 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025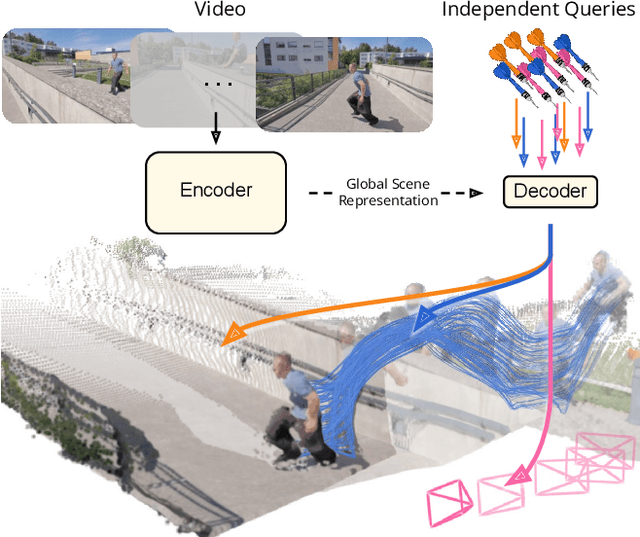

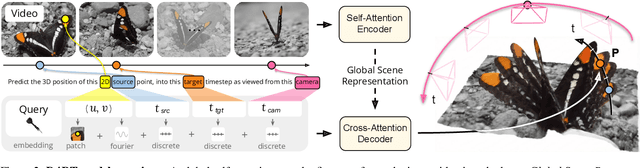
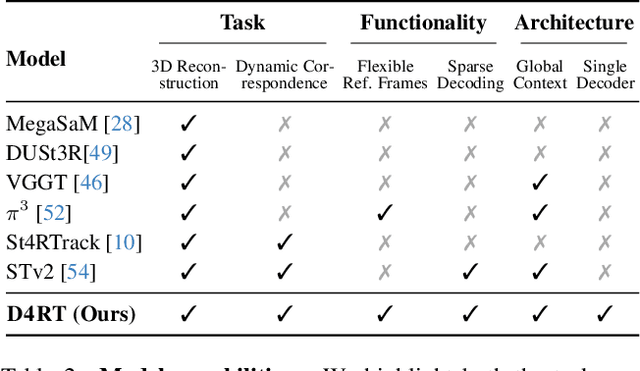
Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Interaction-Centric Knowledge Infusion and Transfer for Open-Vocabulary Scene Graph Generation
Nov 08, 2025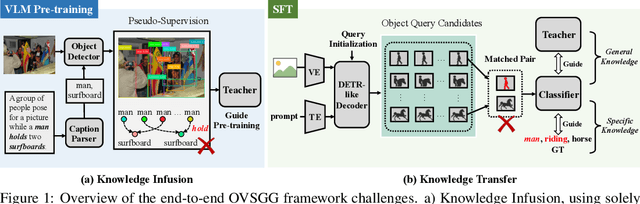
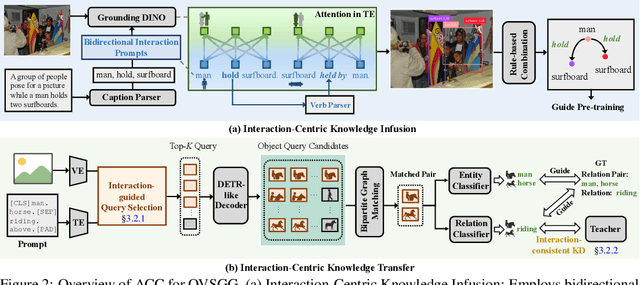
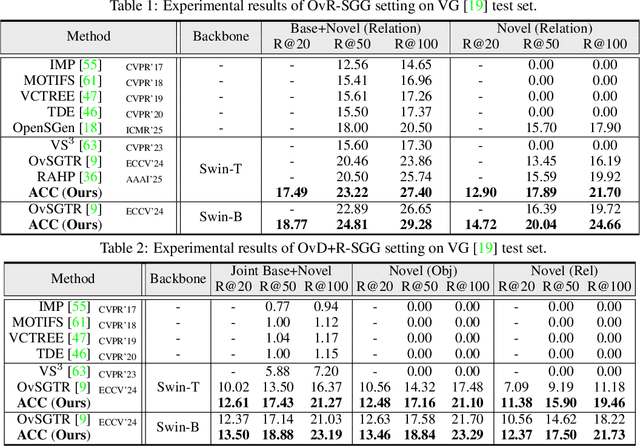
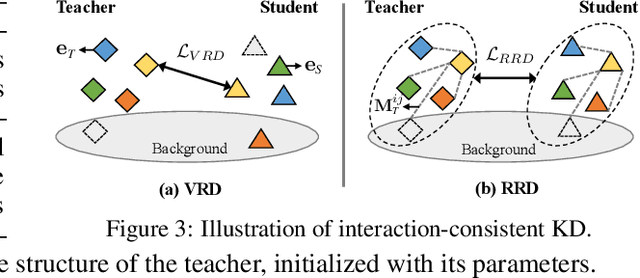
Open-vocabulary scene graph generation (OVSGG) extends traditional SGG by recognizing novel objects and relationships beyond predefined categories, leveraging the knowledge from pre-trained large-scale models. Existing OVSGG methods always adopt a two-stage pipeline: 1) \textit{Infusing knowledge} into large-scale models via pre-training on large datasets; 2) \textit{Transferring knowledge} from pre-trained models with fully annotated scene graphs during supervised fine-tuning. However, due to a lack of explicit interaction modeling, these methods struggle to distinguish between interacting and non-interacting instances of the same object category. This limitation induces critical issues in both stages of OVSGG: it generates noisy pseudo-supervision from mismatched objects during knowledge infusion, and causes ambiguous query matching during knowledge transfer. To this end, in this paper, we propose an inter\textbf{AC}tion-\textbf{C}entric end-to-end OVSGG framework (\textbf{ACC}) in an interaction-driven paradigm to minimize these mismatches. For \textit{interaction-centric knowledge infusion}, ACC employs a bidirectional interaction prompt for robust pseudo-supervision generation to enhance the model's interaction knowledge. For \textit{interaction-centric knowledge transfer}, ACC first adopts interaction-guided query selection that prioritizes pairing interacting objects to reduce interference from non-interacting ones. Then, it integrates interaction-consistent knowledge distillation to bolster robustness by pushing relational foreground away from the background while retaining general knowledge. Extensive experimental results on three benchmarks show that ACC achieves state-of-the-art performance, demonstrating the potential of interaction-centric paradigms for real-world applications.
NeuroBreak: Unveil Internal Jailbreak Mechanisms in Large Language Models
Sep 04, 2025In deployment and application, large language models (LLMs) typically undergo safety alignment to prevent illegal and unethical outputs. However, the continuous advancement of jailbreak attack techniques, designed to bypass safety mechanisms with adversarial prompts, has placed increasing pressure on the security defenses of LLMs. Strengthening resistance to jailbreak attacks requires an in-depth understanding of the security mechanisms and vulnerabilities of LLMs. However, the vast number of parameters and complex structure of LLMs make analyzing security weaknesses from an internal perspective a challenging task. This paper presents NeuroBreak, a top-down jailbreak analysis system designed to analyze neuron-level safety mechanisms and mitigate vulnerabilities. We carefully design system requirements through collaboration with three experts in the field of AI security. The system provides a comprehensive analysis of various jailbreak attack methods. By incorporating layer-wise representation probing analysis, NeuroBreak offers a novel perspective on the model's decision-making process throughout its generation steps. Furthermore, the system supports the analysis of critical neurons from both semantic and functional perspectives, facilitating a deeper exploration of security mechanisms. We conduct quantitative evaluations and case studies to verify the effectiveness of our system, offering mechanistic insights for developing next-generation defense strategies against evolving jailbreak attacks.
Learning from Streaming Video with Orthogonal Gradients
Apr 02, 2025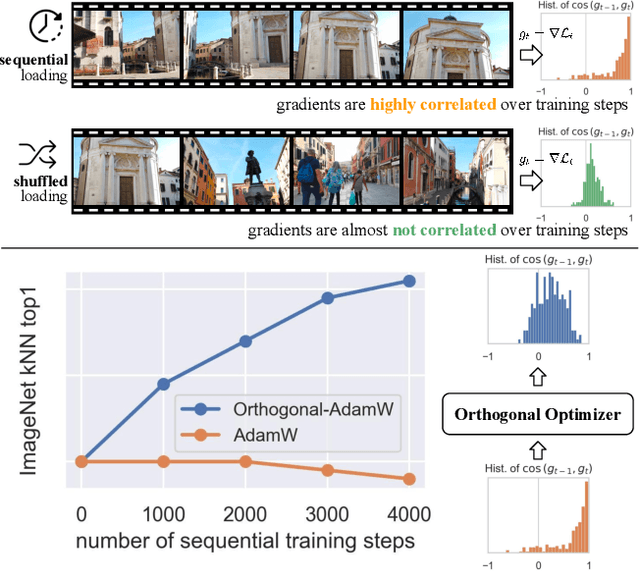
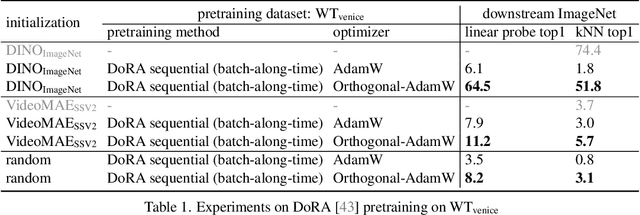
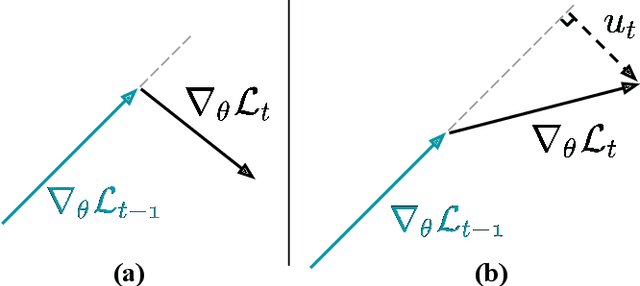
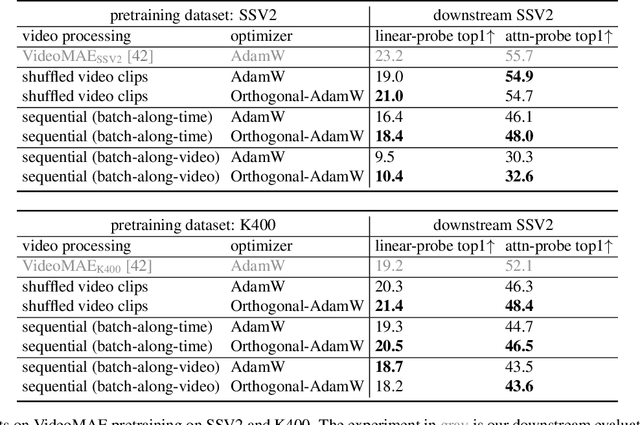
We address the challenge of representation learning from a continuous stream of video as input, in a self-supervised manner. This differs from the standard approaches to video learning where videos are chopped and shuffled during training in order to create a non-redundant batch that satisfies the independently and identically distributed (IID) sample assumption expected by conventional training paradigms. When videos are only available as a continuous stream of input, the IID assumption is evidently broken, leading to poor performance. We demonstrate the drop in performance when moving from shuffled to sequential learning on three tasks: the one-video representation learning method DoRA, standard VideoMAE on multi-video datasets, and the task of future video prediction. To address this drop, we propose a geometric modification to standard optimizers, to decorrelate batches by utilising orthogonal gradients during training. The proposed modification can be applied to any optimizer -- we demonstrate it with Stochastic Gradient Descent (SGD) and AdamW. Our proposed orthogonal optimizer allows models trained from streaming videos to alleviate the drop in representation learning performance, as evaluated on downstream tasks. On three scenarios (DoRA, VideoMAE, future prediction), we show our orthogonal optimizer outperforms the strong AdamW in all three scenarios.
Cyclic Contrastive Knowledge Transfer for Open-Vocabulary Object Detection
Mar 14, 2025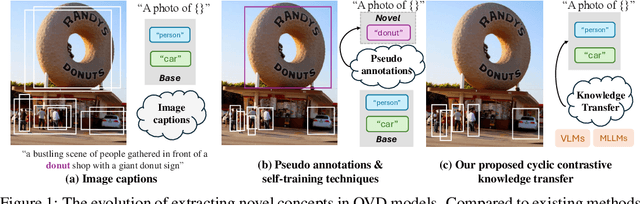

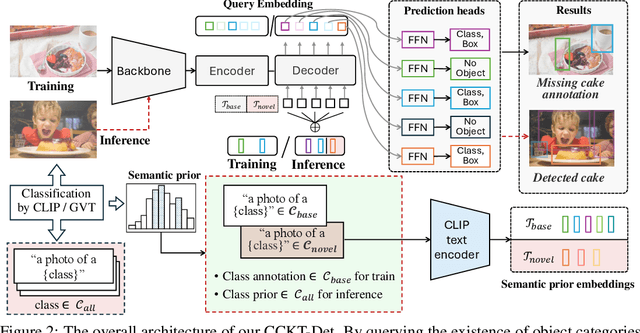

In pursuit of detecting unstinted objects that extend beyond predefined categories, prior arts of open-vocabulary object detection (OVD) typically resort to pretrained vision-language models (VLMs) for base-to-novel category generalization. However, to mitigate the misalignment between upstream image-text pretraining and downstream region-level perception, additional supervisions are indispensable, eg, image-text pairs or pseudo annotations generated via self-training strategies. In this work, we propose CCKT-Det trained without any extra supervision. The proposed framework constructs a cyclic and dynamic knowledge transfer from language queries and visual region features extracted from VLMs, which forces the detector to closely align with the visual-semantic space of VLMs. Specifically, 1) we prefilter and inject semantic priors to guide the learning of queries, and 2) introduce a regional contrastive loss to improve the awareness of queries on novel objects. CCKT-Det can consistently improve performance as the scale of VLMs increases, all while requiring the detector at a moderate level of computation overhead. Comprehensive experimental results demonstrate that our method achieves performance gain of +2.9% and +10.2% AP50 over previous state-of-the-arts on the challenging COCO benchmark, both without and with a stronger teacher model. The code is provided at https://github.com/ZCHUHan/CCKT-Det.
* 10 pages, 5 figures, Published as a conference paper at ICLR 2025
From Image to Video: An Empirical Study of Diffusion Representations
Feb 10, 2025Diffusion models have revolutionized generative modeling, enabling unprecedented realism in image and video synthesis. This success has sparked interest in leveraging their representations for visual understanding tasks. While recent works have explored this potential for image generation, the visual understanding capabilities of video diffusion models remain largely uncharted. To address this gap, we systematically compare the same model architecture trained for video versus image generation, analyzing the performance of their latent representations on various downstream tasks including image classification, action recognition, depth estimation, and tracking. Results show that video diffusion models consistently outperform their image counterparts, though we find a striking range in the extent of this superiority. We further analyze features extracted from different layers and with varying noise levels, as well as the effect of model size and training budget on representation and generation quality. This work marks the first direct comparison of video and image diffusion objectives for visual understanding, offering insights into the role of temporal information in representation learning.
Taking A Closer Look at Interacting Objects: Interaction-Aware Open Vocabulary Scene Graph Generation
Feb 06, 2025Today's open vocabulary scene graph generation (OVSGG) extends traditional SGG by recognizing novel objects and relationships beyond predefined categories, leveraging the knowledge from pre-trained large-scale models. Most existing methods adopt a two-stage pipeline: weakly supervised pre-training with image captions and supervised fine-tuning (SFT) on fully annotated scene graphs. Nonetheless, they omit explicit modeling of interacting objects and treat all objects equally, resulting in mismatched relation pairs. To this end, we propose an interaction-aware OVSGG framework INOVA. During pre-training, INOVA employs an interaction-aware target generation strategy to distinguish interacting objects from non-interacting ones. In SFT, INOVA devises an interaction-guided query selection tactic to prioritize interacting objects during bipartite graph matching. Besides, INOVA is equipped with an interaction-consistent knowledge distillation to enhance the robustness by pushing interacting object pairs away from the background. Extensive experiments on two benchmarks (VG and GQA) show that INOVA achieves state-of-the-art performance, demonstrating the potential of interaction-aware mechanisms for real-world applications.
ReSpark: Leveraging Previous Data Reports as References to Generate New Reports with LLMs
Feb 04, 2025Creating data reports is time-consuming, as it requires iterative exploration and understanding of data, followed by summarizing the insights. While large language models (LLMs) are powerful tools for data processing and text generation, they often struggle to produce complete data reports that fully meet user expectations. One significant challenge is effectively communicating the entire analysis logic to LLMs. Moreover, determining a comprehensive analysis logic can be mentally taxing for users. To address these challenges, we propose ReSpark, an LLM-based method that leverages existing data reports as references for creating new ones. Given a data table, ReSpark searches for similar-topic reports, parses them into interdependent segments corresponding to analytical objectives, and executes them with new data. It identifies inconsistencies and customizes the objectives, data transformations, and textual descriptions. ReSpark allows users to review real-time outputs, insert new objectives, and modify report content. Its effectiveness was evaluated through comparative and user studies.
SpikingSoft: A Spiking Neuron Controller for Bio-inspired Locomotion with Soft Snake Robots
Jan 31, 2025



Inspired by the dynamic coupling of moto-neurons and physical elasticity in animals, this work explores the possibility of generating locomotion gaits by utilizing physical oscillations in a soft snake by means of a low-level spiking neural mechanism. To achieve this goal, we introduce the Double Threshold Spiking neuron model with adjustable thresholds to generate varied output patterns. This neuron model can excite the natural dynamics of soft robotic snakes, and it enables distinct movements, such as turning or moving forward, by simply altering the neural thresholds. Finally, we demonstrate that our approach, termed SpikingSoft, naturally pairs and integrates with reinforcement learning. The high-level agent only needs to adjust the two thresholds to generate complex movement patterns, thus strongly simplifying the learning of reactive locomotion. Simulation results demonstrate that the proposed architecture significantly enhances the performance of the soft snake robot, enabling it to achieve target objectives with a 21.6% increase in success rate, a 29% reduction in time to reach the target, and smoother movements compared to the vanilla reinforcement learning controllers or Central Pattern Generator controller acting in torque space.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.