 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclic Contrastive Knowledge Transfer for Open-Vocabulary Object Detection
Paper and Code
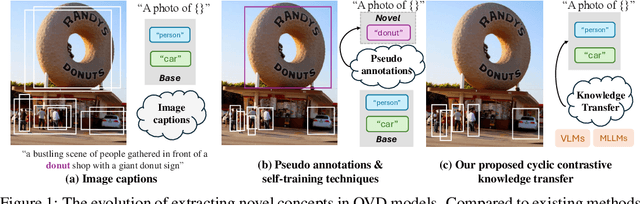

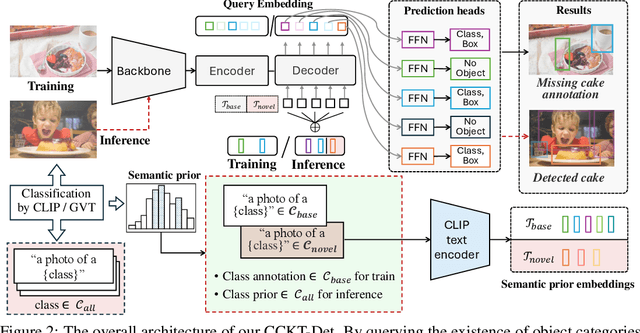

In pursuit of detecting unstinted objects that extend beyond predefined categories, prior arts of open-vocabulary object detection (OVD) typically resort to pretrained vision-language models (VLMs) for base-to-novel category generalization. However, to mitigate the misalignment between upstream image-text pretraining and downstream region-level perception, additional supervisions are indispensable, eg, image-text pairs or pseudo annotations generated via self-training strategies. In this work, we propose CCKT-Det trained without any extra supervision. The proposed framework constructs a cyclic and dynamic knowledge transfer from language queries and visual region features extracted from VLMs, which forces the detector to closely align with the visual-semantic space of VLMs. Specifically, 1) we prefilter and inject semantic priors to guide the learning of queries, and 2) introduce a regional contrastive loss to improve the awareness of queries on novel objects. CCKT-Det can consistently improve performance as the scale of VLMs increases, all while requiring the detector at a moderate level of computation overhead. Comprehensive experimental results demonstrate that our method achieves performance gain of +2.9% and +10.2% AP50 over previous state-of-the-arts on the challenging COCO benchmark, both without and with a stronger teacher model. The code is provided at https://github.com/ZCHUHan/CCKT-Det.