 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
TAPNext: Tracking Any Point (TAP) as Next Token Prediction
Apr 08, 2025Tracking Any Point (TAP) in a video is a challenging computer vision problem with many demonstrated applications in robotics, video editing, and 3D reconstruction. Existing methods for TAP rely heavily on complex tracking-specific inductive biases and heuristics, limiting their generality and potential for scaling. To address these challenges, we present TAPNext, a new approach that casts TAP as sequential masked token decoding. Our model is causal, tracks in a purely online fashion, and removes tracking-specific inductive biases. This enables TAPNext to run with minimal latency, and removes the temporal windowing required by many existing state of art trackers. Despite its simplicity, TAPNext achieves a new state-of-the-art tracking performance among both online and offline trackers. Finally, we present evidence that many widely used tracking heuristics emerge naturally in TAPNext through end-to-end training.
TRecViT: A Recurrent Video Transformer
Dec 18, 2024We propose a novel block for video modelling. It relies on a time-space-channel factorisation with dedicated blocks for each dimension: gated linear recurrent units (LRUs) perform information mixing over time, self-attention layers perform mixing over space, and MLPs over channels. The resulting architecture TRecViT performs well on sparse and dense tasks, trained in supervised or self-supervised regimes. Notably, our model is causal and outperforms or is on par with a pure attention model ViViT-L on large scale video datasets (SSv2, Kinetics400), while having $3\times$ less parameters, $12\times$ smaller memory footprint, and $5\times$ lower FLOPs count. Code and checkpoints will be made available online at https://github.com/google-deepmind/trecvit.
Unraveling the Complexity of Memory in RL Agents: an Approach for Classification and Evaluation
Dec 09, 2024



The incorporation of memory into agents is essential for numerous tasks within the domain of Reinforcement Learning (RL). In particular, memory is paramount for tasks that require the utilization of past information, adaptation to novel environments, and improved sample efficiency. However, the term ``memory'' encompasses a wide range of concepts, which, coupled with the lack of a unified methodology for validating an agent's memory, leads to erroneous judgments about agents' memory capabilities and prevents objective comparison with other memory-enhanced agents. This paper aims to streamline the concept of memory in RL by providing practical precise definitions of agent memory types, such as long-term versus short-term memory and declarative versus procedural memory, inspired by cognitive science. Using these definitions, we categorize different classes of agent memory, propose a robust experimental methodology for evaluating the memory capabilities of RL agents, and standardize evaluations. Furthermore, we empirically demonstrate the importance of adhering to the proposed methodology when evaluating different types of agent memory by conducting experiments with different RL agents and what its violation leads to.
Interpretability in Action: Exploratory Analysis of VPT, a Minecraft Agent
Jul 16, 2024Understanding the mechanisms behind decisions taken by large foundation models in sequential decision making tasks is critical to ensuring that such systems operate transparently and safely. In this work, we perform exploratory analysis on the Video PreTraining (VPT) Minecraft playing agent, one of the largest open-source vision-based agents. We aim to illuminate its reasoning mechanisms by applying various interpretability techniques. First, we analyze the attention mechanism while the agent solves its training task - crafting a diamond pickaxe. The agent pays attention to the last four frames and several key-frames further back in its six-second memory. This is a possible mechanism for maintaining coherence in a task that takes 3-10 minutes, despite the short memory span. Secondly, we perform various interventions, which help us uncover a worrying case of goal misgeneralization: VPT mistakenly identifies a villager wearing brown clothes as a tree trunk when the villager is positioned stationary under green tree leaves, and punches it to death.
IDAT: A Multi-Modal Dataset and Toolkit for Building and Evaluating Interactive Task-Solving Agents
Jul 12, 2024



Seamless interaction between AI agents and humans using natural language remains a key goal in AI research. This paper addresses the challenges of developing interactive agents capable of understanding and executing grounded natural language instructions through the IGLU competition at NeurIPS. Despite advancements, challenges such as a scarcity of appropriate datasets and the need for effective evaluation platforms persist. We introduce a scalable data collection tool for gathering interactive grounded language instructions within a Minecraft-like environment, resulting in a Multi-Modal dataset with around 9,000 utterances and over 1,000 clarification questions. Additionally, we present a Human-in-the-Loop interactive evaluation platform for qualitative analysis and comparison of agent performance through multi-turn communication with human annotators. We offer to the community these assets referred to as IDAT (IGLU Dataset And Toolkit) which aim to advance the development of intelligent, interactive AI agents and provide essential resources for further research.
BindGPT: A Scalable Framework for 3D Molecular Design via Language Modeling and Reinforcement Learning
Jun 06, 2024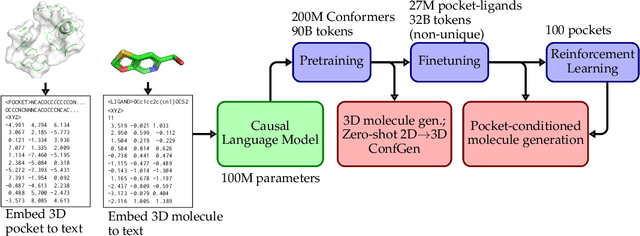
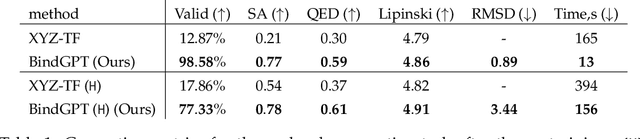
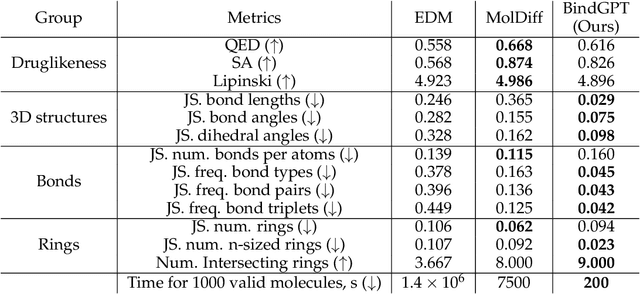
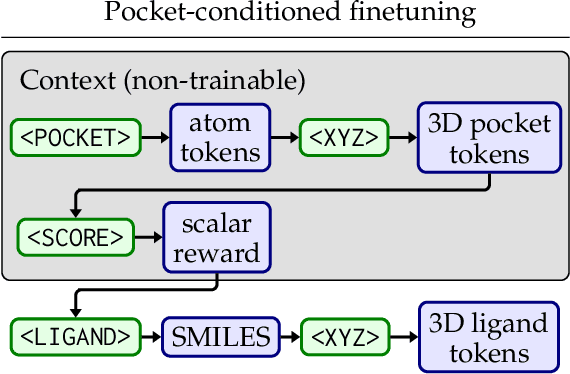
Generating novel active molecules for a given protein is an extremely challenging task for generative models that requires an understanding of the complex physical interactions between the molecule and its environment. In this paper, we present a novel generative model, BindGPT which uses a conceptually simple but powerful approach to create 3D molecules within the protein's binding site. Our model produces molecular graphs and conformations jointly, eliminating the need for an extra graph reconstruction step. We pretrain BindGPT on a large-scale dataset and fine-tune it with reinforcement learning using scores from external simulation software. We demonstrate how a single pretrained language model can serve at the same time as a 3D molecular generative model, conformer generator conditioned on the molecular graph, and a pocket-conditioned 3D molecule generator. Notably, the model does not make any representational equivariance assumptions about the domain of generation. We show how such simple conceptual approach combined with pretraining and scaling can perform on par or better than the current best specialized diffusion models, language models, and graph neural networks while being two orders of magnitude cheaper to sample.
Mastering Memory Tasks with World Models
Mar 07, 2024Current model-based reinforcement learning (MBRL) agents struggle with long-term dependencies. This limits their ability to effectively solve tasks involving extended time gaps between actions and outcomes, or tasks demanding the recalling of distant observations to inform current actions. To improve temporal coherence, we integrate a new family of state space models (SSMs) in world models of MBRL agents to present a new method, Recall to Imagine (R2I). This integration aims to enhance both long-term memory and long-horizon credit assignment. Through a diverse set of illustrative tasks, we systematically demonstrate that R2I not only establishes a new state-of-the-art for challenging memory and credit assignment RL tasks, such as BSuite and POPGym, but also showcases superhuman performance in the complex memory domain of Memory Maze. At the same time, it upholds comparable performance in classic RL tasks, such as Atari and DMC, suggesting the generality of our method. We also show that R2I is faster than the state-of-the-art MBRL method, DreamerV3, resulting in faster wall-time convergence.
Transforming Human-Centered AI Collaboration: Redefining Embodied Agents Capabilities through Interactive Grounded Language Instructions
May 18, 2023



Human intelligence's adaptability is remarkable, allowing us to adjust to new tasks and multi-modal environments swiftly. This skill is evident from a young age as we acquire new abilities and solve problems by imitating others or following natural language instructions. The research community is actively pursuing the development of interactive "embodied agents" that can engage in natural conversations with humans and assist them with real-world tasks. These agents must possess the ability to promptly request feedback in case communication breaks down or instructions are unclear. Additionally, they must demonstrate proficiency in learning new vocabulary specific to a given domain. In this paper, we made the following contributions: (1) a crowd-sourcing tool for collecting grounded language instructions; (2) the largest dataset of grounded language instructions; and (3) several state-of-the-art baselines. These contributions are suitable as a foundation for further research.
Collecting Interactive Multi-modal Datasets for Grounded Language Understanding
Nov 18, 2022


Human intelligence can remarkably adapt quickly to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research which can enable similar capabilities in machines, we made the following contributions (1) formalized the collaborative embodied agent using natural language task; (2) developed a tool for extensive and scalable data collection; and (3) collected the first dataset for interactive grounded language understanding.