 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Large Language Models to Characterize Public Narratives
Nov 17, 2025
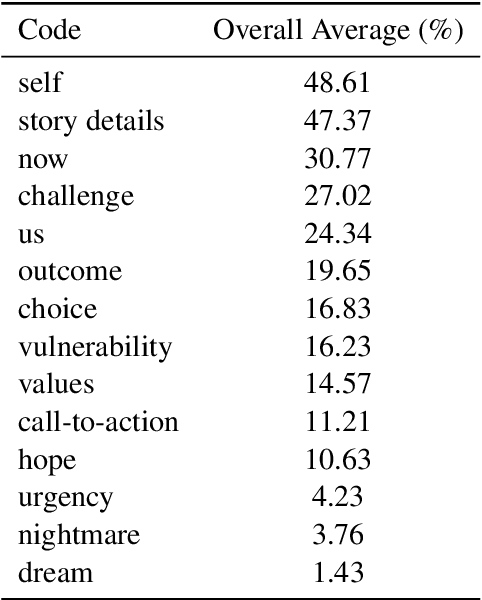

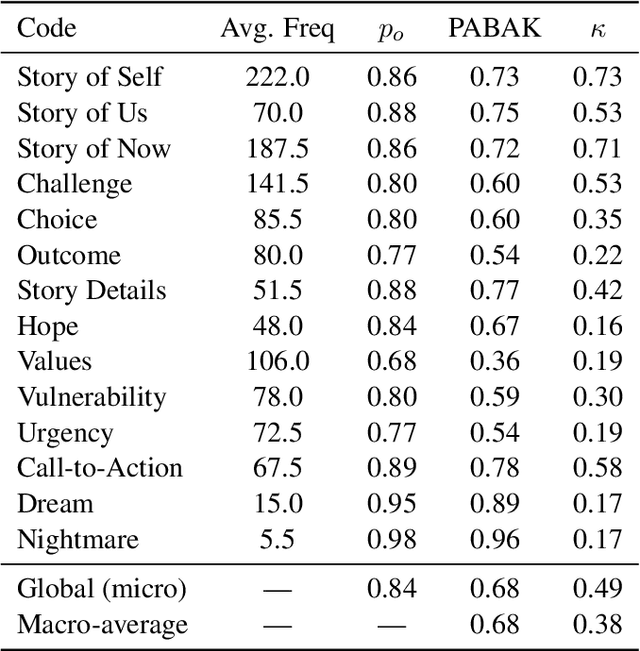
Public Narratives (PNs) are key tools for leadership development and civic mobilization, yet their systematic analysis remains challenging due to their subjective interpretation and the high cost of expert annotation. In this work, we propose a novel computational framework that leverages large language models (LLMs) to automate the qualitative annotation of public narratives. Using a codebook we co-developed with subject-matter experts, we evaluate LLM performance against that of expert annotators. Our work reveals that LLMs can achieve near-human-expert performance, achieving an average F1 score of 0.80 across 8 narratives and 14 codes. We then extend our analysis to empirically explore how PN framework elements manifest across a larger dataset of 22 stories. Lastly, we extrapolate our analysis to a set of political speeches, establishing a novel lens in which to analyze political rhetoric in civic spaces. This study demonstrates the potential of LLM-assisted annotation for scalable narrative analysis and highlights key limitations and directions for future research in computational civic storytelling.
On the Relationship between Truth and Political Bias in Language Models
Sep 09, 2024



Language model alignment research often attempts to ensure that models are not only helpful and harmless, but also truthful and unbiased. However, optimizing these objectives simultaneously can obscure how improving one aspect might impact the others. In this work, we focus on analyzing the relationship between two concepts essential in both language model alignment and political science: \textit{truthfulness} and \textit{political bias}. We train reward models on various popular truthfulness datasets and subsequently evaluate their political bias. Our findings reveal that optimizing reward models for truthfulness on these datasets tends to result in a left-leaning political bias. We also find that existing open-source reward models (i.e. those trained on standard human preference datasets) already show a similar bias and that the bias is larger for larger models. These results raise important questions about both the datasets used to represent truthfulness and what language models capture about the relationship between truth and politics.
LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users
Jun 25, 2024While state-of-the-art Large Language Models (LLMs) have shown impressive performance on many tasks, there has been extensive research on undesirable model behavior such as hallucinations and bias. In this work, we investigate how the quality of LLM responses changes in terms of information accuracy, truthfulness, and refusals depending on three user traits: English proficiency, education level, and country of origin. We present extensive experimentation on three state-of-the-art LLMs and two different datasets targeting truthfulness and factuality. Our findings suggest that undesirable behaviors in state-of-the-art LLMs occur disproportionately more for users with lower English proficiency, of lower education status, and originating from outside the US, rendering these models unreliable sources of information towards their most vulnerable users.
Are Diffusion Models Vision-And-Language Reasoners?
May 25, 2023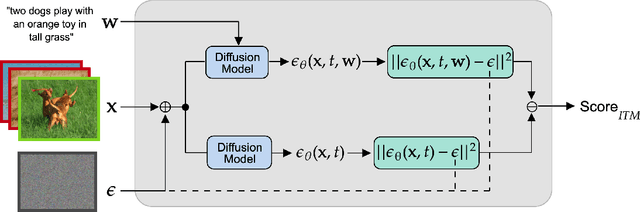
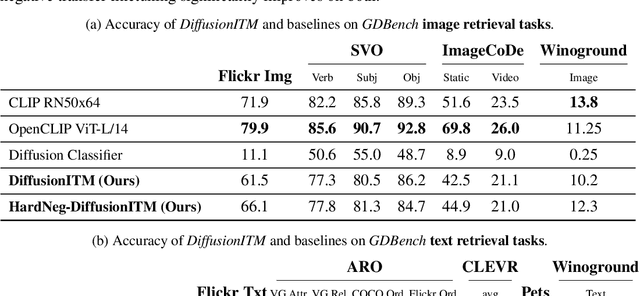
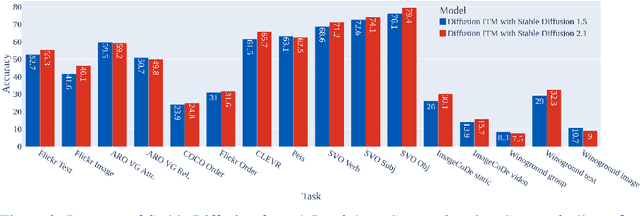
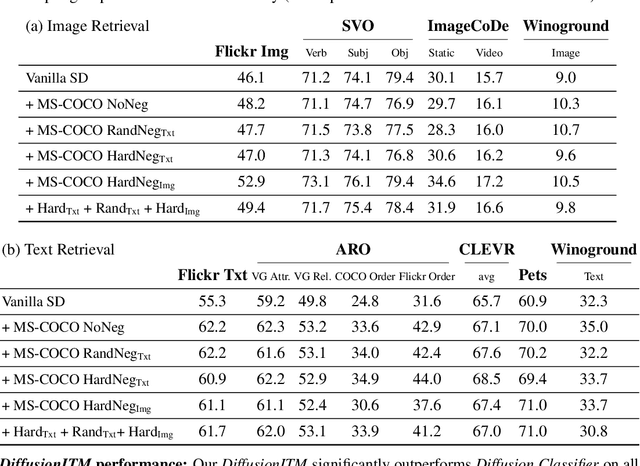
Text-conditioned image generation models have recently shown immense qualitative success using denoising diffusion processes. However, unlike discriminative vision-and-language models, it is a non-trivial task to subject these diffusion-based generative models to automatic fine-grained quantitative evaluation of high-level phenomena such as compositionality. Towards this goal, we perform two innovations. First, we transform diffusion-based models (in our case, Stable Diffusion) for any image-text matching (ITM) task using a novel method called DiffusionITM. Second, we introduce the Generative-Discriminative Evaluation Benchmark (GDBench) benchmark with 7 complex vision-and-language tasks, bias evaluation and detailed analysis. We find that Stable Diffusion + DiffusionITM is competitive on many tasks and outperforms CLIP on compositional tasks like like CLEVR and Winoground. We further boost its compositional performance with a transfer setup by fine-tuning on MS-COCO while retaining generative capabilities. We also measure the stereotypical bias in diffusion models, and find that Stable Diffusion 2.1 is, for the most part, less biased than Stable Diffusion 1.5. Overall, our results point in an exciting direction bringing discriminative and generative model evaluation closer. We will release code and benchmark setup soon.
An Empirical Survey of the Effectiveness of Debiasing Techniques for Pre-Trained Language Models
Oct 16, 2021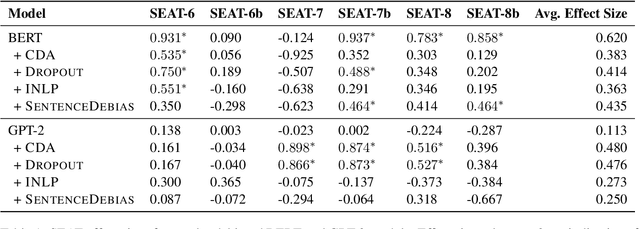
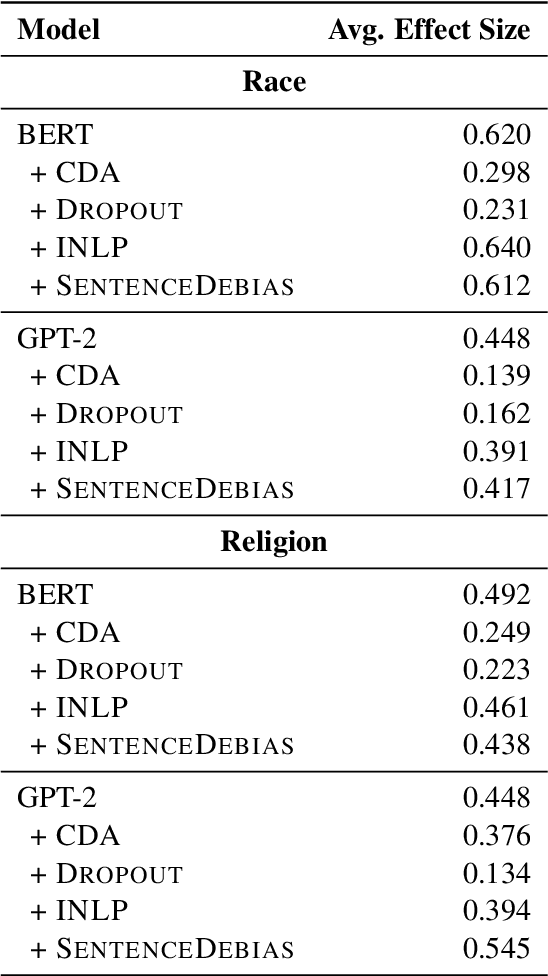
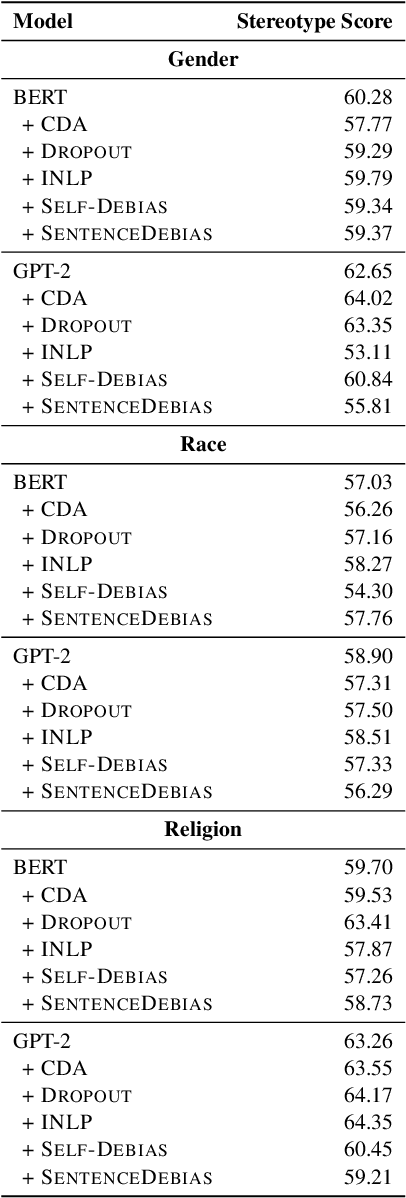
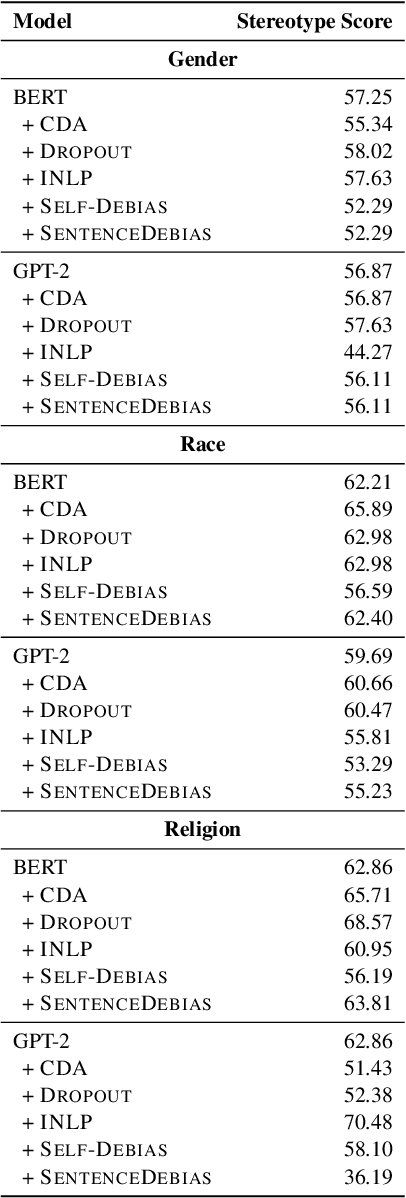
Recent work has shown that pre-trained language models capture social biases from the text corpora they are trained on. This has attracted attention to developing techniques that mitigate such biases. In this work, we perform a empirical survey of five recently proposed debiasing techniques: Counterfactual Data Augmentation (CDA), Dropout, Iterative Nullspace Projection, Self-Debias, and SentenceDebias. We quantify the effectiveness of each technique using three different bias benchmarks while also measuring the impact of these techniques on a model's language modeling ability, as well as its performance on downstream NLU tasks. We experimentally find that: (1) CDA and Self-Debias are the strongest of the debiasing techniques, obtaining improved scores on most of the bias benchmarks (2) Current debiasing techniques do not generalize well beyond gender bias; And (3) improvements on bias benchmarks such as StereoSet and CrowS-Pairs by using debiasing strategies are usually accompanied by a decrease in language modeling ability, making it difficult to determine whether the bias mitigation is effective.