 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Gradient Boosting Decision Tree with Unbiased Feature Importance
May 18, 2023



Gradient Boosting Decision Tree (GBDT) has achieved remarkable success in a wide variety of applications. The split finding algorithm, which determines the tree construction process, is one of the most crucial components of GBDT. However, the split finding algorithm has long been criticized for its bias towards features with a large number of potential splits. This bias introduces severe interpretability and overfitting issues in GBDT. To this end, we provide a fine-grained analysis of bias in GBDT and demonstrate that the bias originates from 1) the systematic bias in the gain estimation of each split and 2) the bias in the split finding algorithm resulting from the use of the same data to evaluate the split improvement and determine the best split. Based on the analysis, we propose unbiased gain, a new unbiased measurement of gain importance using out-of-bag samples. Moreover, we incorporate the unbiased property into the split finding algorithm and develop UnbiasedGBM to solve the overfitting issue of GBDT. We assess the performance of UnbiasedGBM and unbiased gain in a large-scale empirical study comprising 60 datasets and show that: 1) UnbiasedGBM exhibits better performance than popular GBDT implementations such as LightGBM, XGBoost, and Catboost on average on the 60 datasets and 2) unbiased gain achieves better average performance in feature selection than popular feature importance methods. The codes are available at https://github.com/ZheyuAqaZhang/UnbiasedGBM.
Generative Table Pre-training Empowers Models for Tabular Prediction
May 16, 2023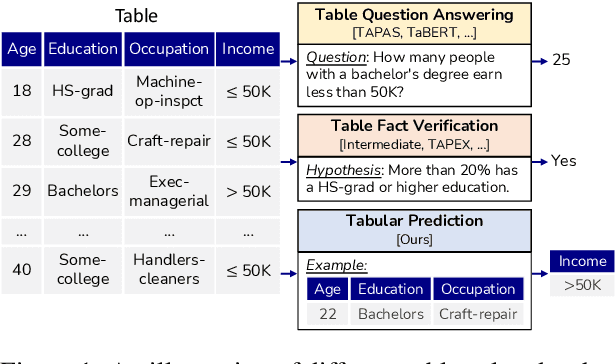
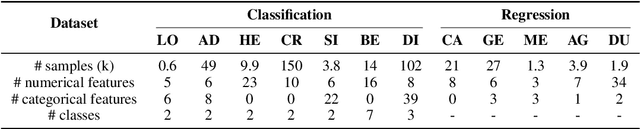
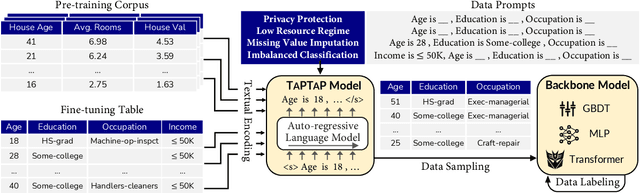
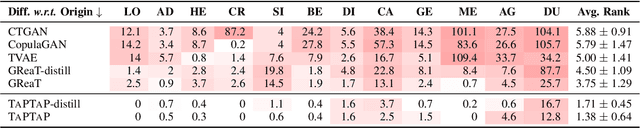
Recently, the topic of table pre-training has attracted considerable research interest. However, how to employ table pre-training to boost the performance of tabular prediction remains an open challenge. In this paper, we propose TapTap, the first attempt that leverages table pre-training to empower models for tabular prediction. After pre-training on a large corpus of real-world tabular data, TapTap can generate high-quality synthetic tables to support various applications on tabular data, including privacy protection, low resource regime, missing value imputation, and imbalanced classification. Extensive experiments on 12 datasets demonstrate that TapTap outperforms a total of 16 baselines in different scenarios. Meanwhile, it can be easily combined with various backbone models, including LightGBM, Multilayer Perceptron (MLP) and Transformer. Moreover, with the aid of table pre-training, models trained using synthetic data generated by TapTap can even compete with models using the original dataset on half of the experimental datasets, marking a milestone in the development of synthetic tabular data generation. The codes are available at https://github.com/ZhangTP1996/TapTap.
OpenFE: Automated Feature Generation beyond Expert-level Performance
Nov 22, 2022

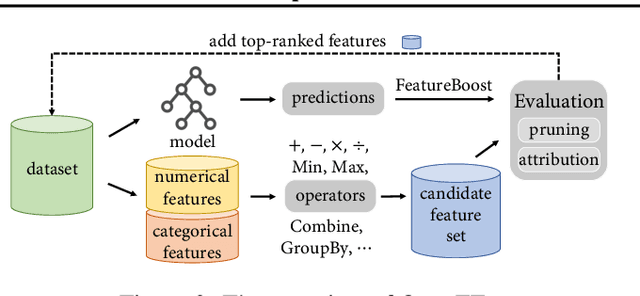
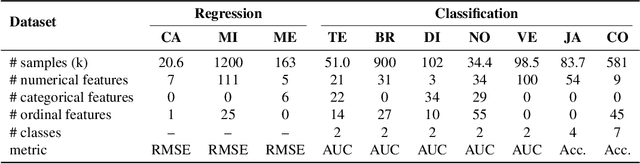
The goal of automated feature generation is to liberate machine learning experts from the laborious task of manual feature generation, which is crucial for improving the learning performance of tabular data. The major challenge in automated feature generation is to efficiently and accurately identify useful features from a vast pool of candidate features. In this paper, we present OpenFE, an automated feature generation tool that provides competitive results against machine learning experts. OpenFE achieves efficiency and accuracy with two components: 1) a novel feature boosting method for accurately estimating the incremental performance of candidate features. 2) a feature-scoring framework for retrieving effective features from a large number of candidates through successive featurewise halving and feature importance attribution. Extensive experiments on seven benchmark datasets show that OpenFE outperforms existing baseline methods. We further evaluate OpenFE in two famous Kaggle competitions with thousands of data science teams participating. In one of the competitions, features generated by OpenFE with a simple baseline model can beat 99.3\% data science teams. In addition to the empirical results, we provide a theoretical perspective to show that feature generation is beneficial in a simple yet representative setting. The code is available at https://github.com/ZhangTP1996/OpenFE.
Less Is More: Fast Multivariate Time Series Forecasting with Light Sampling-oriented MLP Structures
Jul 04, 2022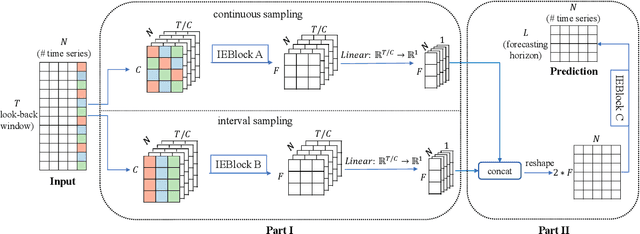
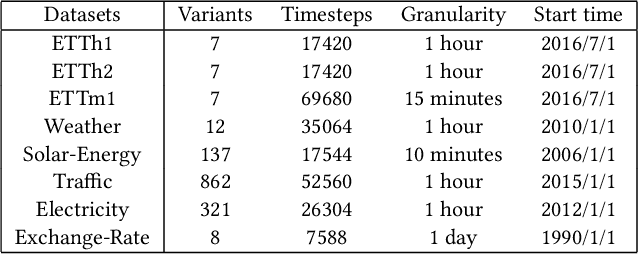
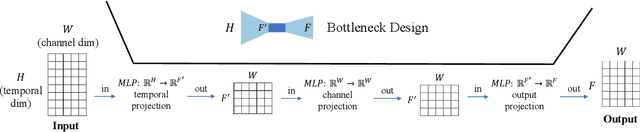
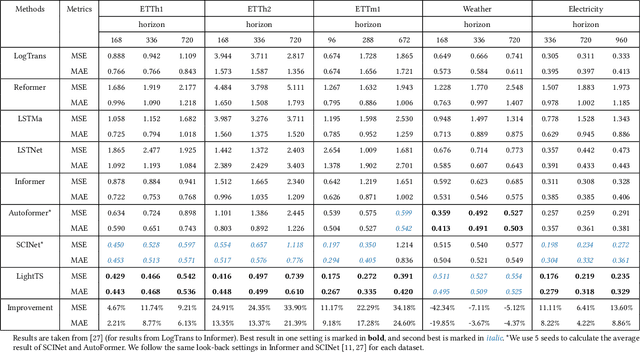
Multivariate time series forecasting has seen widely ranging applications in various domains, including finance, traffic, energy, and healthcare. To capture the sophisticated temporal patterns, plenty of research studies designed complex neural network architectures based on many variants of RNNs, GNNs, and Transformers. However, complex models are often computationally expensive and thus face a severe challenge in training and inference efficiency when applied to large-scale real-world datasets. In this paper, we introduce LightTS, a light deep learning architecture merely based on simple MLP-based structures. The key idea of LightTS is to apply an MLP-based structure on top of two delicate down-sampling strategies, including interval sampling and continuous sampling, inspired by a crucial fact that down-sampling time series often preserves the majority of its information. We conduct extensive experiments on eight widely used benchmark datasets. Compared with the existing state-of-the-art methods, LightTS demonstrates better performance on five of them and comparable performance on the rest. Moreover, LightTS is highly efficient. It uses less than 5% FLOPS compared with previous SOTA methods on the largest benchmark dataset. In addition, LightTS is robust and has a much smaller variance in forecasting accuracy than previous SOTA methods in long sequence forecasting tasks.