 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWould you still call this Dax? Novel Visual References in VLMs and Humans
Jun 03, 2026Vision-language models (VLMs), like human learners, are frequently exposed to new visual concepts, but how they map novel visual references to language after exposure remains largely underexplored, particularly when those references contradict prior knowledge from pre-training. To study this, we present the Novel Visual References Dataset (NVRD): 19,176 images spanning 90 visual concepts across different levels of visual novelty, each with up to 20 increasingly perturbed versions of the original object to probe generalization. Unlike prior work on visual augmentations of familiar concepts, NVRD comprises entirely novel, open-ended stimuli constructed from scratch, mirroring how humans encounter genuinely new concepts. We evaluate 3 open- and 2 closed-source models alongside 2,400 human judgments for direct human-model comparison, and find that (i) models struggle to acquire novel concepts in-context when they contradict prior knowledge, and (ii) while models and humans show correlated sensitivity to visual perturbations, models significantly overgeneralize, extending learned labels to stimuli that humans reject. We contribute NVRD as a corpus and benchmark for research on visual concept learning in both humans and machines.
LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs
Jan 31, 2026Transforming a large language model (LLM) into a Vision-Language Model (VLM) can be achieved by mapping the visual tokens from a vision encoder into the embedding space of an LLM. Intriguingly, this mapping can be as simple as a shallow MLP transformation. To understand why LLMs can so readily process visual tokens, we need interpretability methods that reveal what is encoded in the visual token representations at every layer of LLM processing. In this work, we introduce LatentLens, a novel approach for mapping latent representations to descriptions in natural language. LatentLens works by encoding a large text corpus and storing contextualized token representations for each token in that corpus. Visual token representations are then compared to their contextualized textual representations, with the top-k nearest neighbor representations providing descriptions of the visual token. We evaluate this method on 10 different VLMs, showing that commonly used methods, such as LogitLens, substantially underestimate the interpretability of visual tokens. With LatentLens instead, the majority of visual tokens are interpretable across all studied models and all layers. Qualitatively, we show that the descriptions produced by LatentLens are semantically meaningful and provide more fine-grained interpretations for humans compared to individual tokens. More broadly, our findings contribute new evidence on the alignment between vision and language representations, opening up new directions for analyzing latent representations.
A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs
Jun 11, 2025



Existing benchmarks for assessing the spatio-temporal understanding and reasoning abilities of video language models are susceptible to score inflation due to the presence of shortcut solutions based on superficial visual or textual cues. This paper mitigates the challenges in accurately assessing model performance by introducing the Minimal Video Pairs (MVP) benchmark, a simple shortcut-aware video QA benchmark for assessing the physical understanding of video language models. The benchmark is comprised of 55K high-quality multiple-choice video QA examples focusing on physical world understanding. Examples are curated from nine video data sources, spanning first-person egocentric and exocentric videos, robotic interaction data, and cognitive science intuitive physics benchmarks. To mitigate shortcut solutions that rely on superficial visual or textual cues and biases, each sample in MVP has a minimal-change pair -- a visually similar video accompanied by an identical question but an opposing answer. To answer a question correctly, a model must provide correct answers for both examples in the minimal-change pair; as such, models that solely rely on visual or textual biases would achieve below random performance. Human performance on MVP is 92.9\%, while the best open-source state-of-the-art video-language model achieves 40.2\% compared to random performance at 25\%.
Learning Action and Reasoning-Centric Image Editing from Videos and Simulations
Jul 03, 2024
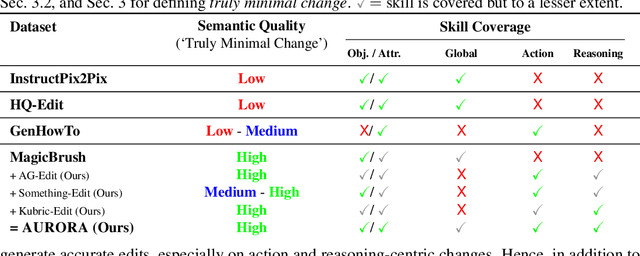
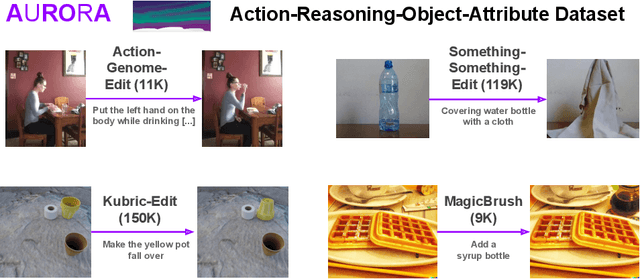

An image editing model should be able to perform diverse edits, ranging from object replacement, changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current general instruction-guided editing models have significant shortcomings with action and reasoning-centric edits. Object, attribute or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality and spatial reasoning. To this end, we meticulously curate the AURORA Dataset (Action-Reasoning-Object-Attribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines. We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., truly minimal changes between source and target images. To demonstrate the value of our dataset, we evaluate an AURORA-finetuned model on a new expert-curated benchmark (AURORA-Bench) covering 8 diverse editing tasks. Our model significantly outperforms previous editing models as judged by human raters. For automatic evaluations, we find important flaws in previous metrics and caution their use for semantically hard editing tasks. Instead, we propose a new automatic metric that focuses on discriminative understanding. We hope that our efforts : (1) curating a quality training dataset and an evaluation benchmark, (2) developing critical evaluations, and (3) releasing a state-of-the-art model, will fuel further progress on general image editing.
Improving Automatic VQA Evaluation Using Large Language Models
Oct 04, 2023
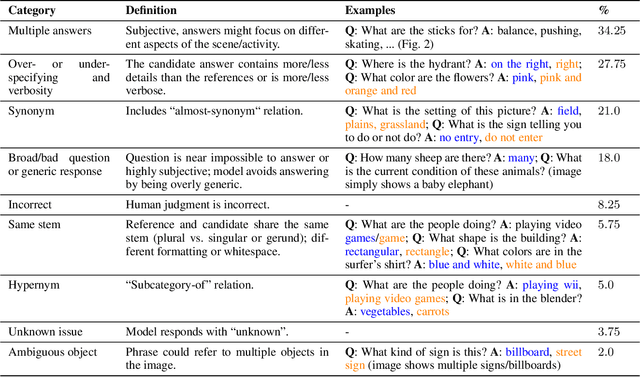

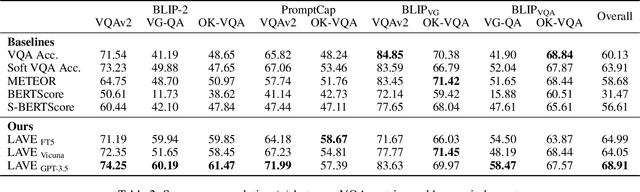
8 years after the visual question answering (VQA) task was proposed, accuracy remains the primary metric for automatic evaluation. VQA Accuracy has been effective so far in the IID evaluation setting. However, our community is undergoing a shift towards open-ended generative models and OOD evaluation. In this new paradigm, the existing VQA Accuracy metric is overly stringent and underestimates the performance of VQA systems. Thus, there is a need to develop more robust automatic VQA metrics that serve as a proxy for human judgment. In this work, we propose to leverage the in-context learning capabilities of instruction-tuned large language models (LLMs) to build a better VQA metric. We formulate VQA evaluation as an answer-rating task where the LLM is instructed to score the accuracy of a candidate answer given a set of reference answers. We demonstrate the proposed metric better correlates with human judgment compared to existing metrics across several VQA models and benchmarks. We hope wide adoption of our metric will contribute to better estimating the research progress on the VQA task.
Pragmatic Inference with a CLIP Listener for Contrastive Captioning
Jun 15, 2023
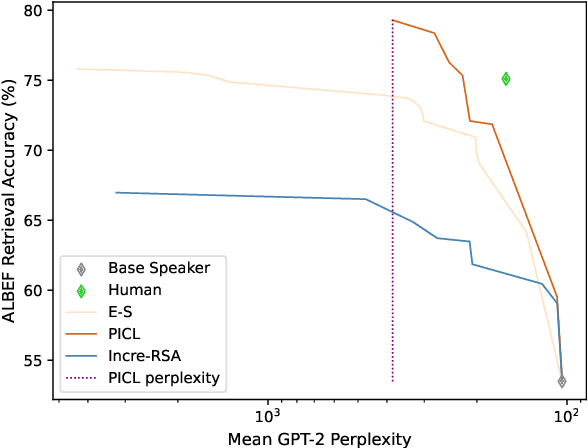
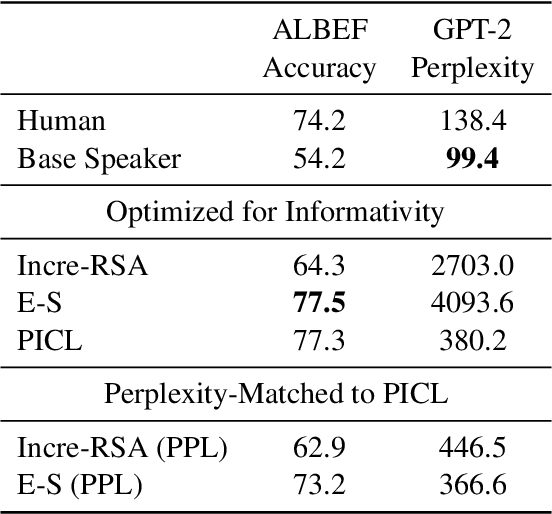
We propose a simple yet effective and robust method for contrastive captioning: generating discriminative captions that distinguish target images from very similar alternative distractor images. Our approach is built on a pragmatic inference procedure that formulates captioning as a reference game between a speaker, which produces possible captions describing the target, and a listener, which selects the target given the caption. Unlike previous methods that derive both speaker and listener distributions from a single captioning model, we leverage an off-the-shelf CLIP model to parameterize the listener. Compared with captioner-only pragmatic models, our method benefits from rich vision language alignment representations from CLIP when reasoning over distractors. Like previous methods for discriminative captioning, our method uses a hyperparameter to control the tradeoff between the informativity (how likely captions are to allow a human listener to discriminate the target image) and the fluency of the captions. However, we find that our method is substantially more robust to the value of this hyperparameter than past methods, which allows us to automatically optimize the captions for informativity - outperforming past methods for discriminative captioning by 11% to 15% accuracy in human evaluations
Are Diffusion Models Vision-And-Language Reasoners?
May 25, 2023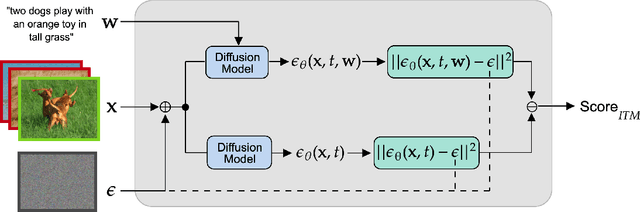
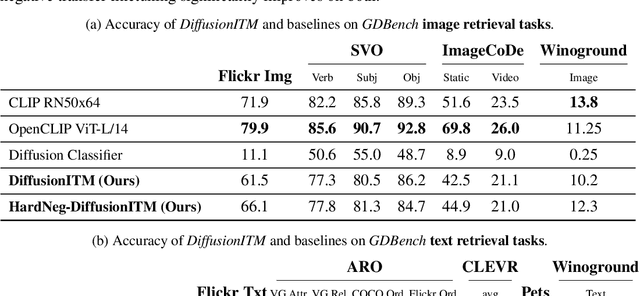
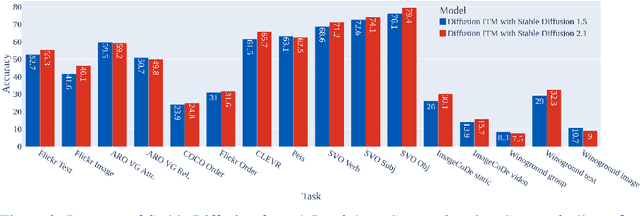
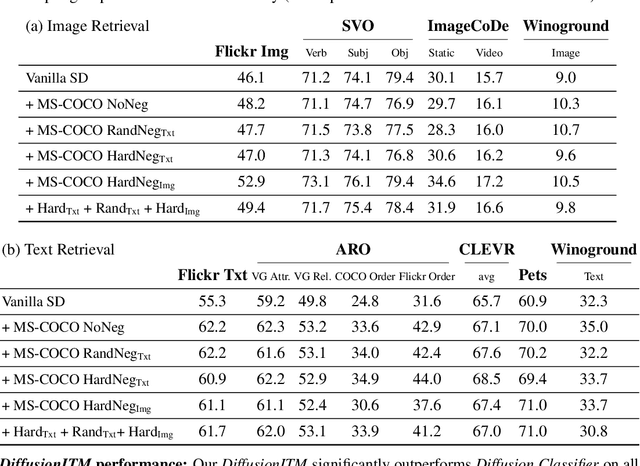
Text-conditioned image generation models have recently shown immense qualitative success using denoising diffusion processes. However, unlike discriminative vision-and-language models, it is a non-trivial task to subject these diffusion-based generative models to automatic fine-grained quantitative evaluation of high-level phenomena such as compositionality. Towards this goal, we perform two innovations. First, we transform diffusion-based models (in our case, Stable Diffusion) for any image-text matching (ITM) task using a novel method called DiffusionITM. Second, we introduce the Generative-Discriminative Evaluation Benchmark (GDBench) benchmark with 7 complex vision-and-language tasks, bias evaluation and detailed analysis. We find that Stable Diffusion + DiffusionITM is competitive on many tasks and outperforms CLIP on compositional tasks like like CLEVR and Winoground. We further boost its compositional performance with a transfer setup by fine-tuning on MS-COCO while retaining generative capabilities. We also measure the stereotypical bias in diffusion models, and find that Stable Diffusion 2.1 is, for the most part, less biased than Stable Diffusion 1.5. Overall, our results point in an exciting direction bringing discriminative and generative model evaluation closer. We will release code and benchmark setup soon.
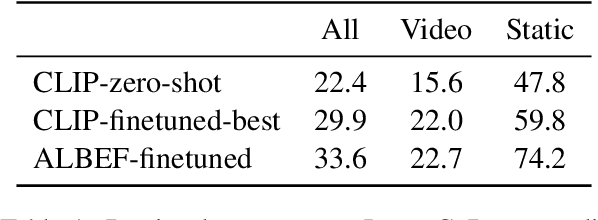
Image Retrieval from Contextual Descriptions
Mar 29, 2022


The ability to integrate context, including perceptual and temporal cues, plays a pivotal role in grounding the meaning of a linguistic utterance. In order to measure to what extent current vision-and-language models master this ability, we devise a new multimodal challenge, Image Retrieval from Contextual Descriptions (ImageCoDe). In particular, models are tasked with retrieving the correct image from a set of 10 minimally contrastive candidates based on a contextual description. As such, each description contains only the details that help distinguish between images. Because of this, descriptions tend to be complex in terms of syntax and discourse and require drawing pragmatic inferences. Images are sourced from both static pictures and video frames. We benchmark several state-of-the-art models, including both cross-encoders such as ViLBERT and bi-encoders such as CLIP, on ImageCoDe. Our results reveal that these models dramatically lag behind human performance: the best variant achieves an accuracy of 20.9 on video frames and 59.4 on static pictures, compared with 90.8 in humans. Furthermore, we experiment with new model variants that are better equipped to incorporate visual and temporal context into their representations, which achieve modest gains. Our hope is that ImageCoDE will foster progress in grounded language understanding by encouraging models to focus on fine-grained visual differences.