 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Faithfulness of Importance Measures in NLP by Recursively Masking Allegedly Important Tokens and Retraining
Paper and Code
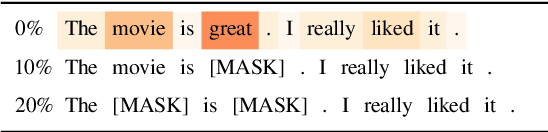
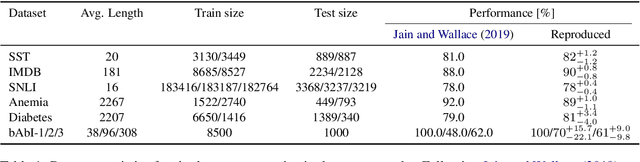
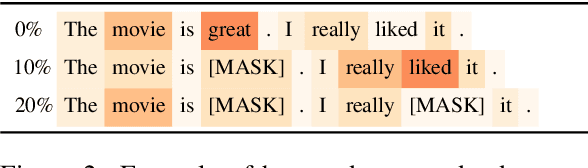
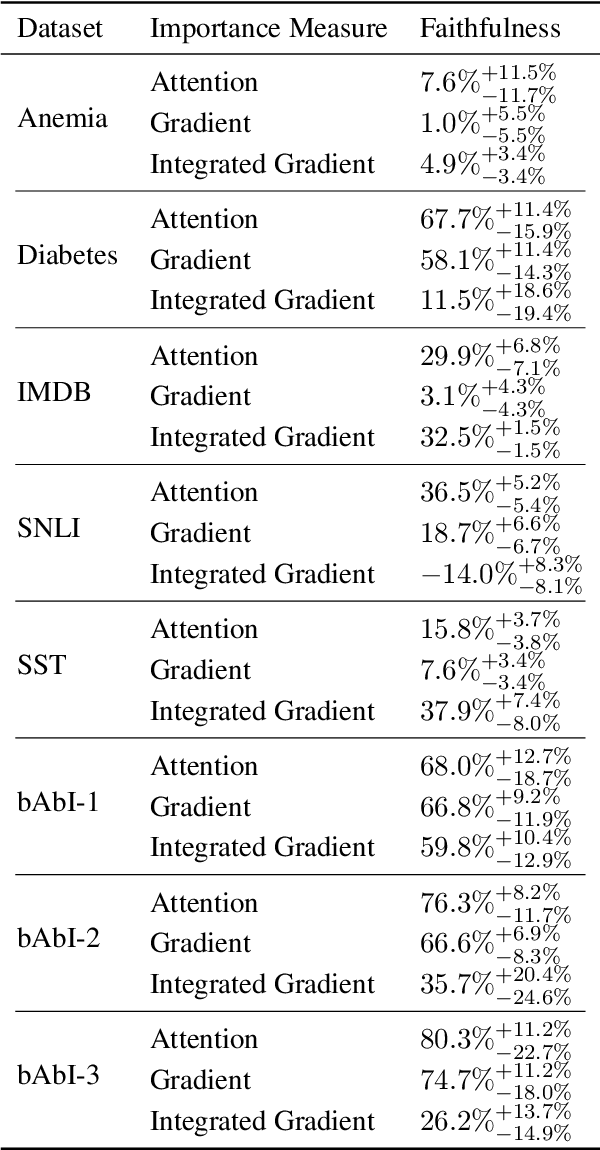
To explain NLP models, many methods inform which inputs tokens are important for a prediction. However, an open question is if these methods accurately reflect the model's logic, a property often called faithfulness. In this work, we adapt and improve a recently proposed faithfulness benchmark from computer vision called ROAR (RemOve And Retrain), by Hooker et al. (2019). We improve ROAR by recursively removing dataset redundancies, which otherwise interfere with ROAR. We adapt and apply ROAR, to popular NLP importance measures, namely attention, gradient, and integrated gradients. Additionally, we use mutual information as an additional baseline. Evaluation is done on a suite of classification tasks often used in the faithfulness of attention literature. Finally, we propose a scalar faithfulness metric, which makes it easy to compare results across papers. We find that, importance measures considered to be unfaithful for computer vision tasks perform favorably for NLP tasks, the faithfulness of an importance measure is task-dependent, and the computational overhead of integrated gradient is rarely justified.