 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Rate Deep Image Compression with Modulated Autoencoder
Dec 11, 2019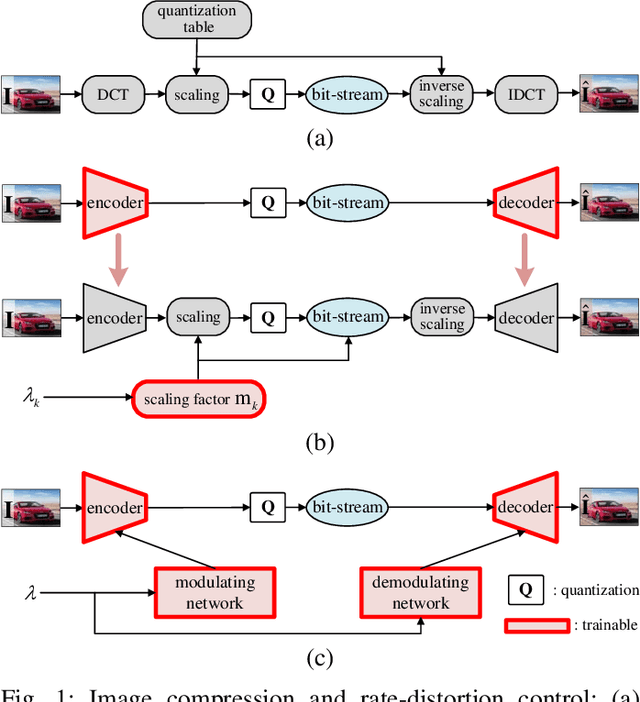

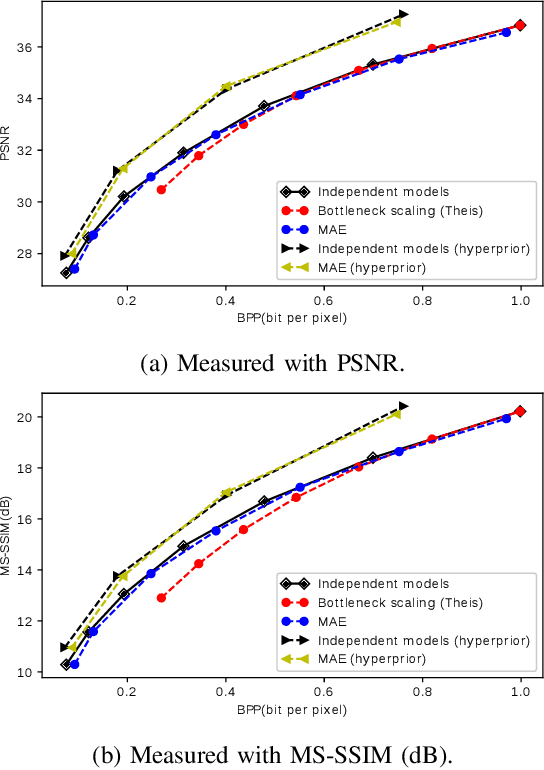
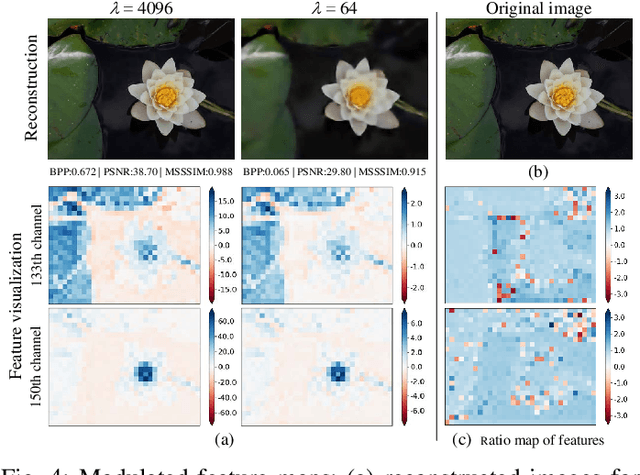
Variable rate is a requirement for flexible and adaptable image and video compression. However, deep image compression methods are optimized for a single fixed rate-distortion tradeoff. While this can be addressed by training multiple models for different tradeoffs, the memory requirements increase proportionally to the number of models. Scaling the bottleneck representation of a shared autoencoder can provide variable rate compression with a single shared autoencoder. However, the R-D performance using this simple mechanism degrades in low bitrates, and also shrinks the effective range of bit rates. Addressing these limitations, we formulate the problem of variable rate-distortion optimization for deep image compression, and propose modulated autoencoders (MAEs), where the representations of a shared autoencoder are adapted to the specific rate-distortion tradeoff via a modulation network. Jointly training this modulated autoencoder and modulation network provides an effective way to navigate the R-D operational curve. Our experiments show that the proposed method can achieve almost the same R-D performance of independent models with significantly fewer parameters.
End-to-end Driving via Conditional Imitation Learning
Mar 02, 2018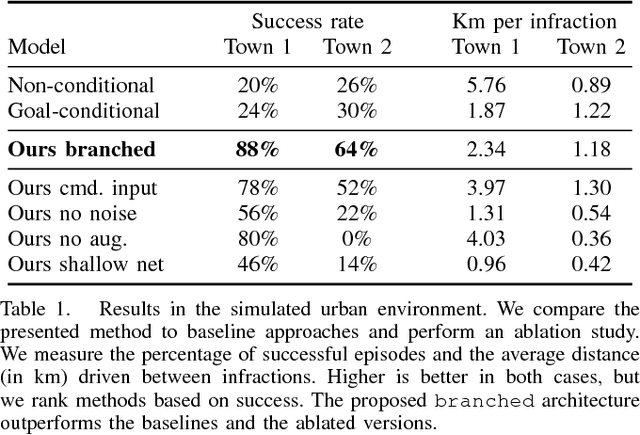
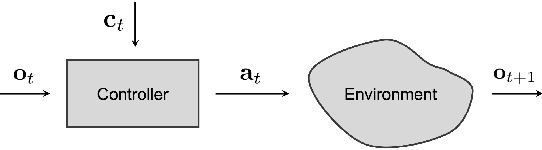
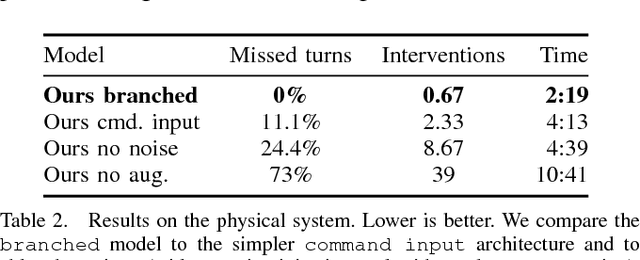
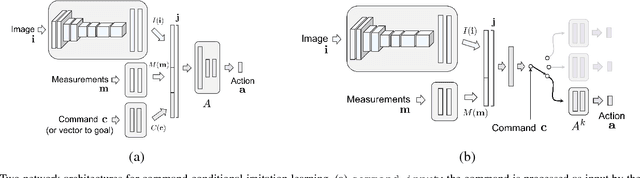
Deep networks trained on demonstrations of human driving have learned to follow roads and avoid obstacles. However, driving policies trained via imitation learning cannot be controlled at test time. A vehicle trained end-to-end to imitate an expert cannot be guided to take a specific turn at an upcoming intersection. This limits the utility of such systems. We propose to condition imitation learning on high-level command input. At test time, the learned driving policy functions as a chauffeur that handles sensorimotor coordination but continues to respond to navigational commands. We evaluate different architectures for conditional imitation learning in vision-based driving. We conduct experiments in realistic three-dimensional simulations of urban driving and on a 1/5 scale robotic truck that is trained to drive in a residential area. Both systems drive based on visual input yet remain responsive to high-level navigational commands. The supplementary video can be viewed at https://youtu.be/cFtnflNe5fM