 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMain Product Detection with Graph Networks for Fashion
Jan 25, 2022Computer vision has established a foothold in the online fashion retail industry. Main product detection is a crucial step of vision-based fashion product feed parsing pipelines, focused in identifying the bounding boxes that contain the product being sold in the gallery of images of the product page. The current state-of-the-art approach does not leverage the relations between regions in the image, and treats images of the same product independently, therefore not fully exploiting visual and product contextual information. In this paper we propose a model that incorporates Graph Convolutional Networks (GCN) that jointly represent all detected bounding boxes in the gallery as nodes. We show that the proposed method is better than the state-of-the-art, especially, when we consider the scenario where title-input is missing at inference time and for cross-dataset evaluation, our method outperforms previous approaches by a large margin.
Visual Transformers with Primal Object Queries for Multi-Label Image Classification
Dec 10, 2021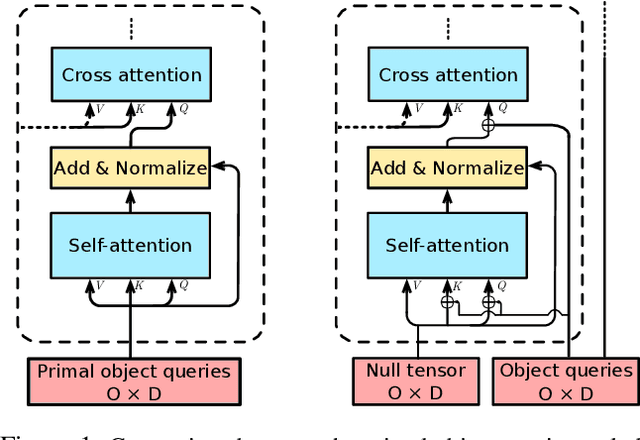
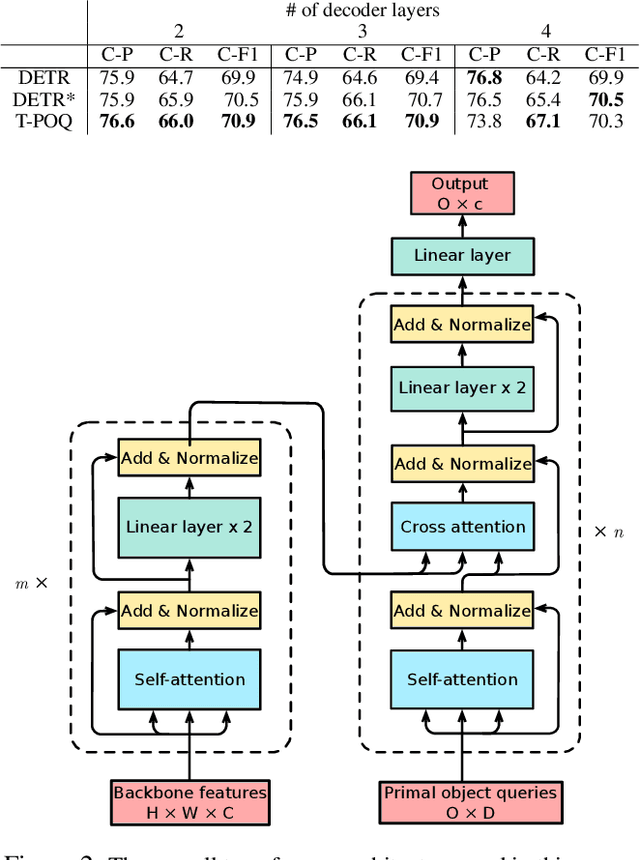
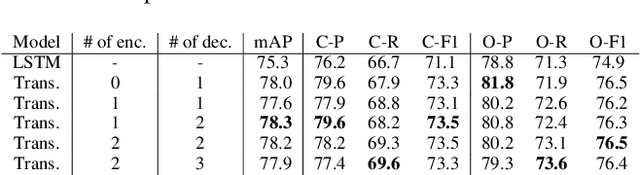

Multi-label image classification is about predicting a set of class labels that can be considered as orderless sequential data. Transformers process the sequential data as a whole, therefore they are inherently good at set prediction. The first vision-based transformer model, which was proposed for the object detection task introduced the concept of object queries. Object queries are learnable positional encodings that are used by attention modules in decoder layers to decode the object classes or bounding boxes using the region of interests in an image. However, inputting the same set of object queries to different decoder layers hinders the training: it results in lower performance and delays convergence. In this paper, we propose the usage of primal object queries that are only provided at the start of the transformer decoder stack. In addition, we improve the mixup technique proposed for multi-label classification. The proposed transformer model with primal object queries improves the state-of-the-art class wise F1 metric by 2.1% and 1.8%; and speeds up the convergence by 79.0% and 38.6% on MS-COCO and NUS-WIDE datasets respectively.
Orderless Recurrent Models for Multi-label Classification
Nov 25, 2019
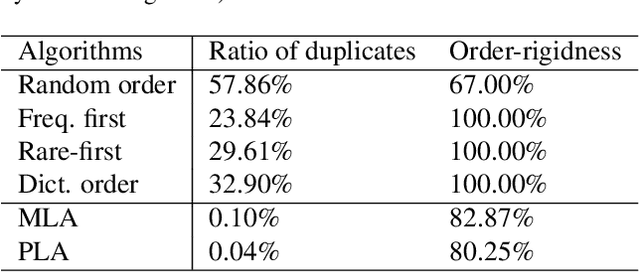
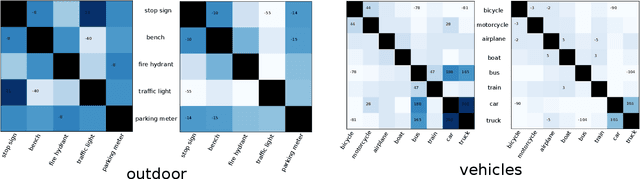
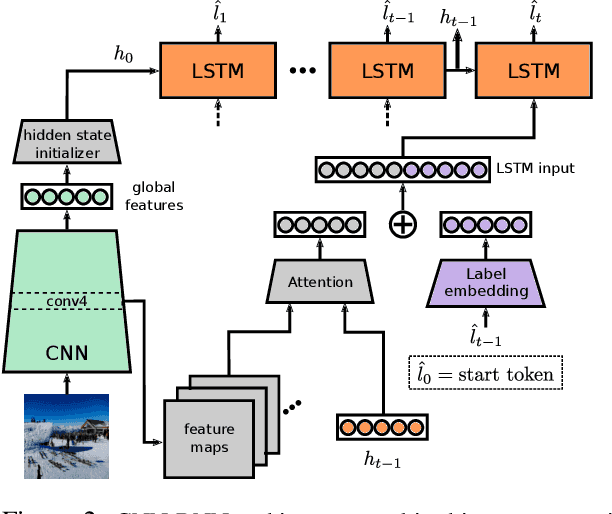
Recurrent neural networks (RNN) are popular for many computer vision tasks, including multi-label classification. Since RNNs produce sequential outputs, labels need to be ordered for the multi-label classification task. Current approaches sort labels according to their frequency, typically ordering them in either rare-first or frequent-first. These imposed orderings do not take into account that the natural order to generate the labels can change for each image, e.g.\ first the dominant object before summing up the smaller objects in the image. Therefore, in this paper, we propose ways to dynamically order the ground truth labels with the predicted label sequence. This allows for the faster training of more optimal LSTM models for multi-label classification. Analysis evidences that our method does not suffer from duplicate generation, something which is common for other models. Furthermore, it outperforms other CNN-RNN models, and we show that a standard architecture of an image encoder and language decoder trained with our proposed loss obtains the state-of-the-art results on the challenging MS-COCO, WIDER Attribute and PA-100K and competitive results on NUS-WIDE.
Learning Metrics from Teachers: Compact Networks for Image Embedding
Apr 07, 2019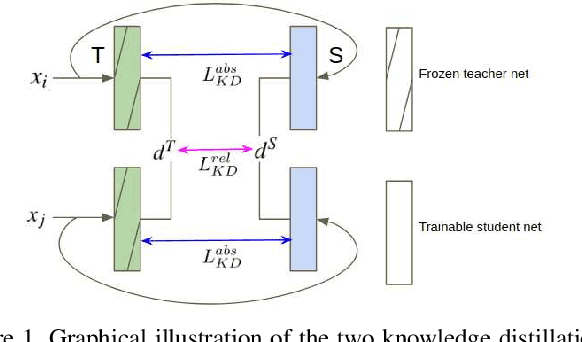
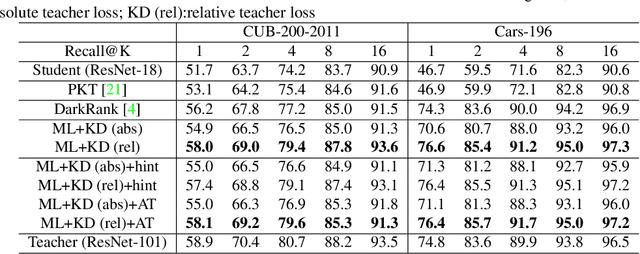
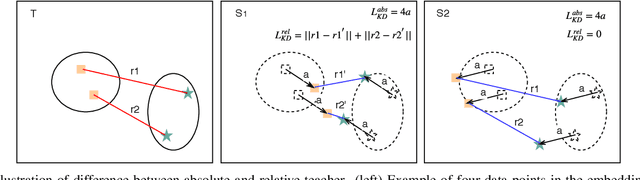
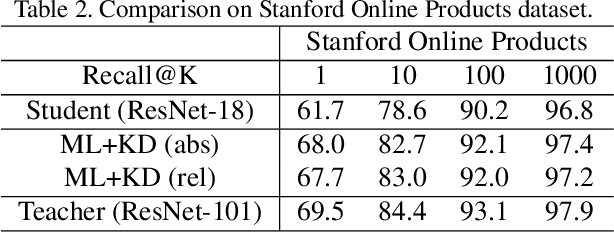
Metric learning networks are used to compute image embeddings, which are widely used in many applications such as image retrieval and face recognition. In this paper, we propose to use network distillation to efficiently compute image embeddings with small networks. Network distillation has been successfully applied to improve image classification, but has hardly been explored for metric learning. To do so, we propose two new loss functions that model the communication of a deep teacher network to a small student network. We evaluate our system in several datasets, including CUB-200-2011, Cars-196, Stanford Online Products and show that embeddings computed using small student networks perform significantly better than those computed using standard networks of similar size. Results on a very compact network (MobileNet-0.25), which can be used on mobile devices, show that the proposed method can greatly improve Recall@1 results from 27.5\% to 44.6\%. Furthermore, we investigate various aspects of distillation for embeddings, including hint and attention layers, semi-supervised learning and cross quality distillation. (Code is available at https://github.com/yulu0724/EmbeddingDistillation.)