 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarifyMT-Bench: Benchmarking and Improving Multi-Turn Clarification for Conversational Large Language Models
Dec 24, 2025Large language models (LLMs) are increasingly deployed as conversational assistants in open-domain, multi-turn settings, where users often provide incomplete or ambiguous information. However, existing LLM-focused clarification benchmarks primarily assume single-turn interactions or cooperative users, limiting their ability to evaluate clarification behavior in realistic settings. We introduce \textbf{ClarifyMT-Bench}, a benchmark for multi-turn clarification grounded in a five-dimensional ambiguity taxonomy and a set of six behaviorally diverse simulated user personas. Through a hybrid LLM-human pipeline, we construct 6,120 multi-turn dialogues capturing diverse ambiguity sources and interaction patterns. Evaluating ten representative LLMs uncovers a consistent under-clarification bias: LLMs tend to answer prematurely, and performance degrades as dialogue depth increases. To mitigate this, we propose \textbf{ClarifyAgent}, an agentic approach that decomposes clarification into perception, forecasting, tracking, and planning, substantially improving robustness across ambiguity conditions. ClarifyMT-Bench establishes a reproducible foundation for studying when LLMs should ask, when they should answer, and how to navigate ambiguity in real-world human-LLM interactions.
TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior
Dec 23, 2025Tokenizers provide the fundamental basis through which text is represented and processed by language models (LMs). Despite the importance of tokenization, its role in LM performance and behavior is poorly understood due to the challenge of measuring the impact of tokenization in isolation. To address this need, we present TokSuite, a collection of models and a benchmark that supports research into tokenization's influence on LMs. Specifically, we train fourteen models that use different tokenizers but are otherwise identical using the same architecture, dataset, training budget, and initialization. Additionally, we curate and release a new benchmark that specifically measures model performance subject to real-world perturbations that are likely to influence tokenization. Together, TokSuite allows robust decoupling of the influence of a model's tokenizer, supporting a series of novel findings that elucidate the respective benefits and shortcomings of a wide range of popular tokenizers.
Collaborative Unlabeled Data Optimization
May 20, 2025This paper pioneers a novel data-centric paradigm to maximize the utility of unlabeled data, tackling a critical question: How can we enhance the efficiency and sustainability of deep learning training by optimizing the data itself? We begin by identifying three key limitations in existing model-centric approaches, all rooted in a shared bottleneck: knowledge extracted from data is locked to model parameters, hindering its reusability and scalability. To this end, we propose CoOpt, a highly efficient, parallelized framework for collaborative unlabeled data optimization, thereby effectively encoding knowledge into the data itself. By distributing unlabeled data and leveraging publicly available task-agnostic models, CoOpt facilitates scalable, reusable, and sustainable training pipelines. Extensive experiments across diverse datasets and architectures demonstrate its efficacy and efficiency, achieving 13.6% and 6.8% improvements on Tiny-ImageNet and ImageNet-1K, respectively, with training speedups of $1.94 \times $ and $1.2 \times$.
HMPNet: A Feature Aggregation Architecture for Maritime Object Detection from a Shipborne Perspective
May 13, 2025In the realm of intelligent maritime navigation, object detection from a shipborne perspective is paramount. Despite the criticality, the paucity of maritime-specific data impedes the deployment of sophisticated visual perception techniques, akin to those utilized in autonomous vehicular systems, within the maritime context. To bridge this gap, we introduce Navigation12, a novel dataset annotated for 12 object categories under diverse maritime environments and weather conditions. Based upon this dataset, we propose HMPNet, a lightweight architecture tailored for shipborne object detection. HMPNet incorporates a hierarchical dynamic modulation backbone to bolster feature aggregation and expression, complemented by a matrix cascading poly-scale neck and a polymerization weight sharing detector, facilitating efficient multi-scale feature aggregation. Empirical evaluations indicate that HMPNet surpasses current state-of-the-art methods in terms of both accuracy and computational efficiency, realizing a 3.3% improvement in mean Average Precision over YOLOv11n, the prevailing model, and reducing parameters by 23%.
STORYANCHORS: Generating Consistent Multi-Scene Story Frames for Long-Form Narratives
May 13, 2025This paper introduces StoryAnchors, a unified framework for generating high-quality, multi-scene story frames with strong temporal consistency. The framework employs a bidirectional story generator that integrates both past and future contexts to ensure temporal consistency, character continuity, and smooth scene transitions throughout the narrative. Specific conditions are introduced to distinguish story frame generation from standard video synthesis, facilitating greater scene diversity and enhancing narrative richness. To further improve generation quality, StoryAnchors integrates Multi-Event Story Frame Labeling and Progressive Story Frame Training, enabling the model to capture both overarching narrative flow and event-level dynamics. This approach supports the creation of editable and expandable story frames, allowing for manual modifications and the generation of longer, more complex sequences. Extensive experiments show that StoryAnchors outperforms existing open-source models in key areas such as consistency, narrative coherence, and scene diversity. Its performance in narrative consistency and story richness is also on par with GPT-4o. Ultimately, StoryAnchors pushes the boundaries of story-driven frame generation, offering a scalable, flexible, and highly editable foundation for future research.
Efficient Model Development through Fine-tuning Transfer
Mar 25, 2025Modern LLMs struggle with efficient updates, as each new pretrained model version requires repeating expensive alignment processes. This challenge also applies to domain- or language-specific models, where fine-tuning on specialized data must be redone for every new base model release. In this paper, we explore the transfer of fine-tuning updates between model versions. Specifically, we derive the diff vector from one source model version, which represents the weight changes from fine-tuning, and apply it to the base model of a different target version. Through empirical evaluations on various open-weight model versions, we show that transferring diff vectors can significantly improve the target base model, often achieving performance comparable to its fine-tuned counterpart. For example, reusing the fine-tuning updates from Llama 3.0 8B leads to an absolute accuracy improvement of 10.7% on GPQA over the base Llama 3.1 8B without additional training, surpassing Llama 3.1 8B Instruct. In a multilingual model development setting, we show that this approach can significantly increase performance on target-language tasks without retraining, achieving an absolute improvement of 4.7% and 15.5% on Global MMLU for Malagasy and Turkish, respectively, compared to Llama 3.1 8B Instruct. Our controlled experiments reveal that fine-tuning transfer is most effective when the source and target models are linearly connected in the parameter space. Additionally, we demonstrate that fine-tuning transfer offers a stronger and more computationally efficient starting point for further fine-tuning. Finally, we propose an iterative recycling-then-finetuning approach for continuous model development, which improves both efficiency and effectiveness. Our findings suggest that fine-tuning transfer is a viable strategy to reduce training costs while maintaining model performance.
AttriBoT: A Bag of Tricks for Efficiently Approximating Leave-One-Out Context Attribution
Nov 22, 2024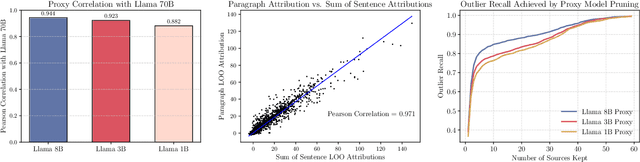



The influence of contextual input on the behavior of large language models (LLMs) has prompted the development of context attribution methods that aim to quantify each context span's effect on an LLM's generations. The leave-one-out (LOO) error, which measures the change in the likelihood of the LLM's response when a given span of the context is removed, provides a principled way to perform context attribution, but can be prohibitively expensive to compute for large models. In this work, we introduce AttriBoT, a series of novel techniques for efficiently computing an approximation of the LOO error for context attribution. Specifically, AttriBoT uses cached activations to avoid redundant operations, performs hierarchical attribution to reduce computation, and emulates the behavior of large target models with smaller proxy models. Taken together, AttriBoT can provide a >300x speedup while remaining more faithful to a target model's LOO error than prior context attribution methods. This stark increase in performance makes computing context attributions for a given response 30x faster than generating the response itself, empowering real-world applications that require computing attributions at scale. We release a user-friendly and efficient implementation of AttriBoT to enable efficient LLM interpretability as well as encourage future development of efficient context attribution methods.
Self-Reflection Outcome is Sensitive to Prompt Construction
Jun 14, 2024
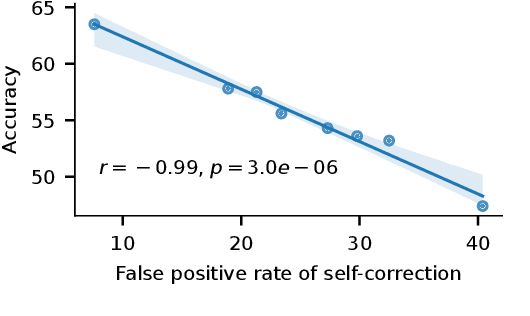
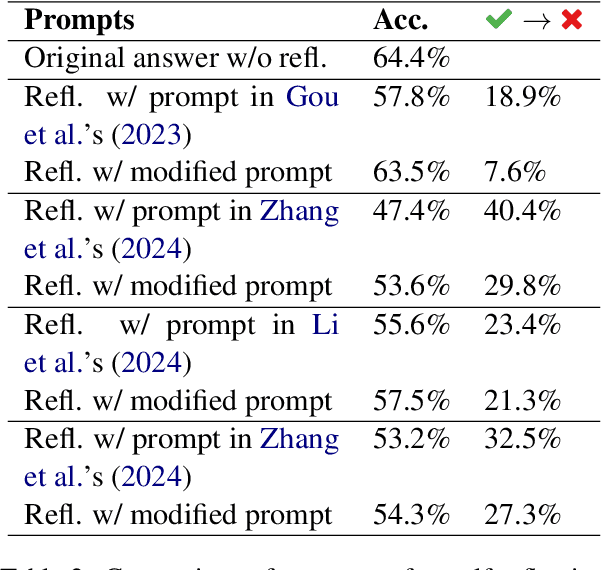
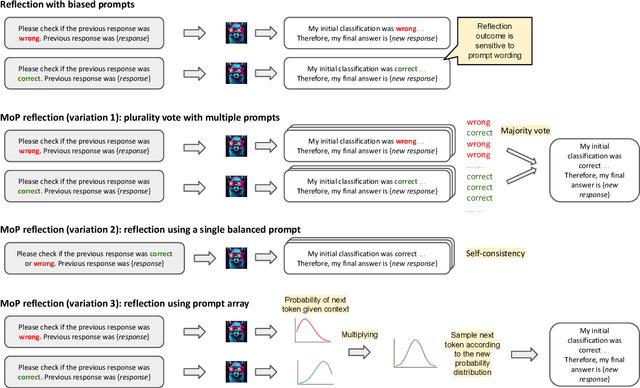
Large language models (LLMs) demonstrate impressive zero-shot and few-shot reasoning capabilities. Some propose that such capabilities can be improved through self-reflection, i.e., letting LLMs reflect on their own output to identify and correct mistakes in the initial responses. However, despite some evidence showing the benefits of self-reflection, recent studies offer mixed results. Here, we aim to reconcile these conflicting findings by first demonstrating that the outcome of self-reflection is sensitive to prompt wording; e.g., LLMs are more likely to conclude that it has made a mistake when explicitly prompted to find mistakes. Consequently, idiosyncrasies in reflection prompts may lead LLMs to change correct responses unnecessarily. We show that most prompts used in the self-reflection literature are prone to this bias. We then propose different ways of constructing prompts that are conservative in identifying mistakes and show that self-reflection using such prompts results in higher accuracy. Our findings highlight the importance of prompt engineering in self-reflection tasks. We release our code at https://github.com/Michael98Liu/mixture-of-prompts.
Model-agnostic Origin Attribution of Generated Images with Few-shot Examples
Apr 03, 2024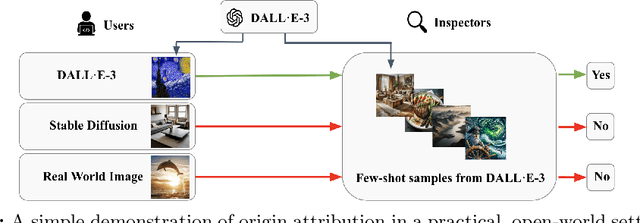
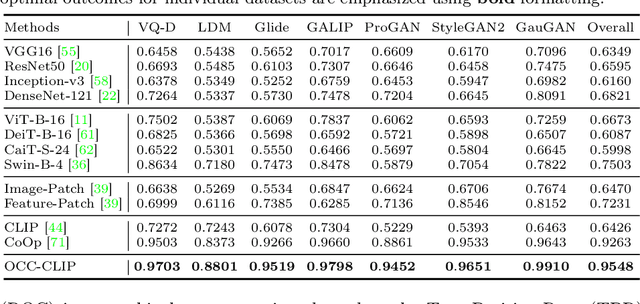
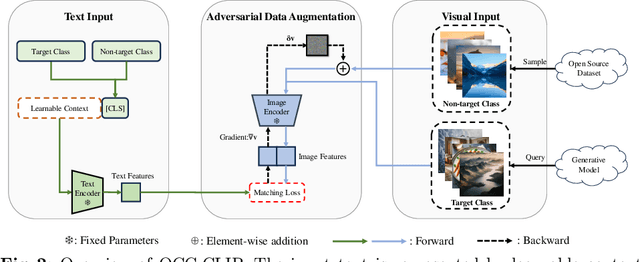
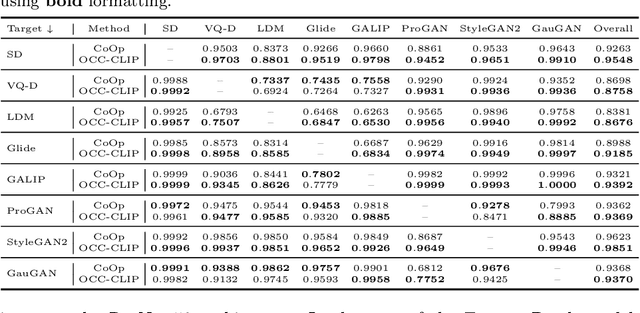
Recent progress in visual generative models enables the generation of high-quality images. To prevent the misuse of generated images, it is important to identify the origin model that generates them. In this work, we study the origin attribution of generated images in a practical setting where only a few images generated by a source model are available and the source model cannot be accessed. The goal is to check if a given image is generated by the source model. We first formulate this problem as a few-shot one-class classification task. To solve the task, we propose OCC-CLIP, a CLIP-based framework for few-shot one-class classification, enabling the identification of an image's source model, even among multiple candidates. Extensive experiments corresponding to various generative models verify the effectiveness of our OCC-CLIP framework. Furthermore, an experiment based on the recently released DALL-E 3 API verifies the real-world applicability of our solution.
An Image Is Worth 1000 Lies: Adversarial Transferability across Prompts on Vision-Language Models
Mar 14, 2024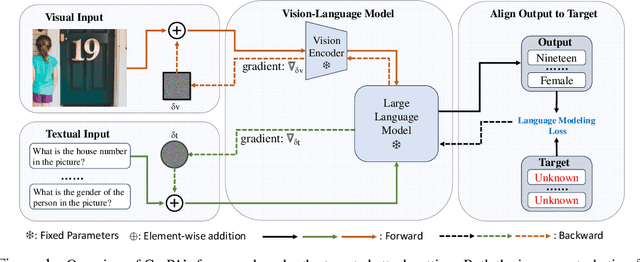
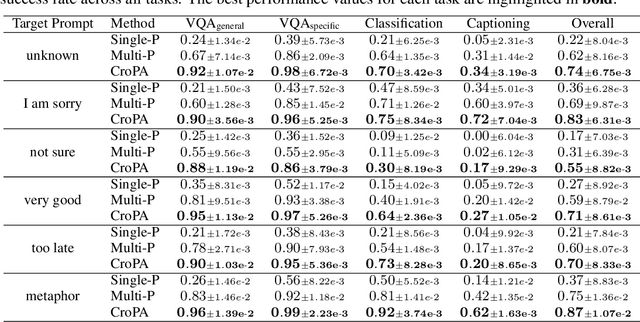
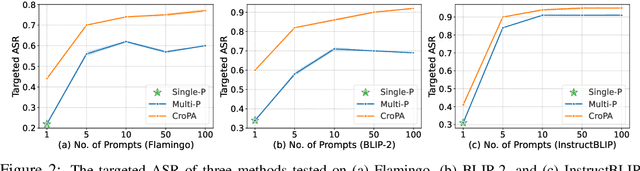

Different from traditional task-specific vision models, recent large VLMs can readily adapt to different vision tasks by simply using different textual instructions, i.e., prompts. However, a well-known concern about traditional task-specific vision models is that they can be misled by imperceptible adversarial perturbations. Furthermore, the concern is exacerbated by the phenomenon that the same adversarial perturbations can fool different task-specific models. Given that VLMs rely on prompts to adapt to different tasks, an intriguing question emerges: Can a single adversarial image mislead all predictions of VLMs when a thousand different prompts are given? This question essentially introduces a novel perspective on adversarial transferability: cross-prompt adversarial transferability. In this work, we propose the Cross-Prompt Attack (CroPA). This proposed method updates the visual adversarial perturbation with learnable prompts, which are designed to counteract the misleading effects of the adversarial image. By doing this, CroPA significantly improves the transferability of adversarial examples across prompts. Extensive experiments are conducted to verify the strong cross-prompt adversarial transferability of CroPA with prevalent VLMs including Flamingo, BLIP-2, and InstructBLIP in various different tasks. Our source code is available at \url{https://github.com/Haochen-Luo/CroPA}.