 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Survey of the Effectiveness of Debiasing Techniques for Pre-Trained Language Models
Paper and Code
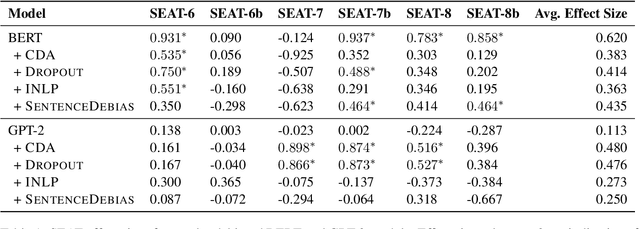
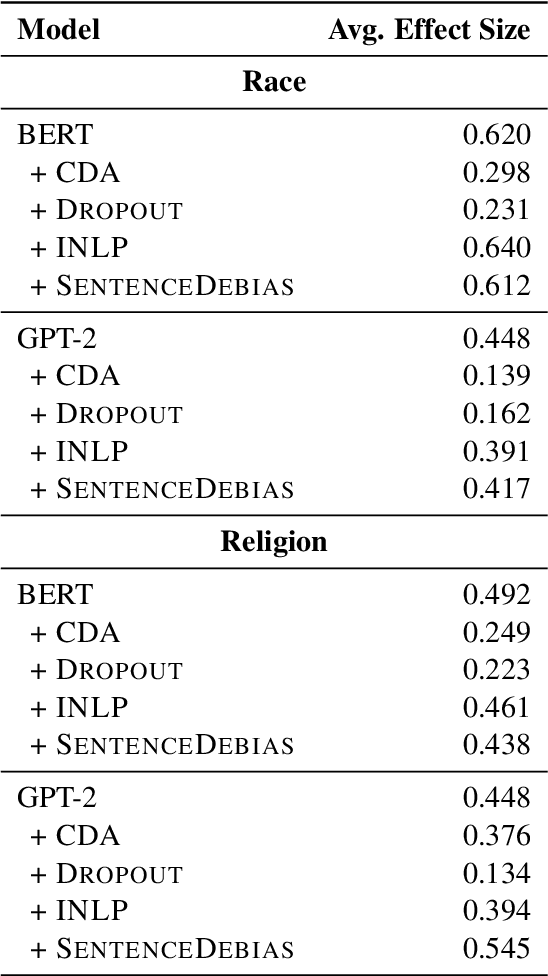
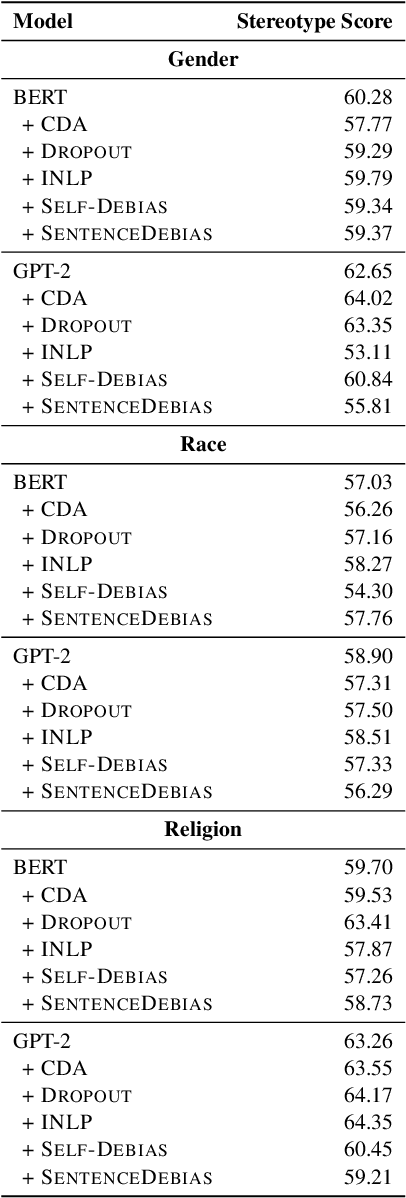
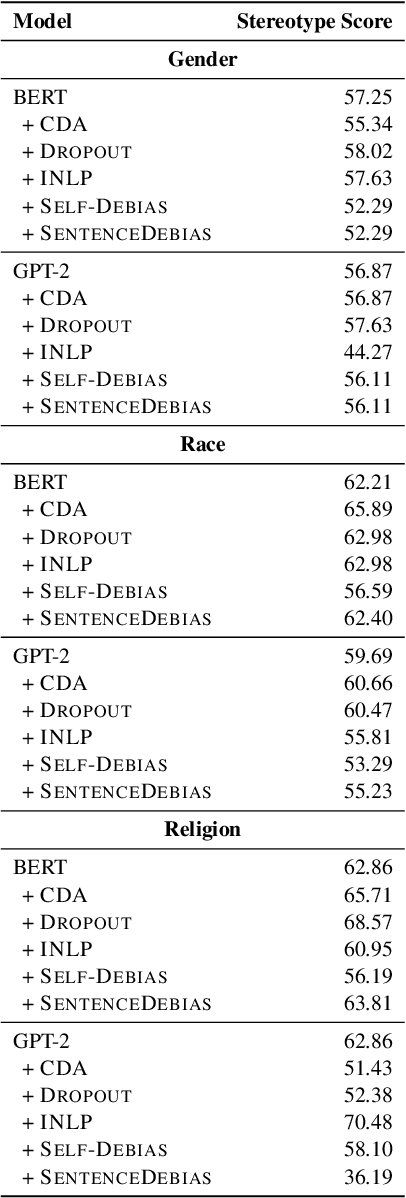
Recent work has shown that pre-trained language models capture social biases from the text corpora they are trained on. This has attracted attention to developing techniques that mitigate such biases. In this work, we perform a empirical survey of five recently proposed debiasing techniques: Counterfactual Data Augmentation (CDA), Dropout, Iterative Nullspace Projection, Self-Debias, and SentenceDebias. We quantify the effectiveness of each technique using three different bias benchmarks while also measuring the impact of these techniques on a model's language modeling ability, as well as its performance on downstream NLU tasks. We experimentally find that: (1) CDA and Self-Debias are the strongest of the debiasing techniques, obtaining improved scores on most of the bias benchmarks (2) Current debiasing techniques do not generalize well beyond gender bias; And (3) improvements on bias benchmarks such as StereoSet and CrowS-Pairs by using debiasing strategies are usually accompanied by a decrease in language modeling ability, making it difficult to determine whether the bias mitigation is effective.