 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPNext: Tracking Any Point (TAP) as Next Token Prediction
Apr 08, 2025Tracking Any Point (TAP) in a video is a challenging computer vision problem with many demonstrated applications in robotics, video editing, and 3D reconstruction. Existing methods for TAP rely heavily on complex tracking-specific inductive biases and heuristics, limiting their generality and potential for scaling. To address these challenges, we present TAPNext, a new approach that casts TAP as sequential masked token decoding. Our model is causal, tracks in a purely online fashion, and removes tracking-specific inductive biases. This enables TAPNext to run with minimal latency, and removes the temporal windowing required by many existing state of art trackers. Despite its simplicity, TAPNext achieves a new state-of-the-art tracking performance among both online and offline trackers. Finally, we present evidence that many widely used tracking heuristics emerge naturally in TAPNext through end-to-end training.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
TRecViT: A Recurrent Video Transformer
Dec 18, 2024We propose a novel block for video modelling. It relies on a time-space-channel factorisation with dedicated blocks for each dimension: gated linear recurrent units (LRUs) perform information mixing over time, self-attention layers perform mixing over space, and MLPs over channels. The resulting architecture TRecViT performs well on sparse and dense tasks, trained in supervised or self-supervised regimes. Notably, our model is causal and outperforms or is on par with a pure attention model ViViT-L on large scale video datasets (SSv2, Kinetics400), while having $3\times$ less parameters, $12\times$ smaller memory footprint, and $5\times$ lower FLOPs count. Code and checkpoints will be made available online at https://github.com/google-deepmind/trecvit.
Satellite Sunroof: High-res Digital Surface Models and Roof Segmentation for Global Solar Mapping
Aug 26, 2024



The transition to renewable energy, particularly solar, is key to mitigating climate change. Google's Solar API aids this transition by estimating solar potential from aerial imagery, but its impact is constrained by geographical coverage. This paper proposes expanding the API's reach using satellite imagery, enabling global solar potential assessment. We tackle challenges involved in building a Digital Surface Model (DSM) and roof instance segmentation from lower resolution and single oblique views using deep learning models. Our models, trained on aligned satellite and aerial datasets, produce 25cm DSMs and roof segments. With ~1m DSM MAE on buildings, ~5deg roof pitch error and ~56% IOU on roof segmentation, they significantly enhance the Solar API's potential to promote solar adoption.
BootsTAP: Bootstrapped Training for Tracking-Any-Point
Feb 01, 2024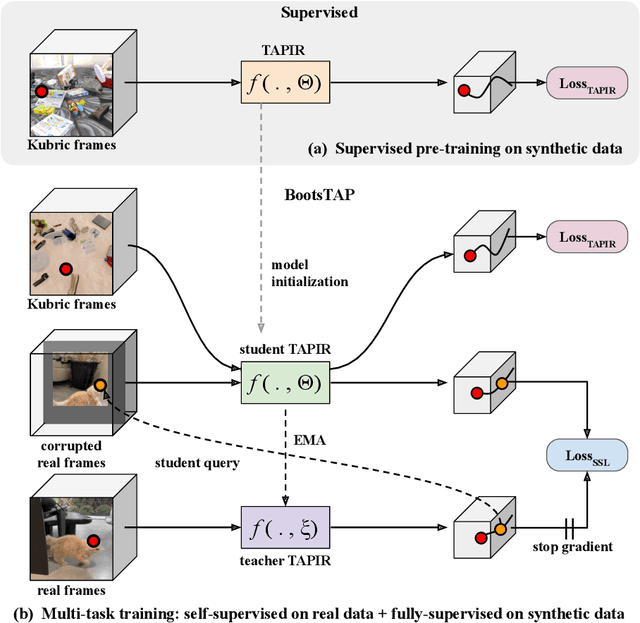
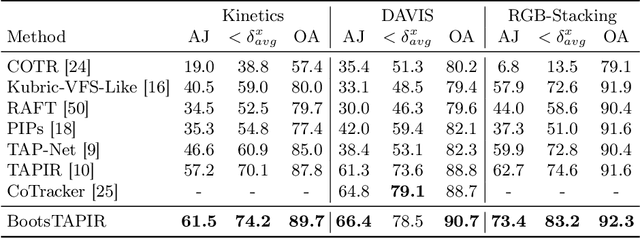
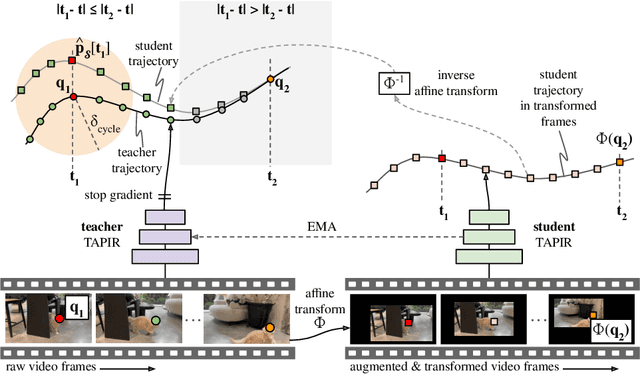
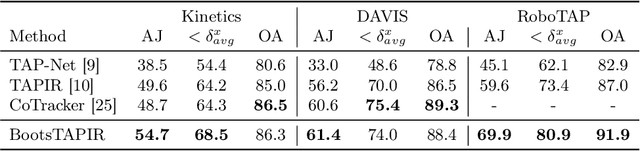
To endow models with greater understanding of physics and motion, it is useful to enable them to perceive how solid surfaces move and deform in real scenes. This can be formalized as Tracking-Any-Point (TAP), which requires the algorithm to be able to track any point corresponding to a solid surface in a video, potentially densely in space and time. Large-scale ground-truth training data for TAP is only available in simulation, which currently has limited variety of objects and motion. In this work, we demonstrate how large-scale, unlabeled, uncurated real-world data can improve a TAP model with minimal architectural changes, using a self-supervised student-teacher setup. We demonstrate state-of-the-art performance on the TAP-Vid benchmark surpassing previous results by a wide margin: for example, TAP-Vid-DAVIS performance improves from 61.3% to 66.4%, and TAP-Vid-Kinetics from 57.2% to 61.5%.
Course Correcting Koopman Representations
Oct 23, 2023



Koopman representations aim to learn features of nonlinear dynamical systems (NLDS) which lead to linear dynamics in the latent space. Theoretically, such features can be used to simplify many problems in modeling and control of NLDS. In this work we study autoencoder formulations of this problem, and different ways they can be used to model dynamics, specifically for future state prediction over long horizons. We discover several limitations of predicting future states in the latent space and propose an inference-time mechanism, which we refer to as Periodic Reencoding, for faithfully capturing long term dynamics. We justify this method both analytically and empirically via experiments in low and high dimensional NLDS.
Estimating Residential Solar Potential Using Aerial Data
Jun 23, 2023

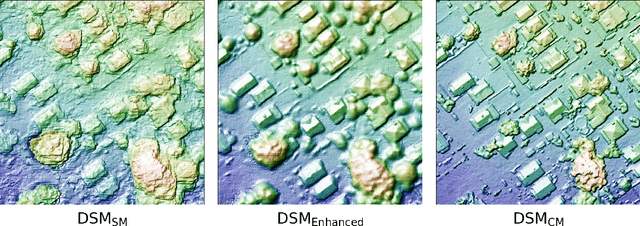

Project Sunroof estimates the solar potential of residential buildings using high quality aerial data. That is, it estimates the potential solar energy (and associated financial savings) that can be captured by buildings if solar panels were to be installed on their roofs. Unfortunately its coverage is limited by the lack of high resolution digital surface map (DSM) data. We present a deep learning approach that bridges this gap by enhancing widely available low-resolution data, thereby dramatically increasing the coverage of Sunroof. We also present some ongoing efforts to potentially improve accuracy even further by replacing certain algorithmic components of the Sunroof processing pipeline with deep learning.
Block-State Transformer
Jun 15, 2023State space models (SSMs) have shown impressive results on tasks that require modeling long-range dependencies and efficiently scale to long sequences owing to their subquadratic runtime complexity. Originally designed for continuous signals, SSMs have shown superior performance on a plethora of tasks, in vision and audio; however, SSMs still lag Transformer performance in Language Modeling tasks. In this work, we propose a hybrid layer named Block-State Transformer (BST), that internally combines an SSM sublayer for long-range contextualization, and a Block Transformer sublayer for short-term representation of sequences. We study three different, and completely parallelizable, variants that integrate SSMs and block-wise attention. We show that our model outperforms similar Transformer-based architectures on language modeling perplexity and generalizes to longer sequences. In addition, the Block-State Transformer demonstrates more than tenfold increase in speed at the layer level compared to the Block-Recurrent Transformer when model parallelization is employed.
Proto-Value Networks: Scaling Representation Learning with Auxiliary Tasks
Apr 25, 2023Auxiliary tasks improve the representations learned by deep reinforcement learning agents. Analytically, their effect is reasonably well understood; in practice, however, their primary use remains in support of a main learning objective, rather than as a method for learning representations. This is perhaps surprising given that many auxiliary tasks are defined procedurally, and hence can be treated as an essentially infinite source of information about the environment. Based on this observation, we study the effectiveness of auxiliary tasks for learning rich representations, focusing on the setting where the number of tasks and the size of the agent's network are simultaneously increased. For this purpose, we derive a new family of auxiliary tasks based on the successor measure. These tasks are easy to implement and have appealing theoretical properties. Combined with a suitable off-policy learning rule, the result is a representation learning algorithm that can be understood as extending Mahadevan & Maggioni (2007)'s proto-value functions to deep reinforcement learning -- accordingly, we call the resulting object proto-value networks. Through a series of experiments on the Arcade Learning Environment, we demonstrate that proto-value networks produce rich features that may be used to obtain performance comparable to established algorithms, using only linear approximation and a small number (~4M) of interactions with the environment's reward function.
Learned Image Compression for Machine Perception
Nov 03, 2021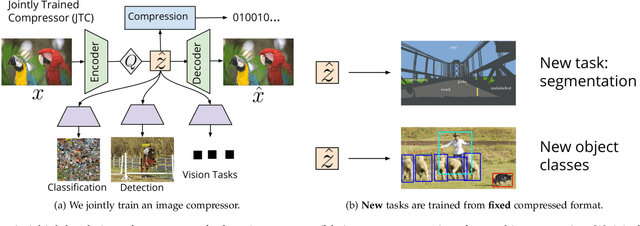
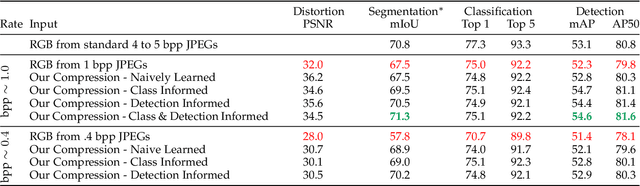
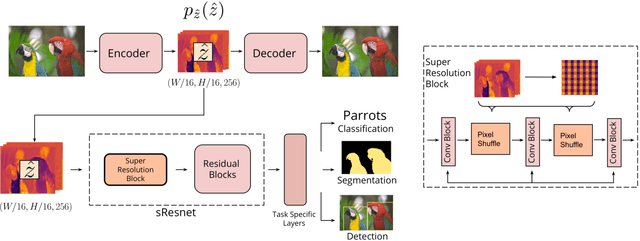

Recent work has shown that learned image compression strategies can outperform standard hand-crafted compression algorithms that have been developed over decades of intensive research on the rate-distortion trade-off. With growing applications of computer vision, high quality image reconstruction from a compressible representation is often a secondary objective. Compression that ensures high accuracy on computer vision tasks such as image segmentation, classification, and detection therefore has the potential for significant impact across a wide variety of settings. In this work, we develop a framework that produces a compression format suitable for both human perception and machine perception. We show that representations can be learned that simultaneously optimize for compression and performance on core vision tasks. Our approach allows models to be trained directly from compressed representations, and this approach yields increased performance on new tasks and in low-shot learning settings. We present results that improve upon segmentation and detection performance compared to standard high quality JPGs, but with representations that are four to ten times smaller in terms of bits per pixel. Further, unlike naive compression methods, at a level ten times smaller than standard JEPGs, segmentation and detection models trained from our format suffer only minor degradation in performance.