 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopiOCQA: Open-domain Conversational Question Answeringwith Topic Switching
Paper and Code


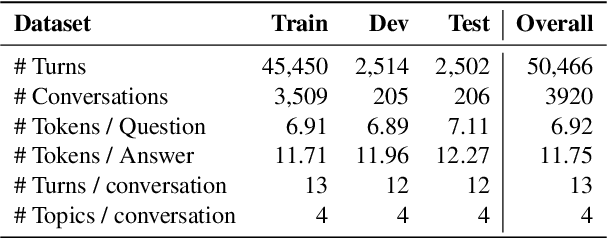
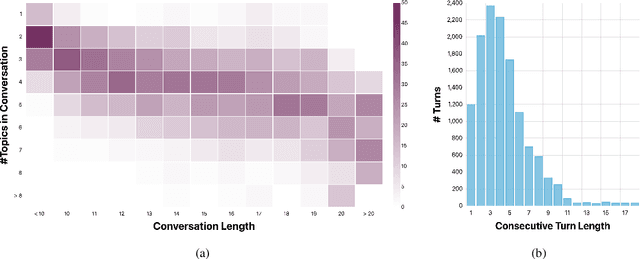
In a conversational question answering scenario, a questioner seeks to extract information about a topic through a series of interdependent questions and answers. As the conversation progresses, they may switch to related topics, a phenomenon commonly observed in information-seeking search sessions. However, current datasets for conversational question answering are limiting in two ways: 1) they do not contain topic switches; and 2) they assume the reference text for the conversation is given, i.e., the setting is not open-domain. We introduce TopiOCQA (pronounced Tapioca), an open-domain conversational dataset with topic switches on Wikipedia. TopiOCQA contains 3,920 conversations with information-seeking questions and free-form answers. TopiOCQA poses a challenging test-bed for models, where efficient retrieval is required on multiple turns of the same conversation, in conjunction with constructing valid responses using conversational history. We evaluate several baselines, by combining state-of-the-art document retrieval methods with neural reader models. Our best models achieves F1 of 51.9, and BLEU score of 42.1 which falls short of human performance by 18.3 points and 17.6 points respectively, indicating the difficulty of our dataset. Our dataset and code will be available at https://mcgill-nlp.github.io/topiocqa