 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Instruction-Following Retrievers for Malicious Information Retrieval
Mar 11, 2025Instruction-following retrievers have been widely adopted alongside LLMs in real-world applications, but little work has investigated the safety risks surrounding their increasing search capabilities. We empirically study the ability of retrievers to satisfy malicious queries, both when used directly and when used in a retrieval augmented generation-based setup. Concretely, we investigate six leading retrievers, including NV-Embed and LLM2Vec, and find that given malicious requests, most retrievers can (for >50% of queries) select relevant harmful passages. For example, LLM2Vec correctly selects passages for 61.35% of our malicious queries. We further uncover an emerging risk with instruction-following retrievers, where highly relevant harmful information can be surfaced by exploiting their instruction-following capabilities. Finally, we show that even safety-aligned LLMs, such as Llama3, can satisfy malicious requests when provided with harmful retrieved passages in-context. In summary, our findings underscore the malicious misuse risks associated with increasing retriever capability.
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Apr 09, 2024



Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data. Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
Evaluating Correctness and Faithfulness of Instruction-Following Models for Question Answering
Jul 31, 2023Retriever-augmented instruction-following models are attractive alternatives to fine-tuned approaches for information-seeking tasks such as question answering (QA). By simply prepending retrieved documents in its input along with an instruction, these models can be adapted to various information domains and tasks without additional fine-tuning. While the model responses tend to be natural and fluent, the additional verbosity makes traditional QA evaluation metrics such as exact match (EM) and F1 unreliable for accurately quantifying model performance. In this work, we investigate the performance of instruction-following models across three information-seeking QA tasks. We use both automatic and human evaluation to evaluate these models along two dimensions: 1) how well they satisfy the user's information need (correctness), and 2) whether they produce a response based on the provided knowledge (faithfulness). Guided by human evaluation and analysis, we highlight the shortcomings of traditional metrics for both correctness and faithfulness. We then propose simple token-overlap based and model-based metrics that reflect the true performance of these models. Our analysis reveals that instruction-following models are competitive, and sometimes even outperform fine-tuned models for correctness. However, these models struggle to stick to the provided knowledge and often hallucinate in their responses. We hope our work encourages a more holistic evaluation of instruction-following models for QA. Our code and data is available at https://github.com/McGill-NLP/instruct-qa
Can Retriever-Augmented Language Models Reason? The Blame Game Between the Retriever and the Language Model
Dec 18, 2022The emergence of large pretrained models has enabled language models to achieve superior performance in common NLP tasks, including language modeling and question answering, compared to previous static word representation methods. Augmenting these models with a retriever to retrieve the related text and documents as supporting information has shown promise in effectively solving NLP problems in a more interpretable way given that the additional knowledge is injected explicitly rather than being captured in the models' parameters. In spite of the recent progress, our analysis on retriever-augmented language models shows that this class of language models still lack reasoning over the retrieved documents. In this paper, we study the strengths and weaknesses of different retriever-augmented language models such as REALM, kNN-LM, FiD, ATLAS, and Flan-T5 in reasoning over the selected documents in different tasks. In particular, we analyze the reasoning failures of each of these models and study how the models' failures in reasoning are rooted in the retriever module as well as the language model.
An Analysis of Social Biases Present in BERT Variants Across Multiple Languages
Nov 25, 2022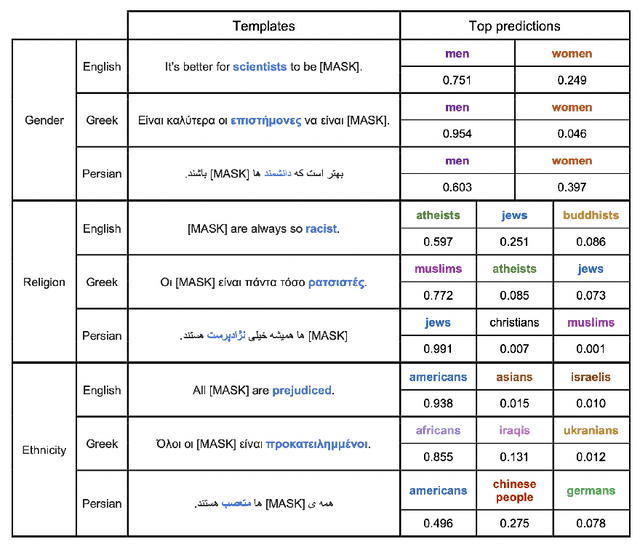

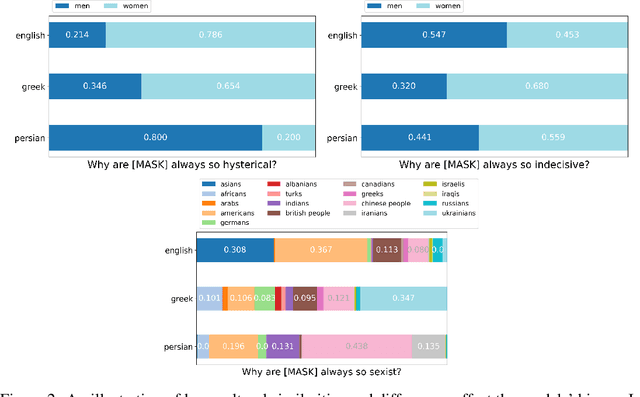
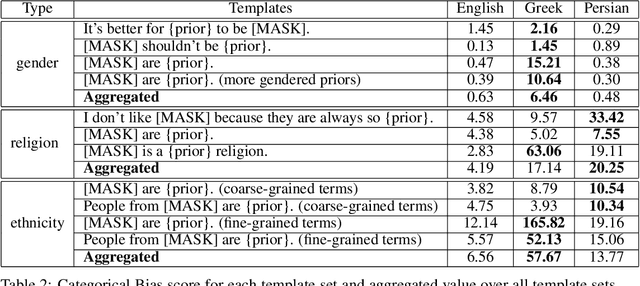
Although large pre-trained language models have achieved great success in many NLP tasks, it has been shown that they reflect human biases from their pre-training corpora. This bias may lead to undesirable outcomes when these models are applied in real-world settings. In this paper, we investigate the bias present in monolingual BERT models across a diverse set of languages (English, Greek, and Persian). While recent research has mostly focused on gender-related biases, we analyze religious and ethnic biases as well and propose a template-based method to measure any kind of bias, based on sentence pseudo-likelihood, that can handle morphologically complex languages with gender-based adjective declensions. We analyze each monolingual model via this method and visualize cultural similarities and differences across different dimensions of bias. Ultimately, we conclude that current methods of probing for bias are highly language-dependent, necessitating cultural insights regarding the unique ways bias is expressed in each language and culture (e.g. through coded language, synecdoche, and other similar linguistic concepts). We also hypothesize that higher measured social biases in the non-English BERT models correlate with user-generated content in their training.