 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Self-Supervised End-to-End Driving with Multi-View Attention Learning
Feb 09, 2023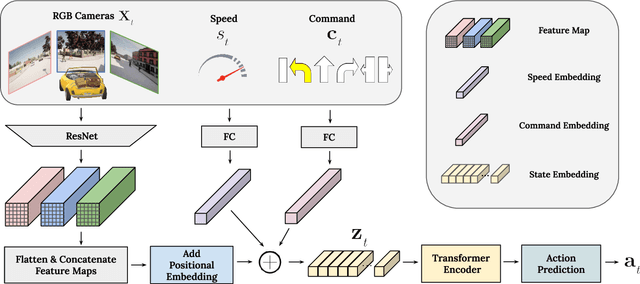
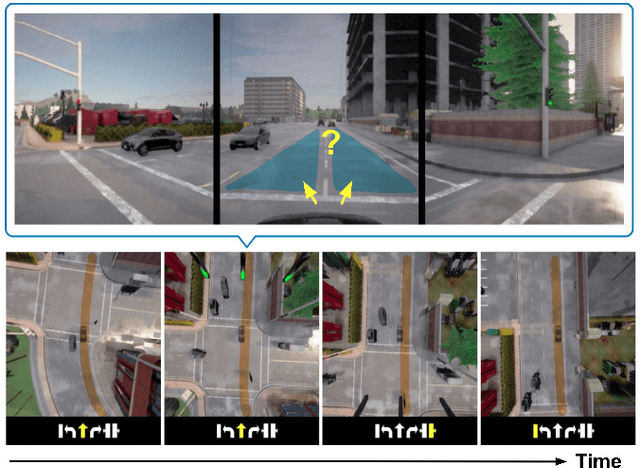


On end-to-end driving, a large amount of expert driving demonstrations is used to train an agent that mimics the expert by predicting its control actions. This process is self-supervised on vehicle signals (e.g., steering angle, acceleration) and does not require extra costly supervision (human labeling). Yet, the improvement of existing self-supervised end-to-end driving models has mostly given room to modular end-to-end models where labeling data intensive format such as semantic segmentation are required during training time. However, we argue that the latest self-supervised end-to-end models were developed in sub-optimal conditions with low-resolution images and no attention mechanisms. Further, those models are confined with limited field of view and far from the human visual cognition which can quickly attend far-apart scene features, a trait that provides an useful inductive bias. In this context, we present a new end-to-end model, trained by self-supervised imitation learning, leveraging a large field of view and a self-attention mechanism. These settings are more contributing to the agent's understanding of the driving scene, which brings a better imitation of human drivers. With only self-supervised training data, our model yields almost expert performance in CARLA's Nocrash metrics and could be rival to the SOTA models requiring large amounts of human labeled data. To facilitate further research, our code will be released.
Learned Image Compression for Machine Perception
Nov 03, 2021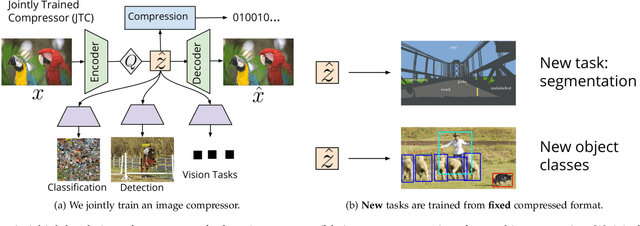
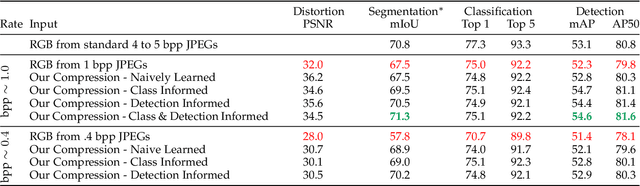
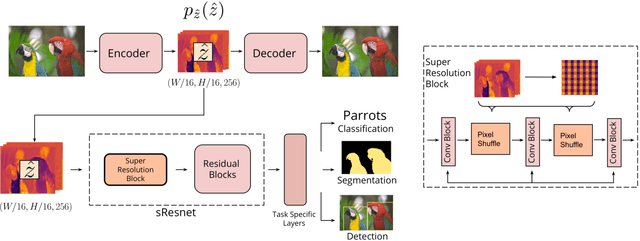

Recent work has shown that learned image compression strategies can outperform standard hand-crafted compression algorithms that have been developed over decades of intensive research on the rate-distortion trade-off. With growing applications of computer vision, high quality image reconstruction from a compressible representation is often a secondary objective. Compression that ensures high accuracy on computer vision tasks such as image segmentation, classification, and detection therefore has the potential for significant impact across a wide variety of settings. In this work, we develop a framework that produces a compression format suitable for both human perception and machine perception. We show that representations can be learned that simultaneously optimize for compression and performance on core vision tasks. Our approach allows models to be trained directly from compressed representations, and this approach yields increased performance on new tasks and in low-shot learning settings. We present results that improve upon segmentation and detection performance compared to standard high quality JPGs, but with representations that are four to ten times smaller in terms of bits per pixel. Further, unlike naive compression methods, at a level ten times smaller than standard JEPGs, segmentation and detection models trained from our format suffer only minor degradation in performance.
Action-Based Representation Learning for Autonomous Driving
Aug 21, 2020
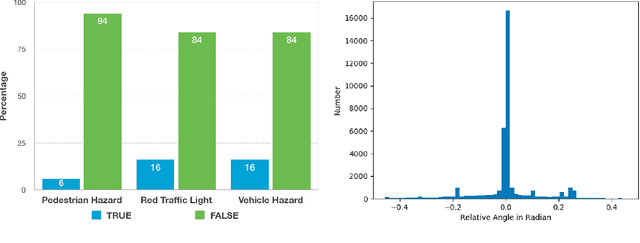
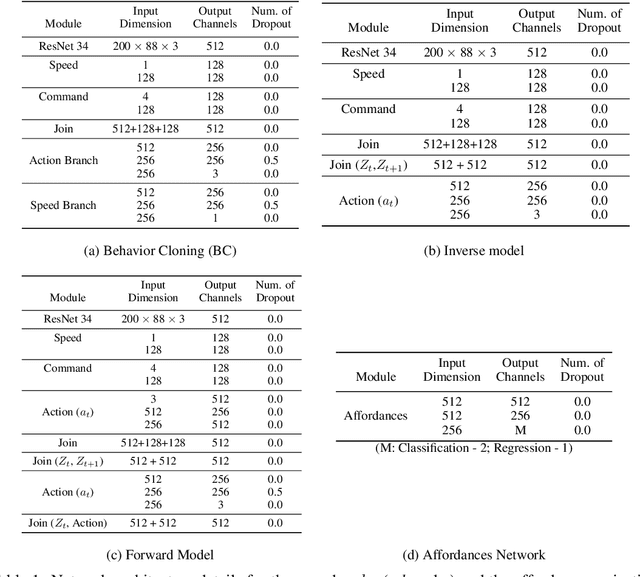
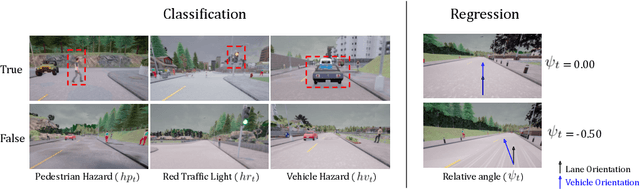
Human drivers produce a vast amount of data which could, in principle, be used to improve autonomous driving systems. Unfortunately, seemingly straightforward approaches for creating end-to-end driving models that map sensor data directly into driving actions are problematic in terms of interpretability, and typically have significant difficulty dealing with spurious correlations. Alternatively, we propose to use this kind of action-based driving data for learning representations. Our experiments show that an affordance-based driving model pre-trained with this approach can leverage a relatively small amount of weakly annotated imagery and outperform pure end-to-end driving models, while being more interpretable. Further, we demonstrate how this strategy outperforms previous methods based on learning inverse dynamics models as well as other methods based on heavy human supervision (ImageNet).
Multimodal End-to-End Autonomous Driving
Jun 07, 2019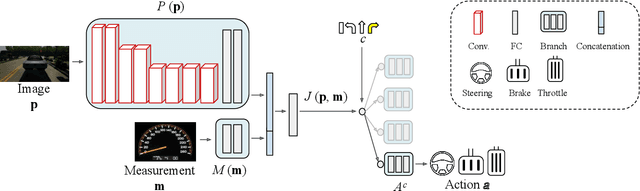
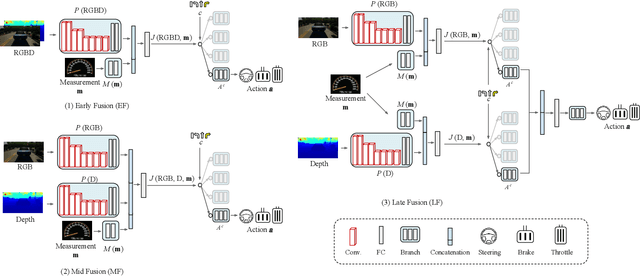

Autonomous vehicles (AVs) are key for the intelligent mobility of the future. A crucial component of an AV is the artificial intelligence (AI) able to drive towards a desired destination. Today, there are different paradigms addressing the development of AI drivers. On the one hand, we find modular pipelines, which divide the driving task into sub-tasks such as perception (object detection, semantic segmentation, depth estimation, tracking) and maneuver control (local path planing and control). On the other hand, we find end-to-end driving approaches that try to learn a direct mapping from input raw sensor data to vehicle control signals (the steering angle). The later are relatively less studied, but are gaining popularity since they are less demanding in terms of sensor data annotation. This paper focuses on end-to-end autonomous driving. So far, most proposals relying on this paradigm assume RGB images as input sensor data. However, AVs will not be equipped only with cameras, but also with active sensors providing accurate depth information (traditional LiDARs, or new solid state ones). Accordingly, this paper analyses if RGB and depth data, RGBD data, can actually act as complementary information in a multimodal end-to-end driving approach, producing a better AI driver. Using the CARLA simulator functionalities, its standard benchmark, and conditional imitation learning (CIL), we will show how, indeed, RGBD gives rise to more successful end-to-end AI drivers. We will compare the use of RGBD information by means of early, mid and late fusion schemes, both in multisensory and single-sensor (monocular depth estimation) settings.
Exploring the Limitations of Behavior Cloning for Autonomous Driving
Apr 18, 2019
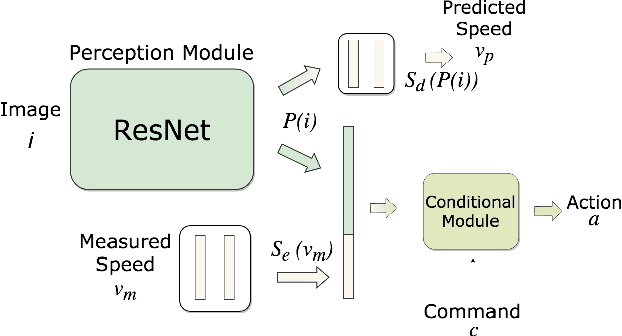

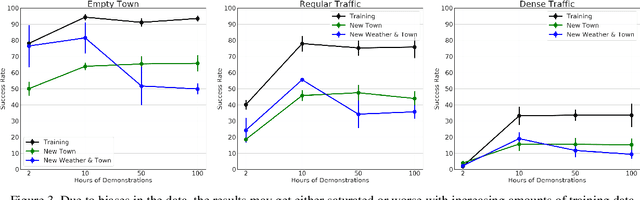
Driving requires reacting to a wide variety of complex environment conditions and agent behaviors. Explicitly modeling each possible scenario is unrealistic. In contrast, imitation learning can, in theory, leverage data from large fleets of human-driven cars. Behavior cloning in particular has been successfully used to learn simple visuomotor policies end-to-end, but scaling to the full spectrum of driving behaviors remains an unsolved problem. In this paper, we propose a new benchmark to experimentally investigate the scalability and limitations of behavior cloning. We show that behavior cloning leads to state-of-the-art results, including in unseen environments, executing complex lateral and longitudinal maneuvers without these reactions being explicitly programmed. However, we confirm well-known limitations (due to dataset bias and overfitting), new generalization issues (due to dynamic objects and the lack of a causal model), and training instability requiring further research before behavior cloning can graduate to real-world driving. The code of the studied behavior cloning approaches can be found at https://github.com/felipecode/coiltraine .
On Offline Evaluation of Vision-based Driving Models
Sep 13, 2018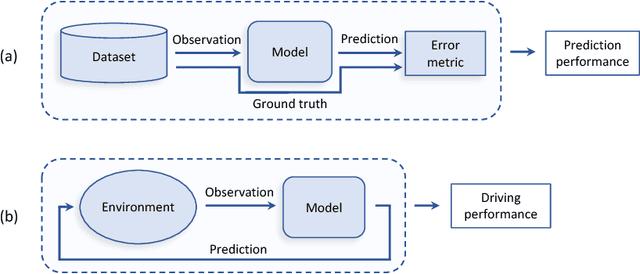
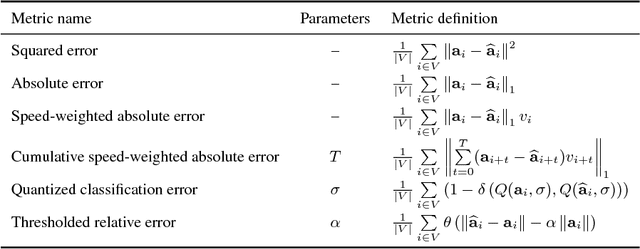
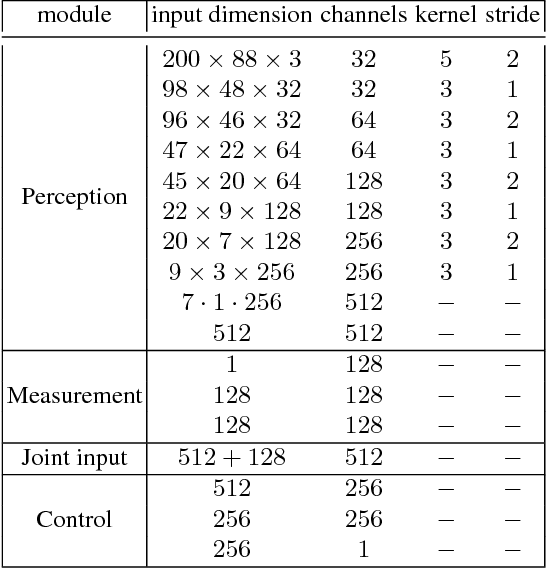
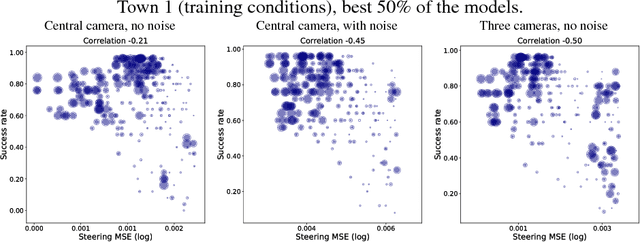
Autonomous driving models should ideally be evaluated by deploying them on a fleet of physical vehicles in the real world. Unfortunately, this approach is not practical for the vast majority of researchers. An attractive alternative is to evaluate models offline, on a pre-collected validation dataset with ground truth annotation. In this paper, we investigate the relation between various online and offline metrics for evaluation of autonomous driving models. We find that offline prediction error is not necessarily correlated with driving quality, and two models with identical prediction error can differ dramatically in their driving performance. We show that the correlation of offline evaluation with driving quality can be significantly improved by selecting an appropriate validation dataset and suitable offline metrics. The supplementary video can be viewed at https://www.youtube.com/watch?v=P8K8Z-iF0cY
End-to-end Driving via Conditional Imitation Learning
Mar 02, 2018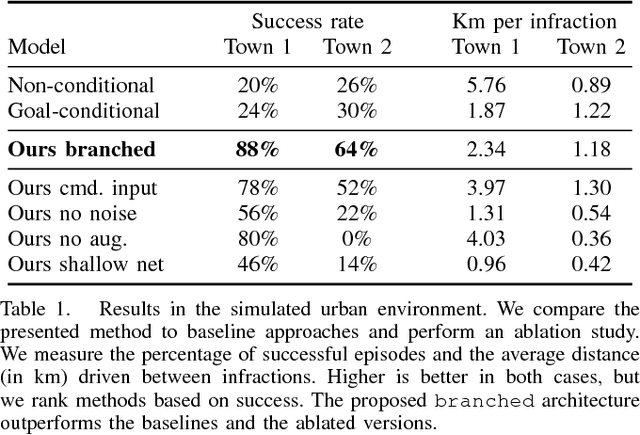
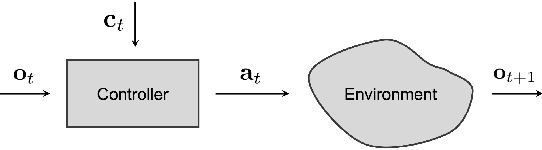
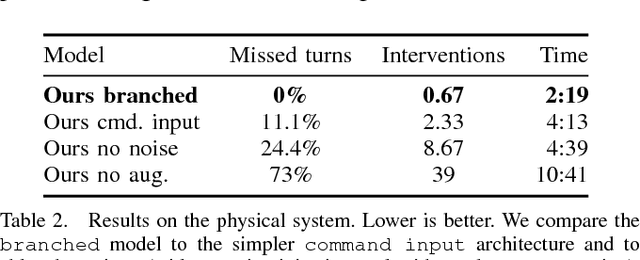
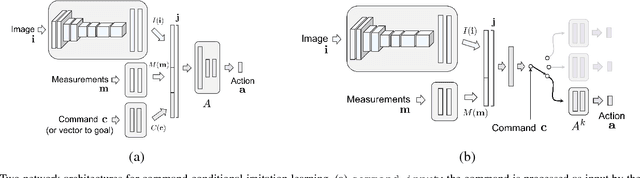
Deep networks trained on demonstrations of human driving have learned to follow roads and avoid obstacles. However, driving policies trained via imitation learning cannot be controlled at test time. A vehicle trained end-to-end to imitate an expert cannot be guided to take a specific turn at an upcoming intersection. This limits the utility of such systems. We propose to condition imitation learning on high-level command input. At test time, the learned driving policy functions as a chauffeur that handles sensorimotor coordination but continues to respond to navigational commands. We evaluate different architectures for conditional imitation learning in vision-based driving. We conduct experiments in realistic three-dimensional simulations of urban driving and on a 1/5 scale robotic truck that is trained to drive in a residential area. Both systems drive based on visual input yet remain responsive to high-level navigational commands. The supplementary video can be viewed at https://youtu.be/cFtnflNe5fM
CARLA: An Open Urban Driving Simulator
Nov 10, 2017
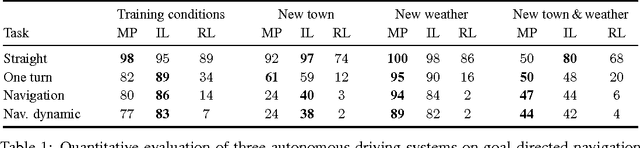

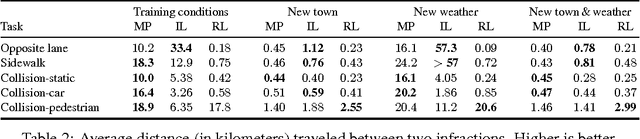
We introduce CARLA, an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous urban driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely. The simulation platform supports flexible specification of sensor suites and environmental conditions. We use CARLA to study the performance of three approaches to autonomous driving: a classic modular pipeline, an end-to-end model trained via imitation learning, and an end-to-end model trained via reinforcement learning. The approaches are evaluated in controlled scenarios of increasing difficulty, and their performance is examined via metrics provided by CARLA, illustrating the platform's utility for autonomous driving research. The supplementary video can be viewed at https://youtu.be/Hp8Dz-Zek2E
Single Image Restoration for Participating Media Based on Prior Fusion
Jan 11, 2017
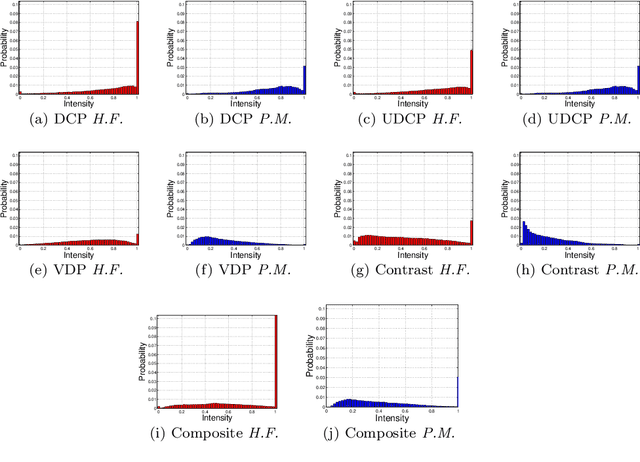
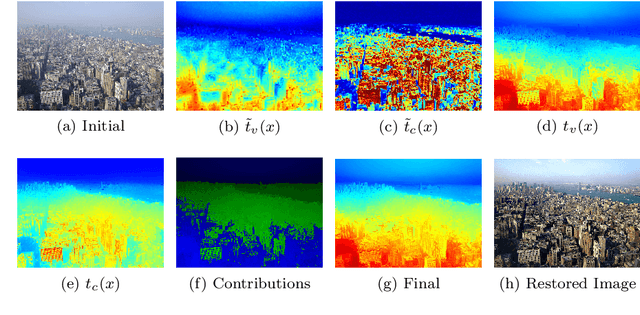
This paper describes a method to restore degraded images captured in a participating media -- fog, turbid water, sand storm, etc. Differently from the related work that only deal with a medium, we obtain generality by using an image formation model and a fusion of new image priors. The model considers the image color variation produced by the medium. The proposed restoration method is based on the fusion of these priors and supported by statistics collected on images acquired in both non-participating and participating media. The key of the method is to fuse two complementary measures --- local contrast and color data. The obtained results on underwater and foggy images demonstrate the capabilities of the proposed method. Moreover, we evaluated our method using a special dataset for which a ground-truth image is available.