 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Master Key Hypothesis: Unlocking Cross-Model Capability Transfer via Linear Subspace Alignment
Apr 07, 2026We investigate whether post-trained capabilities can be transferred across models without retraining, with a focus on transfer across different model scales. We propose the Master Key Hypothesis, which states that model capabilities correspond to directions in a low-dimensional latent subspace that induce specific behaviors and are transferable across models through linear alignment. Based on this hypothesis, we introduce UNLOCK, a training-free and label-free framework that extracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation, and applies it at inference time to elicit the behavior. Experiments on reasoning behaviors, including Chain-of-Thought (CoT) and mathematical reasoning, demonstrate substantial improvements across model scales without training. For example, transferring CoT reasoning from Qwen1.5-14B to Qwen1.5-7B yields an accuracy gain of 12.1% on MATH, and transferring a mathematical reasoning direction from Qwen3-4B-Base to Qwen3-14B-Base improves AGIEval Math accuracy from 61.1% to 71.3%, surpassing the 67.8% achieved by the 14B post-trained model. Our analysis shows that the success of transfer depends on the capabilities learned during pre-training, and that our intervention amplifies latent capabilities by sharpening the output distribution toward successful reasoning trajectories.
Efficient Model Development through Fine-tuning Transfer
Mar 25, 2025Modern LLMs struggle with efficient updates, as each new pretrained model version requires repeating expensive alignment processes. This challenge also applies to domain- or language-specific models, where fine-tuning on specialized data must be redone for every new base model release. In this paper, we explore the transfer of fine-tuning updates between model versions. Specifically, we derive the diff vector from one source model version, which represents the weight changes from fine-tuning, and apply it to the base model of a different target version. Through empirical evaluations on various open-weight model versions, we show that transferring diff vectors can significantly improve the target base model, often achieving performance comparable to its fine-tuned counterpart. For example, reusing the fine-tuning updates from Llama 3.0 8B leads to an absolute accuracy improvement of 10.7% on GPQA over the base Llama 3.1 8B without additional training, surpassing Llama 3.1 8B Instruct. In a multilingual model development setting, we show that this approach can significantly increase performance on target-language tasks without retraining, achieving an absolute improvement of 4.7% and 15.5% on Global MMLU for Malagasy and Turkish, respectively, compared to Llama 3.1 8B Instruct. Our controlled experiments reveal that fine-tuning transfer is most effective when the source and target models are linearly connected in the parameter space. Additionally, we demonstrate that fine-tuning transfer offers a stronger and more computationally efficient starting point for further fine-tuning. Finally, we propose an iterative recycling-then-finetuning approach for continuous model development, which improves both efficiency and effectiveness. Our findings suggest that fine-tuning transfer is a viable strategy to reduce training costs while maintaining model performance.
Self-Vocabularizing Training for Neural Machine Translation
Mar 19, 2025

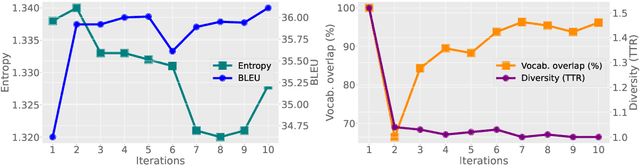

Past vocabulary learning techniques identify relevant vocabulary before training, relying on statistical and entropy-based assumptions that largely neglect the role of model training. Empirically, we observe that trained translation models are induced to use a byte-pair encoding (BPE) vocabulary subset distinct from the original BPE vocabulary, leading to performance improvements when retrained with the induced vocabulary. In this paper, we analyze this discrepancy in neural machine translation by examining vocabulary and entropy shifts during self-training--where each iteration generates a labeled dataset by pairing source sentences with the model's predictions to define a new vocabulary. Building on these insights, we propose self-vocabularizing training, an iterative method that self-selects a smaller, more optimal vocabulary, yielding up to a 1.49 BLEU improvement. Moreover, we find that deeper model architectures lead to both an increase in unique token usage and a 6-8% reduction in vocabulary size.
Scaling Parameter-Constrained Language Models with Quality Data
Oct 04, 2024



Scaling laws in language modeling traditionally quantify training loss as a function of dataset size and model parameters, providing compute-optimal estimates but often neglecting the impact of data quality on model generalization. In this paper, we extend the conventional understanding of scaling law by offering a microscopic view of data quality within the original formulation -- effective training tokens -- which we posit to be a critical determinant of performance for parameter-constrained language models. Specifically, we formulate the proposed term of effective training tokens to be a combination of two readily-computed indicators of text: (i) text diversity and (ii) syntheticity as measured by a teacher model. We pretrained over $200$ models of 25M to 1.5B parameters on a diverse set of sampled, synthetic data, and estimated the constants that relate text quality, model size, training tokens, and eight reasoning task accuracy scores. We demonstrated the estimated constants yield +0.83 Pearson correlation with true accuracies, and analyzed it in scenarios involving widely-used data techniques such as data sampling and synthesis which aim to improve data quality.
Exploring the Effectiveness and Consistency of Task Selection in Intermediate-Task Transfer Learning
Jul 23, 2024



Identifying beneficial tasks to transfer from is a critical step toward successful intermediate-task transfer learning. In this work, we experiment with 130 source-target task combinations and demonstrate that the transfer performance exhibits severe variance across different source tasks and training seeds, highlighting the crucial role of intermediate-task selection in a broader context. We compare four representative task selection methods in a unified setup, focusing on their effectiveness and consistency. Compared to embedding-free methods and text embeddings, task embeddings constructed from fine-tuned weights can better estimate task transferability by improving task prediction scores from 2.59% to 3.96%. Despite their strong performance, we observe that the task embeddings do not consistently demonstrate superiority for tasks requiring reasoning abilities. Furthermore, we introduce a novel method that measures pairwise token similarity using maximum inner product search, leading to the highest performance in task prediction. Our findings suggest that token-wise similarity is better predictive for predicting transferability compared to averaging weights.
Modeling Orthographic Variation Improves NLP Performance for Nigerian Pidgin
Apr 28, 2024Nigerian Pidgin is an English-derived contact language and is traditionally an oral language, spoken by approximately 100 million people. No orthographic standard has yet been adopted, and thus the few available Pidgin datasets that exist are characterised by noise in the form of orthographic variations. This contributes to under-performance of models in critical NLP tasks. The current work is the first to describe various types of orthographic variations commonly found in Nigerian Pidgin texts, and model this orthographic variation. The variations identified in the dataset form the basis of a phonetic-theoretic framework for word editing, which is used to generate orthographic variations to augment training data. We test the effect of this data augmentation on two critical NLP tasks: machine translation and sentiment analysis. The proposed variation generation framework augments the training data with new orthographic variants which are relevant for the test set but did not occur in the training set originally. Our results demonstrate the positive effect of augmenting the training data with a combination of real texts from other corpora as well as synthesized orthographic variation, resulting in performance improvements of 2.1 points in sentiment analysis and 1.4 BLEU points in translation to English.
On The Open Prompt Challenge In Conditional Audio Generation
Nov 01, 2023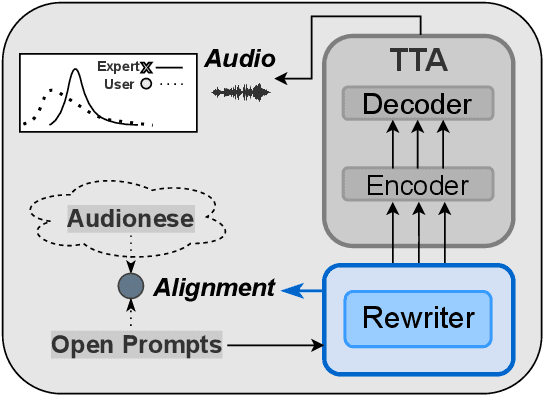
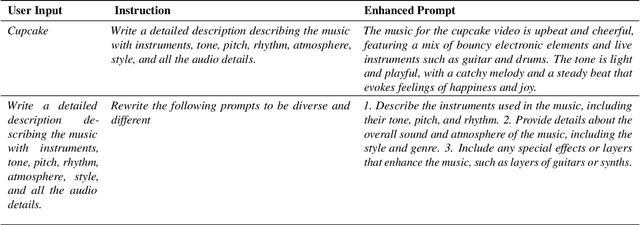
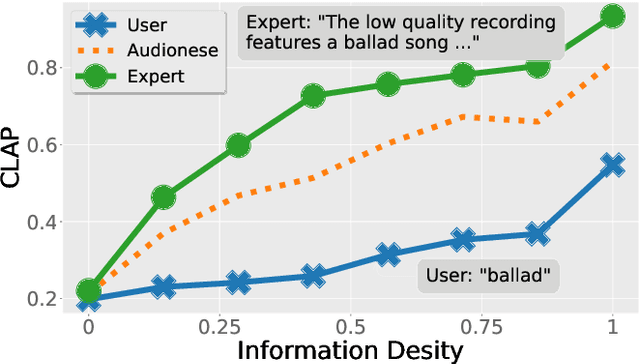
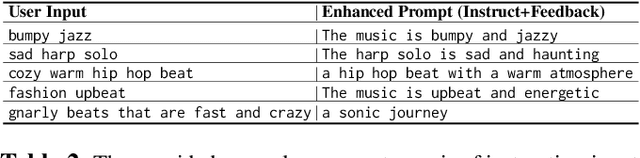
Text-to-audio generation (TTA) produces audio from a text description, learning from pairs of audio samples and hand-annotated text. However, commercializing audio generation is challenging as user-input prompts are often under-specified when compared to text descriptions used to train TTA models. In this work, we treat TTA models as a ``blackbox'' and address the user prompt challenge with two key insights: (1) User prompts are generally under-specified, leading to a large alignment gap between user prompts and training prompts. (2) There is a distribution of audio descriptions for which TTA models are better at generating higher quality audio, which we refer to as ``audionese''. To this end, we rewrite prompts with instruction-tuned models and propose utilizing text-audio alignment as feedback signals via margin ranking learning for audio improvements. On both objective and subjective human evaluations, we observed marked improvements in both text-audio alignment and music audio quality.
In-Context Prompt Editing For Conditional Audio Generation
Nov 01, 2023Distributional shift is a central challenge in the deployment of machine learning models as they can be ill-equipped for real-world data. This is particularly evident in text-to-audio generation where the encoded representations are easily undermined by unseen prompts, which leads to the degradation of generated audio -- the limited set of the text-audio pairs remains inadequate for conditional audio generation in the wild as user prompts are under-specified. In particular, we observe a consistent audio quality degradation in generated audio samples with user prompts, as opposed to training set prompts. To this end, we present a retrieval-based in-context prompt editing framework that leverages the training captions as demonstrative exemplars to revisit the user prompts. We show that the framework enhanced the audio quality across the set of collected user prompts, which were edited with reference to the training captions as exemplars.
Revisiting Sample Size Determination in Natural Language Understanding
Jul 01, 2023



Knowing exactly how many data points need to be labeled to achieve a certain model performance is a hugely beneficial step towards reducing the overall budgets for annotation. It pertains to both active learning and traditional data annotation, and is particularly beneficial for low resource scenarios. Nevertheless, it remains a largely under-explored area of research in NLP. We therefore explored various techniques for estimating the training sample size necessary to achieve a targeted performance value. We derived a simple yet effective approach to predict the maximum achievable model performance based on small amount of training samples - which serves as an early indicator during data annotation for data quality and sample size determination. We performed ablation studies on four language understanding tasks, and showed that the proposed approach allows us to forecast model performance within a small margin of mean absolute error (~ 0.9%) with only 10% data.
Low-Resource Cross-Lingual Adaptive Training for Nigerian Pidgin
Jul 01, 2023Developing effective spoken language processing systems for low-resource languages poses several challenges due to the lack of parallel data and limited resources for fine-tuning models. In this work, we target on improving upon both text classification and translation of Nigerian Pidgin (Naija) by collecting a large-scale parallel English-Pidgin corpus and further propose a framework of cross-lingual adaptive training that includes both continual and task adaptive training so as to adapt a base pre-trained model to low-resource languages. Our studies show that English pre-trained language models serve as a stronger prior than multilingual language models on English-Pidgin tasks with up to 2.38 BLEU improvements; and demonstrate that augmenting orthographic data and using task adaptive training with back-translation can have a significant impact on model performance.