

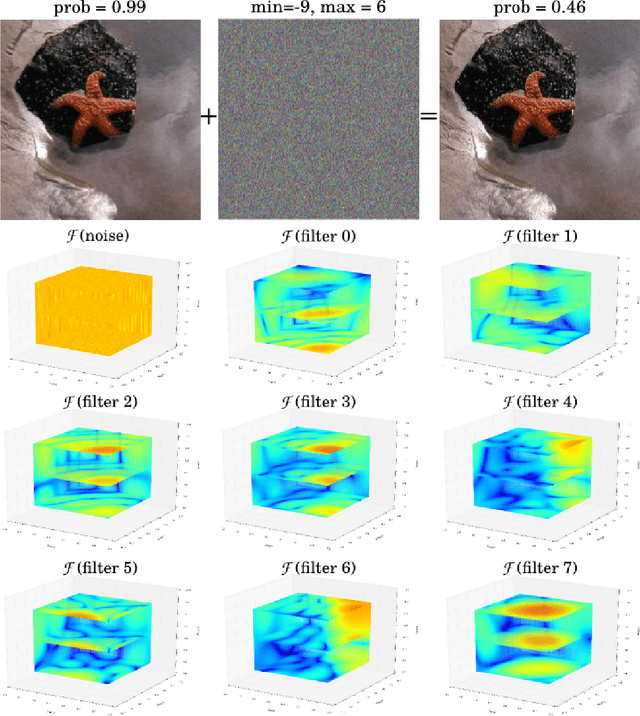
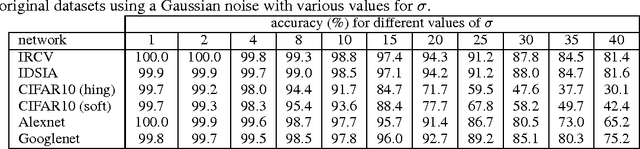
Understanding the internal process of ConvNets is commonly done using visualization techniques. However, these techniques do not usually provide a tool for estimating the stability of a ConvNet against noise. In this paper, we show how to analyze a ConvNet in the frequency domain using a 4-dimensional visualization technique. Using the frequency domain analysis, we show the reason that a ConvNet might be sensitive to a very low magnitude additive noise. Our experiments on a few ConvNets trained on different datasets revealed that convolution kernels of a trained ConvNet usually pass most of the frequencies and they are not able to effectively eliminate the effect of high frequencies. Our next experiments shows that a convolution kernel which has a more concentrated frequency response could be more stable. Finally, we show that fine-tuning a ConvNet using a training set augmented with noisy images can produce more stable ConvNets.