 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Transformers with Primal Object Queries for Multi-Label Image Classification
Paper and Code
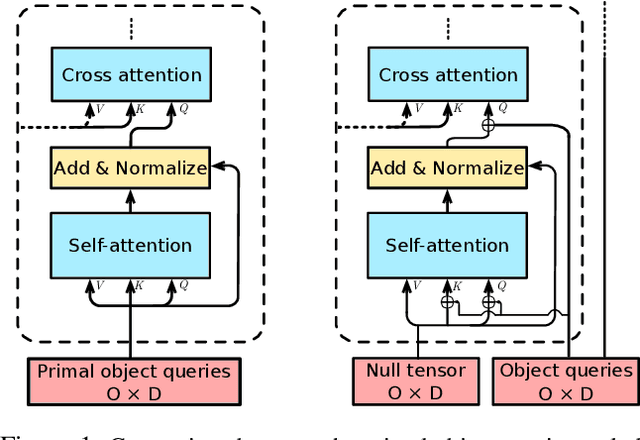
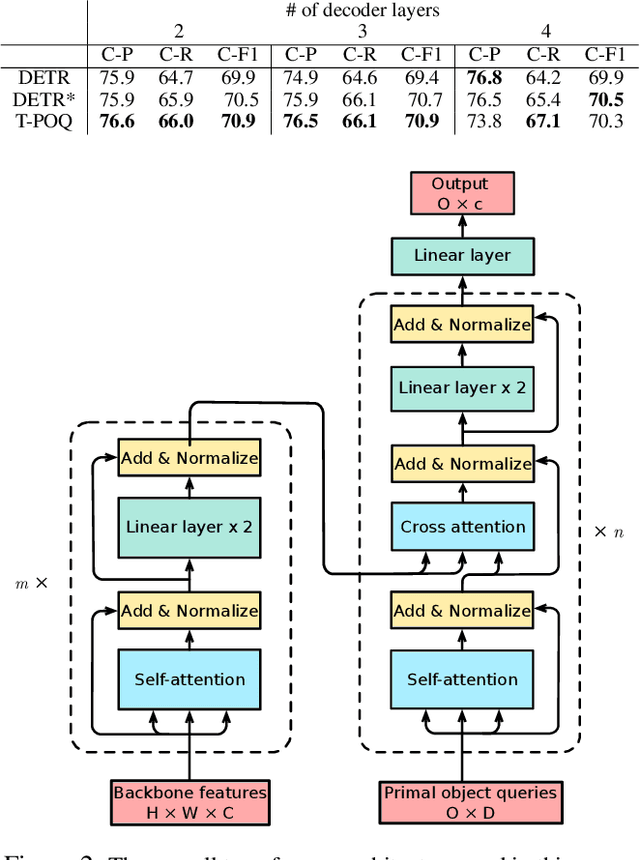
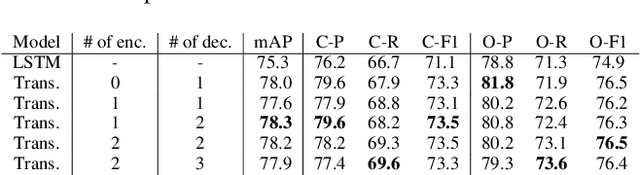

Multi-label image classification is about predicting a set of class labels that can be considered as orderless sequential data. Transformers process the sequential data as a whole, therefore they are inherently good at set prediction. The first vision-based transformer model, which was proposed for the object detection task introduced the concept of object queries. Object queries are learnable positional encodings that are used by attention modules in decoder layers to decode the object classes or bounding boxes using the region of interests in an image. However, inputting the same set of object queries to different decoder layers hinders the training: it results in lower performance and delays convergence. In this paper, we propose the usage of primal object queries that are only provided at the start of the transformer decoder stack. In addition, we improve the mixup technique proposed for multi-label classification. The proposed transformer model with primal object queries improves the state-of-the-art class wise F1 metric by 2.1% and 1.8%; and speeds up the convergence by 79.0% and 38.6% on MS-COCO and NUS-WIDE datasets respectively.