 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework for Image-to-image Translation and Image Compression
Nov 25, 2021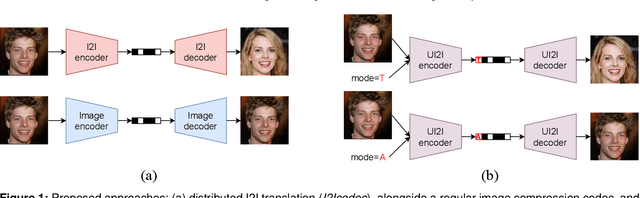
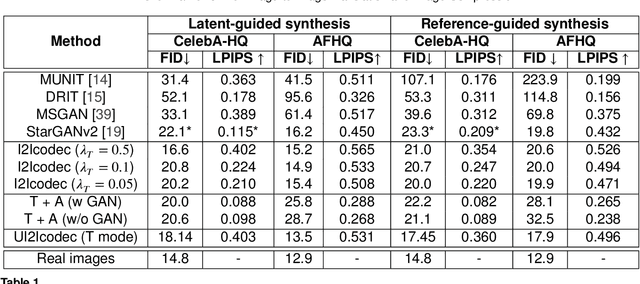


Data-driven paradigms using machine learning are becoming ubiquitous in image processing and communications. In particular, image-to-image (I2I) translation is a generic and widely used approach to image processing problems, such as image synthesis, style transfer, and image restoration. At the same time, neural image compression has emerged as a data-driven alternative to traditional coding approaches in visual communications. In this paper, we study the combination of these two paradigms into a joint I2I compression and translation framework, focusing on multi-domain image synthesis. We first propose distributed I2I translation by integrating quantization and entropy coding into an I2I translation framework (i.e. I2Icodec). In practice, the image compression functionality (i.e. autoencoding) is also desirable, requiring to deploy alongside I2Icodec a regular image codec. Thus, we further propose a unified framework that allows both translation and autoencoding capabilities in a single codec. Adaptive residual blocks conditioned on the translation/compression mode provide flexible adaptation to the desired functionality. The experiments show promising results in both I2I translation and image compression using a single model.
3D Shapes Local Geometry Codes Learning with SDF
Aug 19, 2021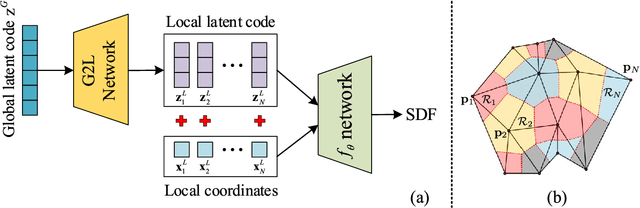

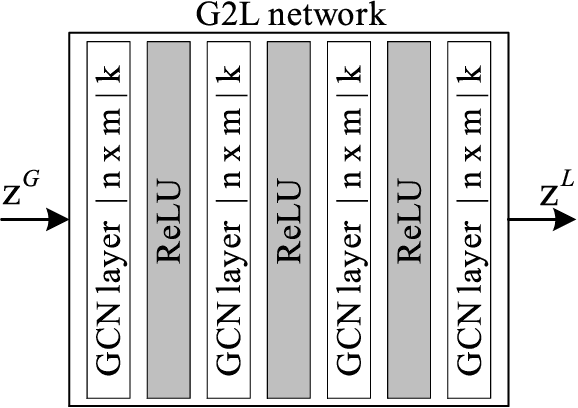

A signed distance function (SDF) as the 3D shape description is one of the most effective approaches to represent 3D geometry for rendering and reconstruction. Our work is inspired by the state-of-the-art method DeepSDF that learns and analyzes the 3D shape as the iso-surface of its shell and this method has shown promising results especially in the 3D shape reconstruction and compression domain. In this paper, we consider the degeneration problem of reconstruction coming from the capacity decrease of the DeepSDF model, which approximates the SDF with a neural network and a single latent code. We propose Local Geometry Code Learning (LGCL), a model that improves the original DeepSDF results by learning from a local shape geometry of the full 3D shape. We add an extra graph neural network to split the single transmittable latent code into a set of local latent codes distributed on the 3D shape. Mentioned latent codes are used to approximate the SDF in their local regions, which will alleviate the complexity of the approximation compared to the original DeepSDF. Furthermore, we introduce a new geometric loss function to facilitate the training of these local latent codes. Note that other local shape adjusting methods use the 3D voxel representation, which in turn is a problem highly difficult to solve or even is insolvable. In contrast, our architecture is based on graph processing implicitly and performs the learning regression process directly in the latent code space, thus make the proposed architecture more flexible and also simple for realization. Our experiments on 3D shape reconstruction demonstrate that our LGCL method can keep more details with a significantly smaller size of the SDF decoder and outperforms considerably the original DeepSDF method under the most important quantitative metrics.
Slimmable Compressive Autoencoders for Practical Neural Image Compression
Mar 29, 2021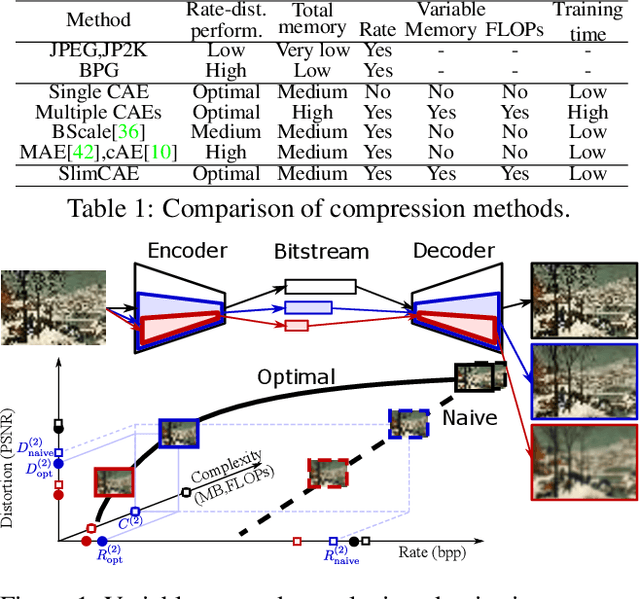


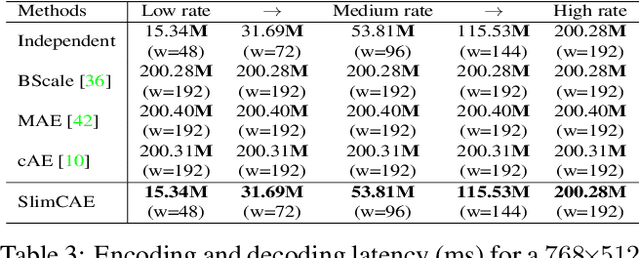
Neural image compression leverages deep neural networks to outperform traditional image codecs in rate-distortion performance. However, the resulting models are also heavy, computationally demanding and generally optimized for a single rate, limiting their practical use. Focusing on practical image compression, we propose slimmable compressive autoencoders (SlimCAEs), where rate (R) and distortion (D) are jointly optimized for different capacities. Once trained, encoders and decoders can be executed at different capacities, leading to different rates and complexities. We show that a successful implementation of SlimCAEs requires suitable capacity-specific RD tradeoffs. Our experiments show that SlimCAEs are highly flexible models that provide excellent rate-distortion performance, variable rate, and dynamic adjustment of memory, computational cost and latency, thus addressing the main requirements of practical image compression.
Semantic Drift Compensation for Class-Incremental Learning
Apr 01, 2020



Class-incremental learning of deep networks sequentially increases the number of classes to be classified. During training, the network has only access to data of one task at a time, where each task contains several classes. In this setting, networks suffer from catastrophic forgetting which refers to the drastic drop in performance on previous tasks. The vast majority of methods have studied this scenario for classification networks, where for each new task the classification layer of the network must be augmented with additional weights to make room for the newly added classes. Embedding networks have the advantage that new classes can be naturally included into the network without adding new weights. Therefore, we study incremental learning for embedding networks. In addition, we propose a new method to estimate the drift, called semantic drift, of features and compensate for it without the need of any exemplars. We approximate the drift of previous tasks based on the drift that is experienced by current task data. We perform experiments on fine-grained datasets, CIFAR100 and ImageNet-Subset. We demonstrate that embedding networks suffer significantly less from catastrophic forgetting. We outperform existing methods which do not require exemplars and obtain competitive results compared to methods which store exemplars. Furthermore, we show that our proposed SDC when combined with existing methods to prevent forgetting consistently improves results.
Learning Metrics from Teachers: Compact Networks for Image Embedding
Apr 07, 2019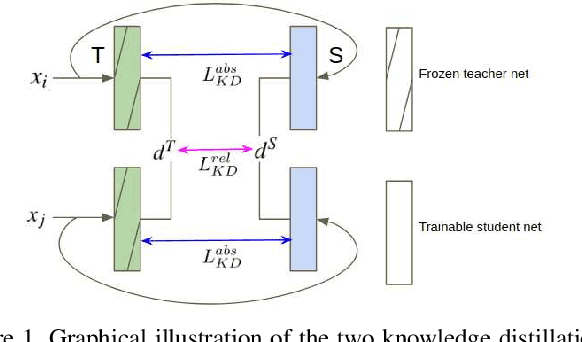
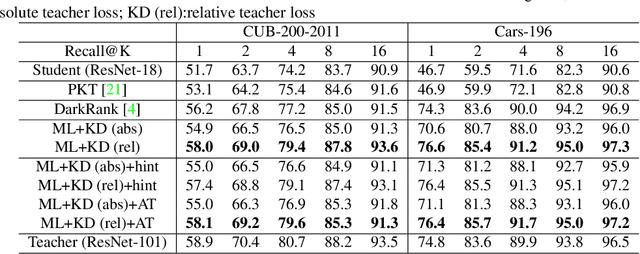
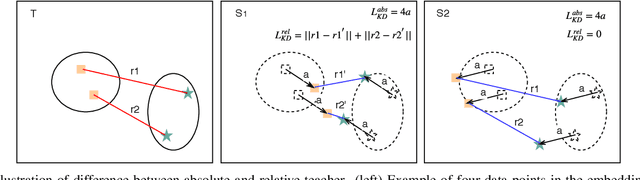
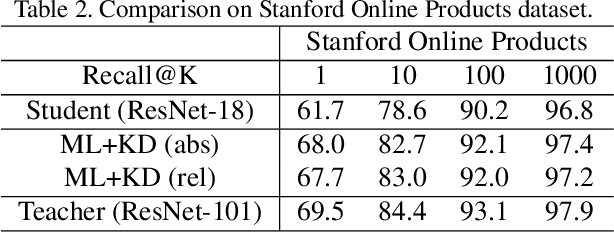
Metric learning networks are used to compute image embeddings, which are widely used in many applications such as image retrieval and face recognition. In this paper, we propose to use network distillation to efficiently compute image embeddings with small networks. Network distillation has been successfully applied to improve image classification, but has hardly been explored for metric learning. To do so, we propose two new loss functions that model the communication of a deep teacher network to a small student network. We evaluate our system in several datasets, including CUB-200-2011, Cars-196, Stanford Online Products and show that embeddings computed using small student networks perform significantly better than those computed using standard networks of similar size. Results on a very compact network (MobileNet-0.25), which can be used on mobile devices, show that the proposed method can greatly improve Recall@1 results from 27.5\% to 44.6\%. Furthermore, we investigate various aspects of distillation for embeddings, including hint and attention layers, semi-supervised learning and cross quality distillation. (Code is available at https://github.com/yulu0724/EmbeddingDistillation.)
Weakly Supervised Domain-Specific Color Naming Based on Attention
May 11, 2018
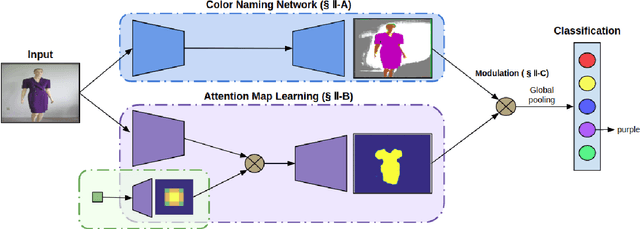


The majority of existing color naming methods focuses on the eleven basic color terms of the English language. However, in many applications, different sets of color names are used for the accurate description of objects. Labeling data to learn these domain-specific color names is an expensive and laborious task. Therefore, in this article we aim to learn color names from weakly labeled data. For this purpose, we add an attention branch to the color naming network. The attention branch is used to modulate the pixel-wise color naming predictions of the network. In experiments, we illustrate that the attention branch correctly identifies the relevant regions. Furthermore, we show that our method obtains state-of-the-art results for pixel-wise and image-wise classification on the EBAY dataset and is able to learn color names for various domains.