 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Context Gaps: Enhancing Comprehension in Long-Form Social Conversations Through Contextualized Excerpts
Dec 28, 2024We focus on enhancing comprehension in small-group recorded conversations, which serve as a medium to bring people together and provide a space for sharing personal stories and experiences on crucial social matters. One way to parse and convey information from these conversations is by sharing highlighted excerpts in subsequent conversations. This can help promote a collective understanding of relevant issues, by highlighting perspectives and experiences to other groups of people who might otherwise be unfamiliar with and thus unable to relate to these experiences. The primary challenge that arises then is that excerpts taken from one conversation and shared in another setting might be missing crucial context or key elements that were previously introduced in the original conversation. This problem is exacerbated when conversations become lengthier and richer in themes and shared experiences. To address this, we explore how Large Language Models (LLMs) can enrich these excerpts by providing socially relevant context. We present approaches for effective contextualization to improve comprehension, readability, and empathy. We show significant improvements in understanding, as assessed through subjective and objective evaluations. While LLMs can offer valuable context, they struggle with capturing key social aspects. We release the Human-annotated Salient Excerpts (HSE) dataset to support future work. Additionally, we show how context-enriched excerpts can provide more focused and comprehensive conversation summaries.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
On the Relationship between Truth and Political Bias in Language Models
Sep 09, 2024



Language model alignment research often attempts to ensure that models are not only helpful and harmless, but also truthful and unbiased. However, optimizing these objectives simultaneously can obscure how improving one aspect might impact the others. In this work, we focus on analyzing the relationship between two concepts essential in both language model alignment and political science: \textit{truthfulness} and \textit{political bias}. We train reward models on various popular truthfulness datasets and subsequently evaluate their political bias. Our findings reveal that optimizing reward models for truthfulness on these datasets tends to result in a left-leaning political bias. We also find that existing open-source reward models (i.e. those trained on standard human preference datasets) already show a similar bias and that the bias is larger for larger models. These results raise important questions about both the datasets used to represent truthfulness and what language models capture about the relationship between truth and politics.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


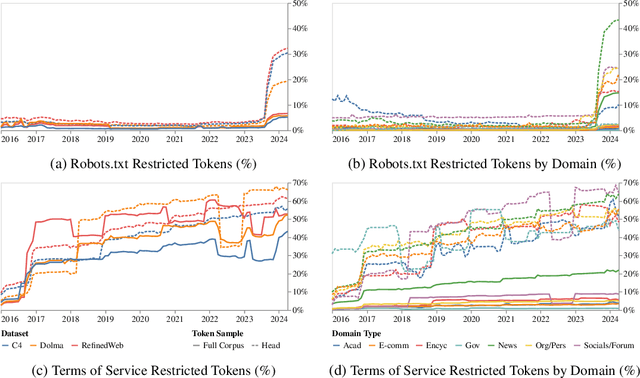
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
IDAT: A Multi-Modal Dataset and Toolkit for Building and Evaluating Interactive Task-Solving Agents
Jul 12, 2024



Seamless interaction between AI agents and humans using natural language remains a key goal in AI research. This paper addresses the challenges of developing interactive agents capable of understanding and executing grounded natural language instructions through the IGLU competition at NeurIPS. Despite advancements, challenges such as a scarcity of appropriate datasets and the need for effective evaluation platforms persist. We introduce a scalable data collection tool for gathering interactive grounded language instructions within a Minecraft-like environment, resulting in a Multi-Modal dataset with around 9,000 utterances and over 1,000 clarification questions. Additionally, we present a Human-in-the-Loop interactive evaluation platform for qualitative analysis and comparison of agent performance through multi-turn communication with human annotators. We offer to the community these assets referred to as IDAT (IGLU Dataset And Toolkit) which aim to advance the development of intelligent, interactive AI agents and provide essential resources for further research.
Transforming Human-Centered AI Collaboration: Redefining Embodied Agents Capabilities through Interactive Grounded Language Instructions
May 18, 2023



Human intelligence's adaptability is remarkable, allowing us to adjust to new tasks and multi-modal environments swiftly. This skill is evident from a young age as we acquire new abilities and solve problems by imitating others or following natural language instructions. The research community is actively pursuing the development of interactive "embodied agents" that can engage in natural conversations with humans and assist them with real-world tasks. These agents must possess the ability to promptly request feedback in case communication breaks down or instructions are unclear. Additionally, they must demonstrate proficiency in learning new vocabulary specific to a given domain. In this paper, we made the following contributions: (1) a crowd-sourcing tool for collecting grounded language instructions; (2) the largest dataset of grounded language instructions; and (3) several state-of-the-art baselines. These contributions are suitable as a foundation for further research.
Collecting Interactive Multi-modal Datasets for Grounded Language Understanding
Nov 18, 2022


Human intelligence can remarkably adapt quickly to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research which can enable similar capabilities in machines, we made the following contributions (1) formalized the collaborative embodied agent using natural language task; (2) developed a tool for extensive and scalable data collection; and (3) collected the first dataset for interactive grounded language understanding.
Learning to Solve Voxel Building Embodied Tasks from Pixels and Natural Language Instructions
Nov 01, 2022The adoption of pre-trained language models to generate action plans for embodied agents is a promising research strategy. However, execution of instructions in real or simulated environments requires verification of the feasibility of actions as well as their relevance to the completion of a goal. We propose a new method that combines a language model and reinforcement learning for the task of building objects in a Minecraft-like environment according to the natural language instructions. Our method first generates a set of consistently achievable sub-goals from the instructions and then completes associated sub-tasks with a pre-trained RL policy. The proposed method formed the RL baseline at the IGLU 2022 competition.
IGLU Gridworld: Simple and Fast Environment for Embodied Dialog Agents
May 31, 2022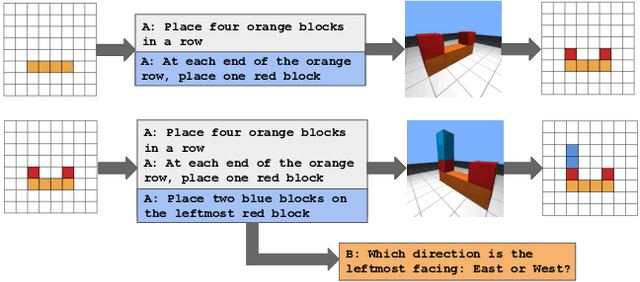

We present the IGLU Gridworld: a reinforcement learning environment for building and evaluating language conditioned embodied agents in a scalable way. The environment features visual agent embodiment, interactive learning through collaboration, language conditioned RL, and combinatorically hard task (3d blocks building) space.
IGLU 2022: Interactive Grounded Language Understanding in a Collaborative Environment at NeurIPS 2022
May 27, 2022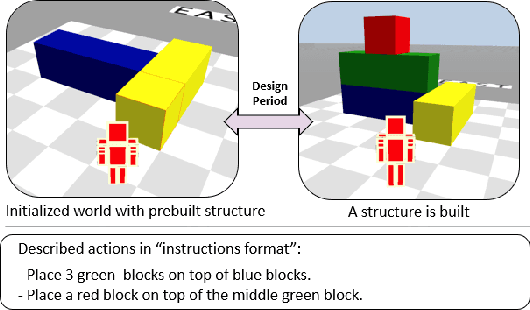

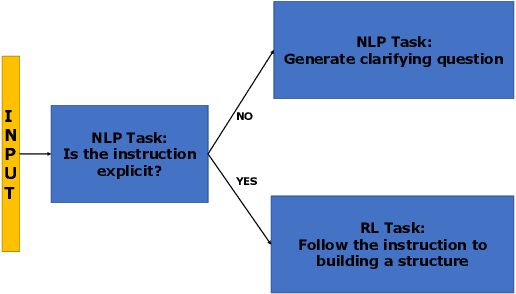
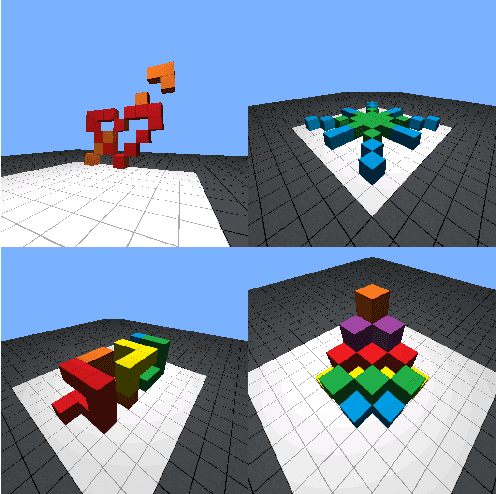
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to develop interactive embodied agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the crucial challenges in AI. Another critical aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.