 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustry-Aligned Granular Topic Modeling
Jan 16, 2026Topic modeling has extensive applications in text mining and data analysis across various industrial sectors. Although the concept of granularity holds significant value for business applications by providing deeper insights, the capability of topic modeling methods to produce granular topics has not been thoroughly explored. In this context, this paper introduces a framework called TIDE, which primarily provides a novel granular topic modeling method based on large language models (LLMs) as a core feature, along with other useful functionalities for business applications, such as summarizing long documents, topic parenting, and distillation. Through extensive experiments on a variety of public and real-world business datasets, we demonstrate that TIDE's topic modeling approach outperforms modern topic modeling methods, and our auxiliary components provide valuable support for dealing with industrial business scenarios. The TIDE framework is currently undergoing the process of being open sourced.
Tuning Language Models by Mixture-of-Depths Ensemble
Oct 16, 2024Transformer-based Large Language Models (LLMs) traditionally rely on final-layer loss for training and final-layer representations for predictions, potentially overlooking the predictive power embedded in intermediate layers. Surprisingly, we find that focusing training efforts on these intermediate layers can yield training losses comparable to those of final layers, with complementary test-time performance. We introduce a novel tuning framework, Mixture-of-Depths (MoD), which trains late layers as ensembles contributing to the final logits through learned routing weights. With the auxiliary distillation loss and additional normalization modules, we ensure that the outputs of the late layers adapt to language modeling. Our MoD framework, which can be integrated with any existing tuning method, shows consistent improvement on various language modelling tasks. Furthermore, by replacing traditional trainable modules with MoD, our approach achieves similar performance with significantly fewer trainable parameters, demonstrating the potential of leveraging predictive power from intermediate representations during training.
From Understanding to Utilization: A Survey on Explainability for Large Language Models
Jan 23, 2024This survey paper delves into the burgeoning field of explainability for Large Language Models (LLMs), a critical yet challenging aspect of natural language processing. With LLMs playing a pivotal role in various applications, their "black-box" nature raises concerns about transparency and ethical use. This paper emphasizes the necessity for enhanced explainability in LLMs, addressing both the general public's trust and the technical community's need for a deeper understanding of these models. We concentrate on pre-trained Transformer-based LLMs, such as LLaMA, which present unique interpretability challenges due to their scale and complexity. Our review categorizes existing explainability methods and discusses their application in improving model transparency and reliability. We also discuss representative evaluation methods, highlighting their strengths and limitations. The goal of this survey is to bridge the gap between theoretical understanding and practical application, offering insights for future research and development in the field of LLM explainability.
OpenFE: Automated Feature Generation beyond Expert-level Performance
Nov 22, 2022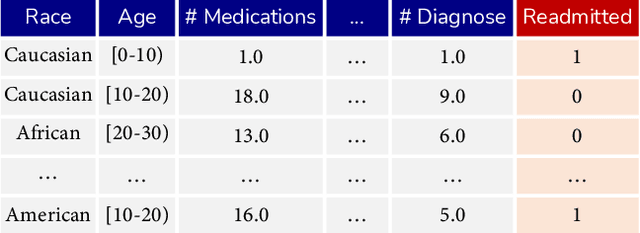

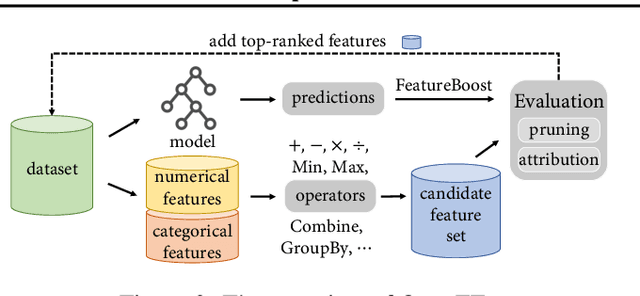
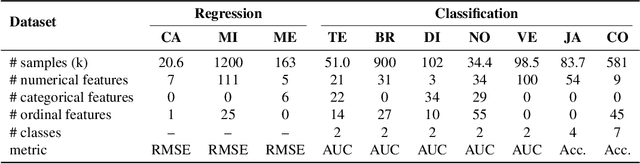
The goal of automated feature generation is to liberate machine learning experts from the laborious task of manual feature generation, which is crucial for improving the learning performance of tabular data. The major challenge in automated feature generation is to efficiently and accurately identify useful features from a vast pool of candidate features. In this paper, we present OpenFE, an automated feature generation tool that provides competitive results against machine learning experts. OpenFE achieves efficiency and accuracy with two components: 1) a novel feature boosting method for accurately estimating the incremental performance of candidate features. 2) a feature-scoring framework for retrieving effective features from a large number of candidates through successive featurewise halving and feature importance attribution. Extensive experiments on seven benchmark datasets show that OpenFE outperforms existing baseline methods. We further evaluate OpenFE in two famous Kaggle competitions with thousands of data science teams participating. In one of the competitions, features generated by OpenFE with a simple baseline model can beat 99.3\% data science teams. In addition to the empirical results, we provide a theoretical perspective to show that feature generation is beneficial in a simple yet representative setting. The code is available at https://github.com/ZhangTP1996/OpenFE.