 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivileged Information Distillation for Language Models
Feb 04, 2026Training-time privileged information (PI) can enable language models to succeed on tasks they would otherwise fail, making it a powerful tool for reinforcement learning in hard, long-horizon settings. However, transferring capabilities learned with PI to policies that must act without it at inference time remains a fundamental challenge. We study this problem in the context of distilling frontier models for multi-turn agentic environments, where closed-source systems typically hide their internal reasoning and expose only action trajectories. This breaks standard distillation pipelines, since successful behavior is observable but the reasoning process is not. For this, we introduce π-Distill, a joint teacher-student objective that trains a PI-conditioned teacher and an unconditioned student simultaneously using the same model. Additionally, we also introduce On-Policy Self-Distillation (OPSD), an alternative approach that trains using Reinforcement Learning (RL) with a reverse KL-penalty between the student and the PI-conditioned teacher. We show that both of these algorithms effectively distill frontier agents using action-only PI. Specifically we find that π-Distill and in some cases OPSD, outperform industry standard practices (Supervised finetuning followed by RL) that assume access to full Chain-of-Thought supervision across multiple agentic benchmarks, models, and forms of PI. We complement our results with extensive analysis that characterizes the factors enabling effective learning with PI, focusing primarily on π-Distill and characterizing when OPSD is competitive.
SLACK: Attacking LiDAR-based SLAM with Adversarial Point Injections
Apr 03, 2025The widespread adoption of learning-based methods for the LiDAR makes autonomous vehicles vulnerable to adversarial attacks through adversarial \textit{point injections (PiJ)}. It poses serious security challenges for navigation and map generation. Despite its critical nature, no major work exists that studies learning-based attacks on LiDAR-based SLAM. Our work proposes SLACK, an end-to-end deep generative adversarial model to attack LiDAR scans with several point injections without deteriorating LiDAR quality. To facilitate SLACK, we design a novel yet simple autoencoder that augments contrastive learning with segmentation-based attention for precise reconstructions. SLACK demonstrates superior performance on the task of \textit{point injections (PiJ)} compared to the best baselines on KITTI and CARLA-64 dataset while maintaining accurate scan quality. We qualitatively and quantitatively demonstrate PiJ attacks using a fraction of LiDAR points. It severely degrades navigation and map quality without deteriorating the LiDAR scan quality.
Learning Action and Reasoning-Centric Image Editing from Videos and Simulations
Jul 03, 2024
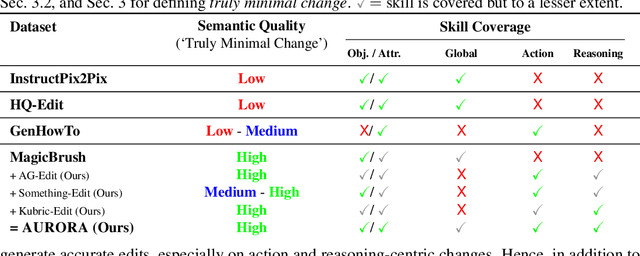
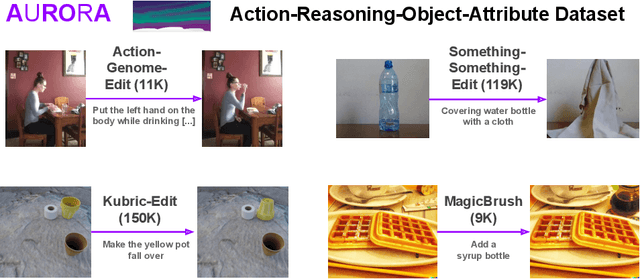

An image editing model should be able to perform diverse edits, ranging from object replacement, changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current general instruction-guided editing models have significant shortcomings with action and reasoning-centric edits. Object, attribute or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality and spatial reasoning. To this end, we meticulously curate the AURORA Dataset (Action-Reasoning-Object-Attribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines. We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., truly minimal changes between source and target images. To demonstrate the value of our dataset, we evaluate an AURORA-finetuned model on a new expert-curated benchmark (AURORA-Bench) covering 8 diverse editing tasks. Our model significantly outperforms previous editing models as judged by human raters. For automatic evaluations, we find important flaws in previous metrics and caution their use for semantically hard editing tasks. Instead, we propose a new automatic metric that focuses on discriminative understanding. We hope that our efforts : (1) curating a quality training dataset and an evaluation benchmark, (2) developing critical evaluations, and (3) releasing a state-of-the-art model, will fuel further progress on general image editing.
Differentiable SLAM Helps Deep Learning-based LiDAR Perception Tasks
Sep 17, 2023



We investigate a new paradigm that uses differentiable SLAM architectures in a self-supervised manner to train end-to-end deep learning models in various LiDAR based applications. To the best of our knowledge there does not exist any work that leverages SLAM as a training signal for deep learning based models. We explore new ways to improve the efficiency, robustness, and adaptability of LiDAR systems with deep learning techniques. We focus on the potential benefits of differentiable SLAM architectures for improving performance of deep learning tasks such as classification, regression as well as SLAM. Our experimental results demonstrate a non-trivial increase in the performance of two deep learning applications - Ground Level Estimation and Dynamic to Static LiDAR Translation, when used with differentiable SLAM architectures. Overall, our findings provide important insights that enhance the performance of LiDAR based navigation systems. We demonstrate that this new paradigm of using SLAM Loss signal while training LiDAR based models can be easily adopted by the community.