 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Balanced Active Learning for Image Classification
Oct 09, 2021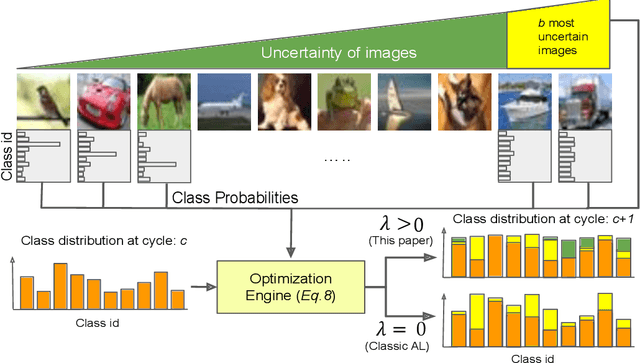
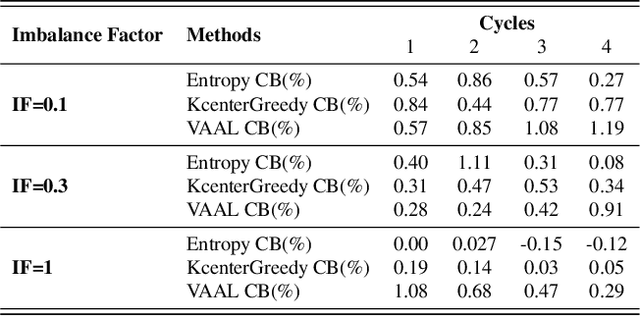
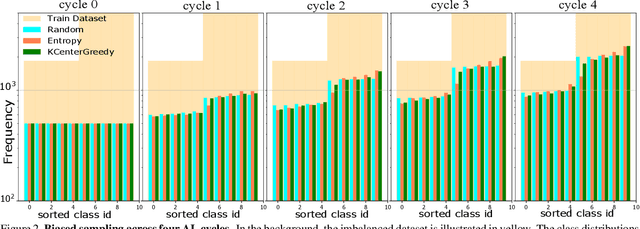
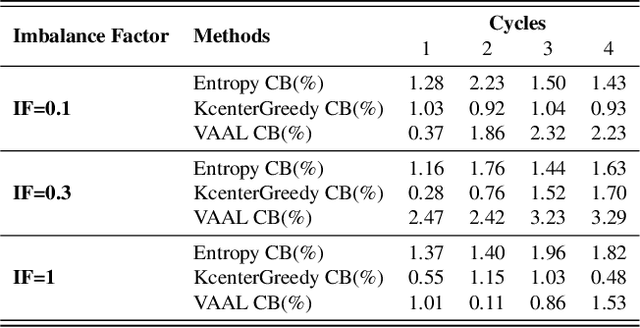
Active learning aims to reduce the labeling effort that is required to train algorithms by learning an acquisition function selecting the most relevant data for which a label should be requested from a large unlabeled data pool. Active learning is generally studied on balanced datasets where an equal amount of images per class is available. However, real-world datasets suffer from severe imbalanced classes, the so called long-tail distribution. We argue that this further complicates the active learning process, since the imbalanced data pool can result in suboptimal classifiers. To address this problem in the context of active learning, we proposed a general optimization framework that explicitly takes class-balancing into account. Results on three datasets showed that the method is general (it can be combined with most existing active learning algorithms) and can be effectively applied to boost the performance of both informative and representative-based active learning methods. In addition, we showed that also on balanced datasets our method generally results in a performance gain.
Reducing Label Effort: Self-Supervised meets Active Learning
Aug 25, 2021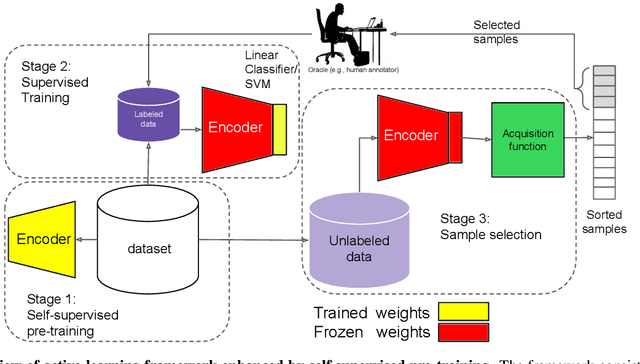
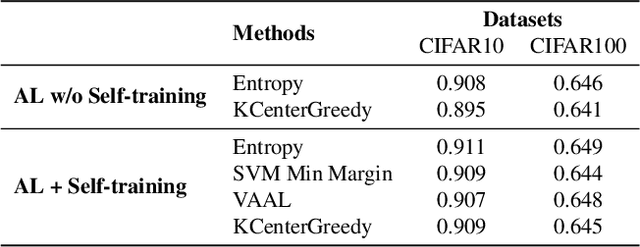
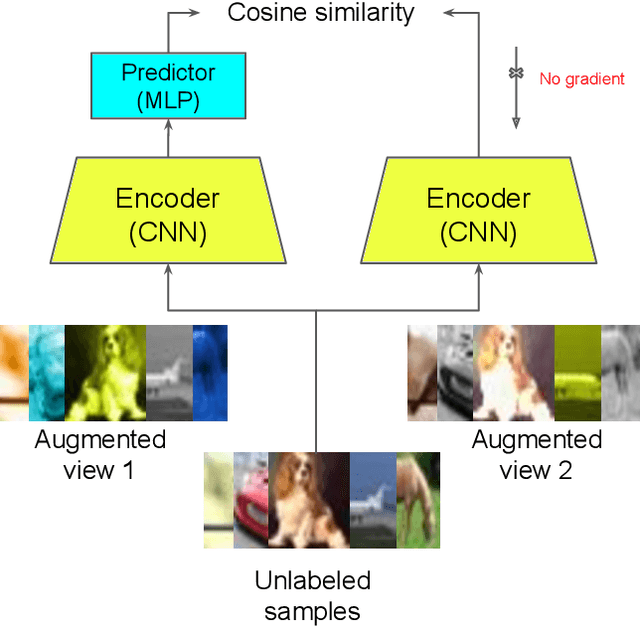
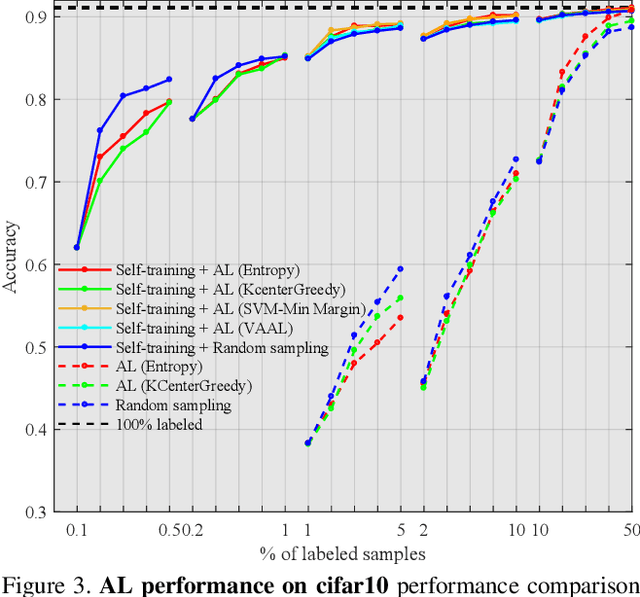
Active learning is a paradigm aimed at reducing the annotation effort by training the model on actively selected informative and/or representative samples. Another paradigm to reduce the annotation effort is self-training that learns from a large amount of unlabeled data in an unsupervised way and fine-tunes on few labeled samples. Recent developments in self-training have achieved very impressive results rivaling supervised learning on some datasets. The current work focuses on whether the two paradigms can benefit from each other. We studied object recognition datasets including CIFAR10, CIFAR100 and Tiny ImageNet with several labeling budgets for the evaluations. Our experiments reveal that self-training is remarkably more efficient than active learning at reducing the labeling effort, that for a low labeling budget, active learning offers no benefit to self-training, and finally that the combination of active learning and self-training is fruitful when the labeling budget is high. The performance gap between active learning trained either with self-training or from scratch diminishes as we approach to the point where almost half of the dataset is labeled.
When Deep Learners Change Their Mind: Learning Dynamics for Active Learning
Jul 30, 2021
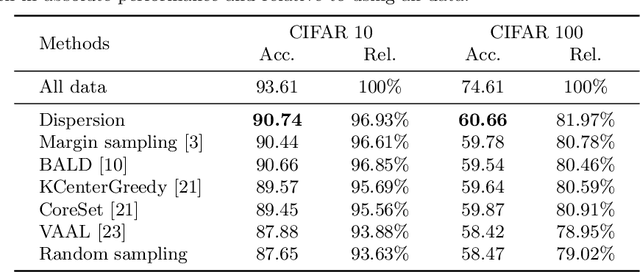
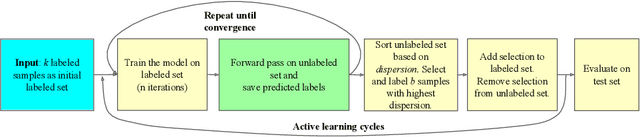

Active learning aims to select samples to be annotated that yield the largest performance improvement for the learning algorithm. Many methods approach this problem by measuring the informativeness of samples and do this based on the certainty of the network predictions for samples. However, it is well-known that neural networks are overly confident about their prediction and are therefore an untrustworthy source to assess sample informativeness. In this paper, we propose a new informativeness-based active learning method. Our measure is derived from the learning dynamics of a neural network. More precisely we track the label assignment of the unlabeled data pool during the training of the algorithm. We capture the learning dynamics with a metric called label-dispersion, which is low when the network consistently assigns the same label to the sample during the training of the network and high when the assigned label changes frequently. We show that label-dispersion is a promising predictor of the uncertainty of the network, and show on two benchmark datasets that an active learning algorithm based on label-dispersion obtains excellent results.
Temporal Coherence for Active Learning in Videos
Aug 30, 2019
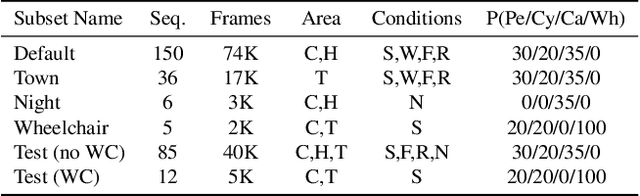
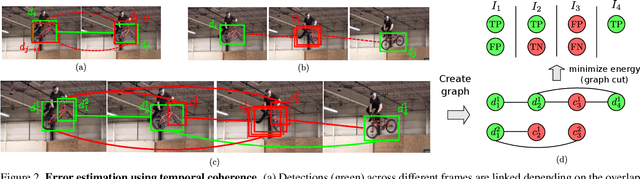
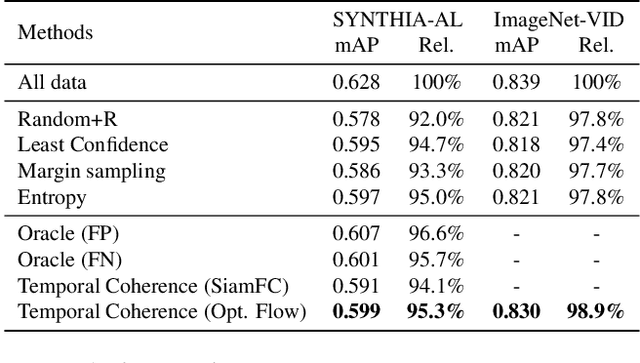
Autonomous driving systems require huge amounts of data to train. Manual annotation of this data is time-consuming and prohibitively expensive since it involves human resources. Therefore, active learning emerged as an alternative to ease this effort and to make data annotation more manageable. In this paper, we introduce a novel active learning approach for object detection in videos by exploiting temporal coherence. Our active learning criterion is based on the estimated number of errors in terms of false positives and false negatives. The detections obtained by the object detector are used to define the nodes of a graph and tracked forward and backward to temporally link the nodes. Minimizing an energy function defined on this graphical model provides estimates of both false positives and false negatives. Additionally, we introduce a synthetic video dataset, called SYNTHIA-AL, specially designed to evaluate active learning for video object detection in road scenes. Finally, we show that our approach outperforms active learning baselines tested on two datasets.