 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Routing Dynamics in Mixture-of-Experts Models for Efficient Language Adaptation
May 28, 2026Mixture-of-Experts (MoE) models are widely used to scale language models, yet their expert routing behavior and adaptation in a multilingual setting remain underexplored. In this work, we study multilingual routing dynamics during continual pre-training of an English-centric MoE model on a multilingual corpus, analyzing how expert usage varies across languages. We find that continual multilingual pre-training leads to diffused, language-agnostic routing in early and middle layers, with language specialization primarily emerging in the final layers. We also show that token-level vocabulary overlap between languages plays an important role in how languages are routed. Motivated by these findings, we propose a parameter-efficient adaptation strategy that updates language-specific and shared experts in the final MoE layers. Experiments on MultiBLiMP and Belebele show that our method achieves a strong performance-efficiency trade-off, attaining competitive performance relative to fine-tuning complete final layers, while updating less than 2% of the parameters. Overall, our findings provide insights into where and how language specialization emerges in MoEs during continual pre-training and provide practical insights for low-resource multilingual adaptation. Our code is available at https://github.com/aditi184/moe-routing-adaptation.
Forecasting Downstream Performance of LLMs With Proxy Metrics
May 18, 2026Progress in language model development is often driven by comparative decisions: which architecture to adopt, which pretraining corpus to use, or which training recipe to apply. Making these decisions well requires reliable performance forecasts, yet the two commonly used signals are fundamentally limited. Cross-entropy loss is poorly aligned with downstream capabilities, and direct downstream evaluation is expensive, sparse, and often uninformative at early training stages. Instead, we propose to construct proxy metrics by aggregating token-level statistics, such as entropy, top-k accuracy, and expert token rank, from a candidate model's next token distribution over expert-written solutions. Across three settings, our proxies consistently outperform loss- and compute-based baselines: 1) For cross-family model selection, they rank a heterogeneous population of reasoning models with mean Spearman Rho = 0.81 (vs. Rho = 0.36 for cross-entropy loss); 2) For pretraining data selection, they reliably rank 25 candidate corpora for a target model at roughly $10{,}000\times$ less compute than direct evaluation, pushing the Pareto frontier beyond existing methods; and 3) for training-time forecasting, they extrapolate downstream accuracy across an $18\times$ compute horizon with roughly half the error of existing alternatives. Together, these results suggest that expert trajectories are a broadly useful source of signal for assessing model capabilities, enabling reliable performance forecasting throughout the model development life cycle.
The Illusion of Superposition? A Principled Analysis of Latent Thinking in Language Models
Apr 07, 2026Latent reasoning via continuous chain-of-thoughts (Latent CoT) has emerged as a promising alternative to discrete CoT reasoning. Operating in continuous space increases expressivity and has been hypothesized to enable superposition: the ability to maintain multiple candidate solutions simultaneously within a single representation. Despite theoretical arguments, it remains unclear whether language models actually leverage superposition when reasoning using latent CoTs. We investigate this question across three regimes: a training-free regime that constructs latent thoughts as convex combinations of token embeddings, a fine-tuned regime where a base model is adapted to produce latent thoughts, and a from-scratch regime where a model is trained entirely with latent thoughts to solve a given task. Using Logit Lens and entity-level probing to analyze internal representations, we find that only models trained from scratch exhibit signs of using superposition. In the training-free and fine-tuned regimes, we find that the superposition either collapses or is not used at all, with models discovering shortcut solutions instead. We argue that this is due to two complementary phenomena: i) pretraining on natural language data biases models to commit to a token in the last layers ii) capacity has a huge effect on which solutions a model favors. Together, our results offer a unified explanation for when and why superposition arises in continuous chain-of-thought reasoning, and identify the conditions under which it collapses.
LLM2Vec-Gen: Generative Embeddings from Large Language Models
Mar 11, 2026LLM-based text embedders typically encode the semantic content of their input. However, embedding tasks require mapping diverse inputs to similar outputs. Typically, this input-output is addressed by training embedding models with paired data using contrastive learning. In this work, we propose a novel self-supervised approach, LLM2Vec-Gen, which adopts a different paradigm: rather than encoding the input, we learn to represent the model's potential response. Specifically, we add trainable special tokens to the LLM's vocabulary, append them to input, and optimize them to represent the LLM's response in a fixed-length sequence. Training is guided by the LLM's own completion for the query, along with an unsupervised embedding teacher that provides distillation targets. This formulation helps to bridge the input-output gap and transfers LLM capabilities such as safety alignment and reasoning to embedding tasks. Crucially, the LLM backbone remains frozen and training requires only unlabeled queries. LLM2Vec-Gen achieves state-of-the-art self-supervised performance on the Massive Text Embedding Benchmark (MTEB), improving by 9.3% over the best unsupervised embedding teacher. We also observe up to 43.2% reduction in harmful content retrieval and 29.3% improvement in reasoning capabilities for embedding tasks. Finally, the learned embeddings are interpretable and can be decoded into text to reveal their semantic content.
Operationalising the Superficial Alignment Hypothesis via Task Complexity
Feb 17, 2026The superficial alignment hypothesis (SAH) posits that large language models learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge. The SAH, however, lacks a precise definition, which has led to (i) different and seemingly orthogonal arguments supporting it, and (ii) important critiques to it. We propose a new metric called task complexity: the length of the shortest program that achieves a target performance on a task. In this framework, the SAH simply claims that pre-trained models drastically reduce the complexity of achieving high performance on many tasks. Our definition unifies prior arguments supporting the SAH, interpreting them as different strategies to find such short programs. Experimentally, we estimate the task complexity of mathematical reasoning, machine translation, and instruction following; we then show that these complexities can be remarkably low when conditioned on a pre-trained model. Further, we find that pre-training enables access to strong performances on our tasks, but it can require programs of gigabytes of length to access them. Post-training, on the other hand, collapses the complexity of reaching this same performance by several orders of magnitude. Overall, our results highlight that task adaptation often requires surprisingly little information -- often just a few kilobytes.
LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs
Jan 31, 2026Transforming a large language model (LLM) into a Vision-Language Model (VLM) can be achieved by mapping the visual tokens from a vision encoder into the embedding space of an LLM. Intriguingly, this mapping can be as simple as a shallow MLP transformation. To understand why LLMs can so readily process visual tokens, we need interpretability methods that reveal what is encoded in the visual token representations at every layer of LLM processing. In this work, we introduce LatentLens, a novel approach for mapping latent representations to descriptions in natural language. LatentLens works by encoding a large text corpus and storing contextualized token representations for each token in that corpus. Visual token representations are then compared to their contextualized textual representations, with the top-k nearest neighbor representations providing descriptions of the visual token. We evaluate this method on 10 different VLMs, showing that commonly used methods, such as LogitLens, substantially underestimate the interpretability of visual tokens. With LatentLens instead, the majority of visual tokens are interpretable across all studied models and all layers. Qualitatively, we show that the descriptions produced by LatentLens are semantically meaningful and provide more fine-grained interpretations for humans compared to individual tokens. More broadly, our findings contribute new evidence on the alignment between vision and language representations, opening up new directions for analyzing latent representations.
CLaS-Bench: A Cross-Lingual Alignment and Steering Benchmark
Jan 13, 2026Understanding and controlling the behavior of large language models (LLMs) is an increasingly important topic in multilingual NLP. Beyond prompting or fine-tuning, , i.e.,~manipulating internal representations during inference, has emerged as a more efficient and interpretable technique for adapting models to a target language. Yet, no dedicated benchmarks or evaluation protocols exist to quantify the effectiveness of steering techniques. We introduce CLaS-Bench, a lightweight parallel-question benchmark for evaluating language-forcing behavior in LLMs across 32 languages, enabling systematic evaluation of multilingual steering methods. We evaluate a broad array of steering techniques, including residual-stream DiffMean interventions, probe-derived directions, language-specific neurons, PCA/LDA vectors, Sparse Autoencoders, and prompting baselines. Steering performance is measured along two axes: language control and semantic relevance, combined into a single harmonic-mean steering score. We find that across languages simple residual-based DiffMean method consistently outperforms all other methods. Moreover, a layer-wise analysis reveals that language-specific structure emerges predominantly in later layers and steering directions cluster based on language family. CLaS-Bench is the first standardized benchmark for multilingual steering, enabling both rigorous scientific analysis of language representations and practical evaluation of steering as a low-cost adaptation alternative.
Do Generalisation Results Generalise?
Dec 08, 2025



A large language model's (LLM's) out-of-distribution (OOD) generalisation ability is crucial to its deployment. Previous work assessing LLMs' generalisation performance, however, typically focuses on a single out-of-distribution dataset. This approach may fail to precisely evaluate the capabilities of the model, as the data shifts encountered once a model is deployed are much more diverse. In this work, we investigate whether OOD generalisation results generalise. More specifically, we evaluate a model's performance across multiple OOD testsets throughout a finetuning run; we then evaluate the partial correlation of performances across these testsets, regressing out in-domain performance. This allows us to assess how correlated are generalisation performances once in-domain performance is controlled for. Analysing OLMo2 and OPT, we observe no overarching trend in generalisation results: the existence of a positive or negative correlation between any two OOD testsets depends strongly on the specific choice of model analysed.
Value Drifts: Tracing Value Alignment During LLM Post-Training
Oct 30, 2025As LLMs occupy an increasingly important role in society, they are more and more confronted with questions that require them not only to draw on their general knowledge but also to align with certain human value systems. Therefore, studying the alignment of LLMs with human values has become a crucial field of inquiry. Prior work, however, mostly focuses on evaluating the alignment of fully trained models, overlooking the training dynamics by which models learn to express human values. In this work, we investigate how and at which stage value alignment arises during the course of a model's post-training. Our analysis disentangles the effects of post-training algorithms and datasets, measuring both the magnitude and time of value drifts during training. Experimenting with Llama-3 and Qwen-3 models of different sizes and popular supervised fine-tuning (SFT) and preference optimization datasets and algorithms, we find that the SFT phase generally establishes a model's values, and subsequent preference optimization rarely re-aligns these values. Furthermore, using a synthetic preference dataset that enables controlled manipulation of values, we find that different preference optimization algorithms lead to different value alignment outcomes, even when preference data is held constant. Our findings provide actionable insights into how values are learned during post-training and help to inform data curation, as well as the selection of models and algorithms for preference optimization to improve model alignment to human values.
LMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to Representations
Sep 03, 2025

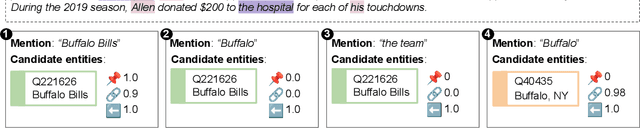
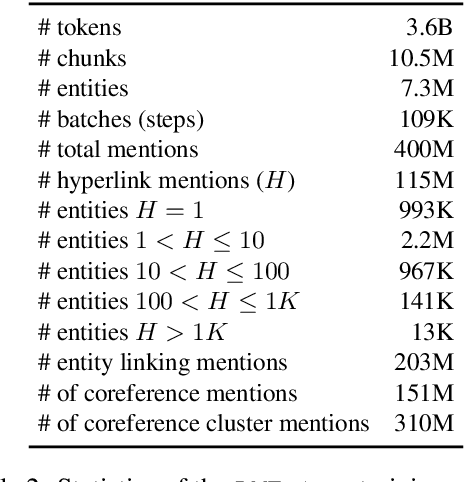
Language models (LMs) increasingly drive real-world applications that require world knowledge. However, the internal processes through which models turn data into representations of knowledge and beliefs about the world, are poorly understood. Insights into these processes could pave the way for developing LMs with knowledge representations that are more consistent, robust, and complete. To facilitate studying these questions, we present LMEnt, a suite for analyzing knowledge acquisition in LMs during pretraining. LMEnt introduces: (1) a knowledge-rich pretraining corpus, fully annotated with entity mentions, based on Wikipedia, (2) an entity-based retrieval method over pretraining data that outperforms previous approaches by as much as 80.4%, and (3) 12 pretrained models with up to 1B parameters and 4K intermediate checkpoints, with comparable performance to popular open-sourced models on knowledge benchmarks. Together, these resources provide a controlled environment for analyzing connections between entity mentions in pretraining and downstream performance, and the effects of causal interventions in pretraining data. We show the utility of LMEnt by studying knowledge acquisition across checkpoints, finding that fact frequency is key, but does not fully explain learning trends. We release LMEnt to support studies of knowledge in LMs, including knowledge representations, plasticity, editing, attribution, and learning dynamics.