 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM2Vec-Gen: Generative Embeddings from Large Language Models
Mar 11, 2026LLM-based text embedders typically encode the semantic content of their input. However, embedding tasks require mapping diverse inputs to similar outputs. Typically, this input-output is addressed by training embedding models with paired data using contrastive learning. In this work, we propose a novel self-supervised approach, LLM2Vec-Gen, which adopts a different paradigm: rather than encoding the input, we learn to represent the model's potential response. Specifically, we add trainable special tokens to the LLM's vocabulary, append them to input, and optimize them to represent the LLM's response in a fixed-length sequence. Training is guided by the LLM's own completion for the query, along with an unsupervised embedding teacher that provides distillation targets. This formulation helps to bridge the input-output gap and transfers LLM capabilities such as safety alignment and reasoning to embedding tasks. Crucially, the LLM backbone remains frozen and training requires only unlabeled queries. LLM2Vec-Gen achieves state-of-the-art self-supervised performance on the Massive Text Embedding Benchmark (MTEB), improving by 9.3% over the best unsupervised embedding teacher. We also observe up to 43.2% reduction in harmful content retrieval and 29.3% improvement in reasoning capabilities for embedding tasks. Finally, the learned embeddings are interpretable and can be decoded into text to reveal their semantic content.
LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs
Jan 31, 2026Transforming a large language model (LLM) into a Vision-Language Model (VLM) can be achieved by mapping the visual tokens from a vision encoder into the embedding space of an LLM. Intriguingly, this mapping can be as simple as a shallow MLP transformation. To understand why LLMs can so readily process visual tokens, we need interpretability methods that reveal what is encoded in the visual token representations at every layer of LLM processing. In this work, we introduce LatentLens, a novel approach for mapping latent representations to descriptions in natural language. LatentLens works by encoding a large text corpus and storing contextualized token representations for each token in that corpus. Visual token representations are then compared to their contextualized textual representations, with the top-k nearest neighbor representations providing descriptions of the visual token. We evaluate this method on 10 different VLMs, showing that commonly used methods, such as LogitLens, substantially underestimate the interpretability of visual tokens. With LatentLens instead, the majority of visual tokens are interpretable across all studied models and all layers. Qualitatively, we show that the descriptions produced by LatentLens are semantically meaningful and provide more fine-grained interpretations for humans compared to individual tokens. More broadly, our findings contribute new evidence on the alignment between vision and language representations, opening up new directions for analyzing latent representations.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Apr 09, 2024



Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data. Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
Evaluating Correctness and Faithfulness of Instruction-Following Models for Question Answering
Jul 31, 2023Retriever-augmented instruction-following models are attractive alternatives to fine-tuned approaches for information-seeking tasks such as question answering (QA). By simply prepending retrieved documents in its input along with an instruction, these models can be adapted to various information domains and tasks without additional fine-tuning. While the model responses tend to be natural and fluent, the additional verbosity makes traditional QA evaluation metrics such as exact match (EM) and F1 unreliable for accurately quantifying model performance. In this work, we investigate the performance of instruction-following models across three information-seeking QA tasks. We use both automatic and human evaluation to evaluate these models along two dimensions: 1) how well they satisfy the user's information need (correctness), and 2) whether they produce a response based on the provided knowledge (faithfulness). Guided by human evaluation and analysis, we highlight the shortcomings of traditional metrics for both correctness and faithfulness. We then propose simple token-overlap based and model-based metrics that reflect the true performance of these models. Our analysis reveals that instruction-following models are competitive, and sometimes even outperform fine-tuned models for correctness. However, these models struggle to stick to the provided knowledge and often hallucinate in their responses. We hope our work encourages a more holistic evaluation of instruction-following models for QA. Our code and data is available at https://github.com/McGill-NLP/instruct-qa
Image Retrieval from Contextual Descriptions
Mar 29, 2022


The ability to integrate context, including perceptual and temporal cues, plays a pivotal role in grounding the meaning of a linguistic utterance. In order to measure to what extent current vision-and-language models master this ability, we devise a new multimodal challenge, Image Retrieval from Contextual Descriptions (ImageCoDe). In particular, models are tasked with retrieving the correct image from a set of 10 minimally contrastive candidates based on a contextual description. As such, each description contains only the details that help distinguish between images. Because of this, descriptions tend to be complex in terms of syntax and discourse and require drawing pragmatic inferences. Images are sourced from both static pictures and video frames. We benchmark several state-of-the-art models, including both cross-encoders such as ViLBERT and bi-encoders such as CLIP, on ImageCoDe. Our results reveal that these models dramatically lag behind human performance: the best variant achieves an accuracy of 20.9 on video frames and 59.4 on static pictures, compared with 90.8 in humans. Furthermore, we experiment with new model variants that are better equipped to incorporate visual and temporal context into their representations, which achieve modest gains. Our hope is that ImageCoDE will foster progress in grounded language understanding by encouraging models to focus on fine-grained visual differences.
Evaluating the Faithfulness of Importance Measures in NLP by Recursively Masking Allegedly Important Tokens and Retraining
Oct 15, 2021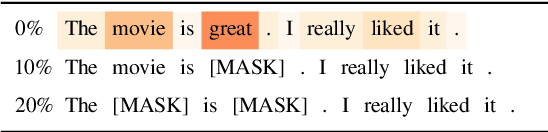
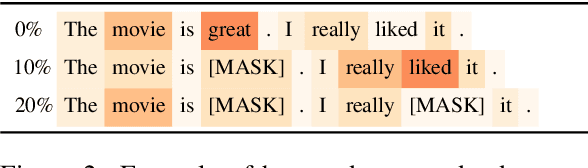
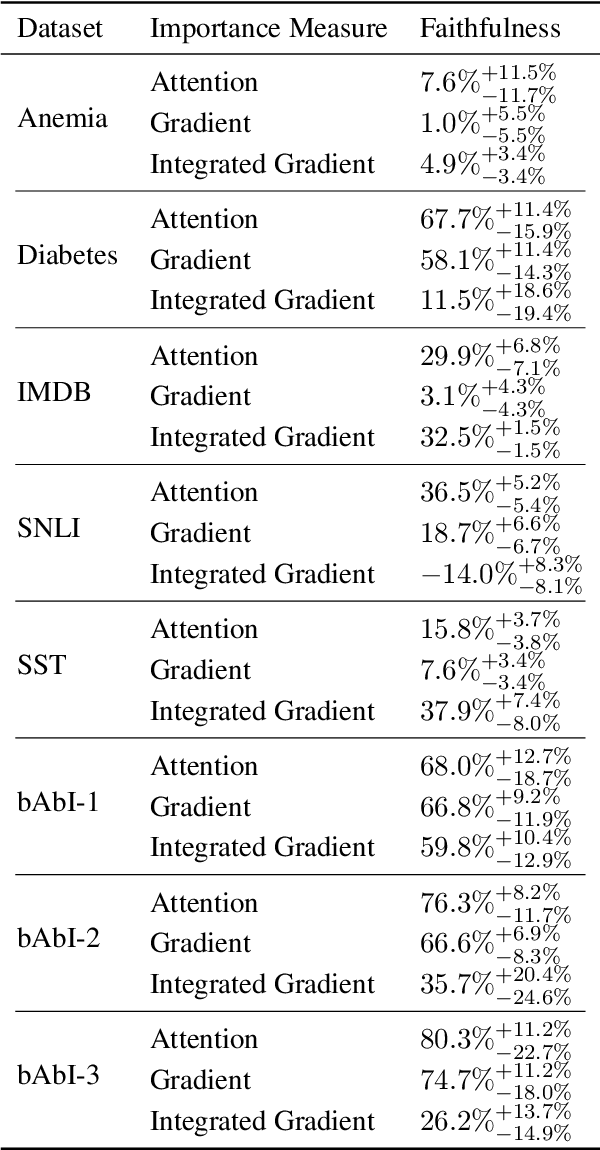
To explain NLP models, many methods inform which inputs tokens are important for a prediction. However, an open question is if these methods accurately reflect the model's logic, a property often called faithfulness. In this work, we adapt and improve a recently proposed faithfulness benchmark from computer vision called ROAR (RemOve And Retrain), by Hooker et al. (2019). We improve ROAR by recursively removing dataset redundancies, which otherwise interfere with ROAR. We adapt and apply ROAR, to popular NLP importance measures, namely attention, gradient, and integrated gradients. Additionally, we use mutual information as an additional baseline. Evaluation is done on a suite of classification tasks often used in the faithfulness of attention literature. Finally, we propose a scalar faithfulness metric, which makes it easy to compare results across papers. We find that, importance measures considered to be unfaithful for computer vision tasks perform favorably for NLP tasks, the faithfulness of an importance measure is task-dependent, and the computational overhead of integrated gradient is rarely justified.
TopiOCQA: Open-domain Conversational Question Answeringwith Topic Switching
Oct 02, 2021

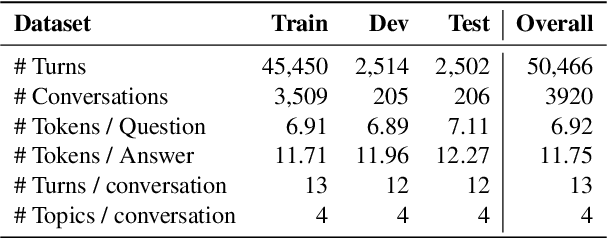
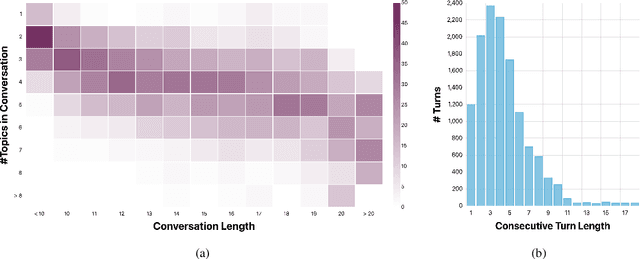
In a conversational question answering scenario, a questioner seeks to extract information about a topic through a series of interdependent questions and answers. As the conversation progresses, they may switch to related topics, a phenomenon commonly observed in information-seeking search sessions. However, current datasets for conversational question answering are limiting in two ways: 1) they do not contain topic switches; and 2) they assume the reference text for the conversation is given, i.e., the setting is not open-domain. We introduce TopiOCQA (pronounced Tapioca), an open-domain conversational dataset with topic switches on Wikipedia. TopiOCQA contains 3,920 conversations with information-seeking questions and free-form answers. TopiOCQA poses a challenging test-bed for models, where efficient retrieval is required on multiple turns of the same conversation, in conjunction with constructing valid responses using conversational history. We evaluate several baselines, by combining state-of-the-art document retrieval methods with neural reader models. Our best models achieves F1 of 51.9, and BLEU score of 42.1 which falls short of human performance by 18.3 points and 17.6 points respectively, indicating the difficulty of our dataset. Our dataset and code will be available at https://mcgill-nlp.github.io/topiocqa
OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction
Oct 07, 2020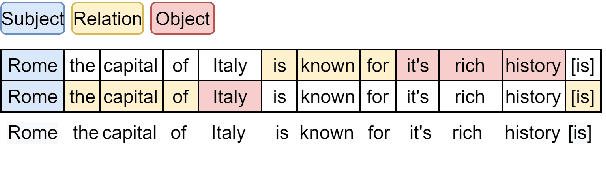

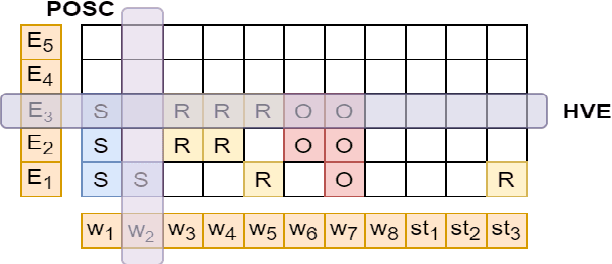
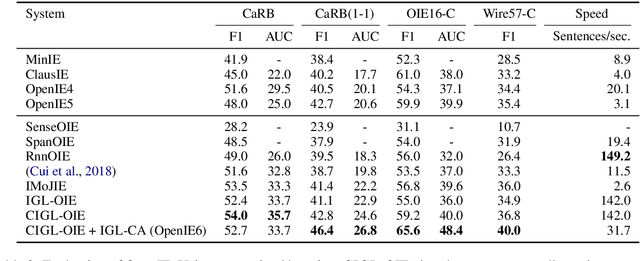
A recent state-of-the-art neural open information extraction (OpenIE) system generates extractions iteratively, requiring repeated encoding of partial outputs. This comes at a significant computational cost. On the other hand, sequence labeling approaches for OpenIE are much faster, but worse in extraction quality. In this paper, we bridge this trade-off by presenting an iterative labeling-based system that establishes a new state of the art for OpenIE, while extracting 10x faster. This is achieved through a novel Iterative Grid Labeling (IGL) architecture, which treats OpenIE as a 2-D grid labeling task. We improve its performance further by applying coverage (soft) constraints on the grid at training time. Moreover, on observing that the best OpenIE systems falter at handling coordination structures, our OpenIE system also incorporates a new coordination analyzer built with the same IGL architecture. This IGL based coordination analyzer helps our OpenIE system handle complicated coordination structures, while also establishing a new state of the art on the task of coordination analysis, with a 12.3 pts improvement in F1 over previous analyzers. Our OpenIE system, OpenIE6, beats the previous systems by as much as 4 pts in F1, while being much faster.
Knowledge Base Inference for Regular Expression Queries
May 01, 2020

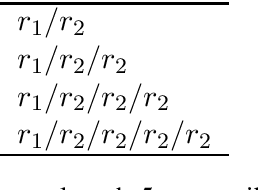

Two common types of tasks on Knowledge Bases have been studied -- single link prediction (Knowledge Base Completion) and path query answering. However, our analysis of user queries on a real-world knowledge base reveals that a significant fraction of queries specify paths using regular expressions(regex). Such regex queries cannot be handled by any of the existing link prediction or path query answering models. In response, we present Regex Query Answering, the novel task of answering regex queries on incomplete KBs. We contribute two datasets for the task, including one where test queries are harvested from actual user querylogs. We train baseline neural models for our new task and propose novel ways to handle disjunction and Kleene plus regex operators.