 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Correctness and Faithfulness of Instruction-Following Models for Question Answering
Jul 31, 2023Retriever-augmented instruction-following models are attractive alternatives to fine-tuned approaches for information-seeking tasks such as question answering (QA). By simply prepending retrieved documents in its input along with an instruction, these models can be adapted to various information domains and tasks without additional fine-tuning. While the model responses tend to be natural and fluent, the additional verbosity makes traditional QA evaluation metrics such as exact match (EM) and F1 unreliable for accurately quantifying model performance. In this work, we investigate the performance of instruction-following models across three information-seeking QA tasks. We use both automatic and human evaluation to evaluate these models along two dimensions: 1) how well they satisfy the user's information need (correctness), and 2) whether they produce a response based on the provided knowledge (faithfulness). Guided by human evaluation and analysis, we highlight the shortcomings of traditional metrics for both correctness and faithfulness. We then propose simple token-overlap based and model-based metrics that reflect the true performance of these models. Our analysis reveals that instruction-following models are competitive, and sometimes even outperform fine-tuned models for correctness. However, these models struggle to stick to the provided knowledge and often hallucinate in their responses. We hope our work encourages a more holistic evaluation of instruction-following models for QA. Our code and data is available at https://github.com/McGill-NLP/instruct-qa
TASTY: A Transformer based Approach to Space and Time complexity
May 10, 2023Code based Language Models (LMs) have shown very promising results in the field of software engineering with applications such as code refinement, code completion and generation. However, the task of time and space complexity classification from code has not been extensively explored due to a lack of datasets, with prior endeavors being limited to Java. In this project, we aim to address these gaps by creating a labelled dataset of code snippets spanning multiple languages (Python and C++ datasets currently, with C, C#, and JavaScript datasets being released shortly). We find that existing time complexity calculation libraries and tools only apply to a limited number of use-cases. The lack of a well-defined rule based system motivates the application of several recently proposed code-based LMs. We demonstrate the effectiveness of dead code elimination and increasing the maximum sequence length of LMs. In addition to time complexity, we propose to use LMs to find space complexities from code, and to the best of our knowledge, this is the first attempt to do so. Furthermore, we introduce a novel code comprehension task, called cross-language transfer, where we fine-tune the LM on one language and run inference on another. Finally, we visualize the activation of the attention fed classification head of our LMs using Non-negative Matrix Factorization (NMF) to interpret our results.
The StatCan Dialogue Dataset: Retrieving Data Tables through Conversations with Genuine Intents
Apr 05, 2023We introduce the StatCan Dialogue Dataset consisting of 19,379 conversation turns between agents working at Statistics Canada and online users looking for published data tables. The conversations stem from genuine intents, are held in English or French, and lead to agents retrieving one of over 5000 complex data tables. Based on this dataset, we propose two tasks: (1) automatic retrieval of relevant tables based on a on-going conversation, and (2) automatic generation of appropriate agent responses at each turn. We investigate the difficulty of each task by establishing strong baselines. Our experiments on a temporal data split reveal that all models struggle to generalize to future conversations, as we observe a significant drop in performance across both tasks when we move from the validation to the test set. In addition, we find that response generation models struggle to decide when to return a table. Considering that the tasks pose significant challenges to existing models, we encourage the community to develop models for our task, which can be directly used to help knowledge workers find relevant tables for live chat users.
Using Interactive Feedback to Improve the Accuracy and Explainability of Question Answering Systems Post-Deployment
Apr 06, 2022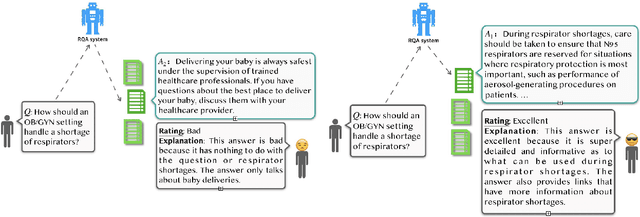
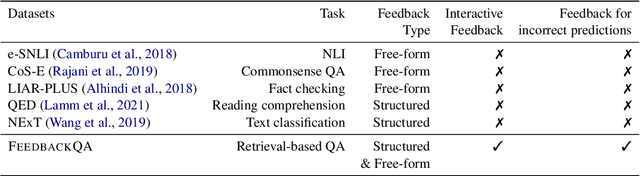
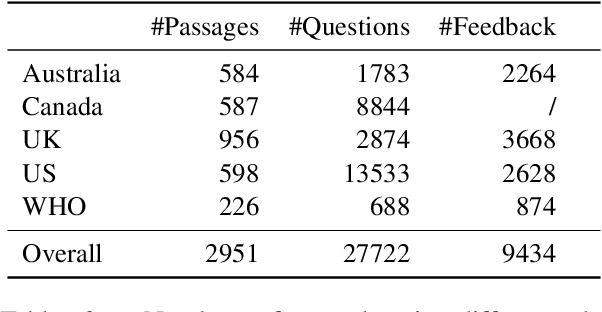
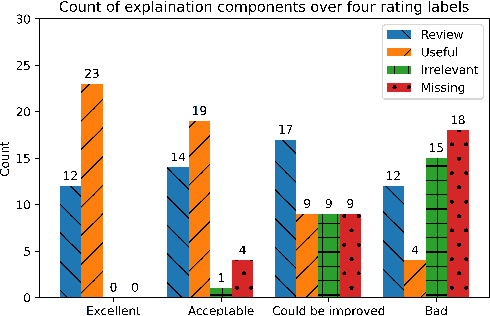
Most research on question answering focuses on the pre-deployment stage; i.e., building an accurate model for deployment. In this paper, we ask the question: Can we improve QA systems further \emph{post-}deployment based on user interactions? We focus on two kinds of improvements: 1) improving the QA system's performance itself, and 2) providing the model with the ability to explain the correctness or incorrectness of an answer. We collect a retrieval-based QA dataset, FeedbackQA, which contains interactive feedback from users. We collect this dataset by deploying a base QA system to crowdworkers who then engage with the system and provide feedback on the quality of its answers. The feedback contains both structured ratings and unstructured natural language explanations. We train a neural model with this feedback data that can generate explanations and re-score answer candidates. We show that feedback data not only improves the accuracy of the deployed QA system but also other stronger non-deployed systems. The generated explanations also help users make informed decisions about the correctness of answers. Project page: https://mcgill-nlp.github.io/feedbackqa/
MeDAL: Medical Abbreviation Disambiguation Dataset for Natural Language Understanding Pretraining
Dec 27, 2020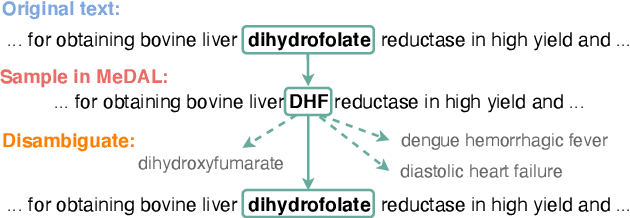

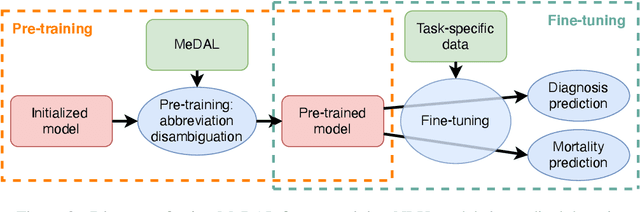

One of the biggest challenges that prohibit the use of many current NLP methods in clinical settings is the availability of public datasets. In this work, we present MeDAL, a large medical text dataset curated for abbreviation disambiguation, designed for natural language understanding pre-training in the medical domain. We pre-trained several models of common architectures on this dataset and empirically showed that such pre-training leads to improved performance and convergence speed when fine-tuning on downstream medical tasks.
* EMNLP 2020 Clinical NLP