 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image Is Worth 1000 Lies: Adversarial Transferability across Prompts on Vision-Language Models
Paper and Code
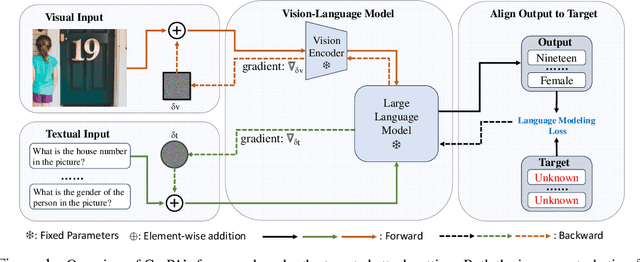
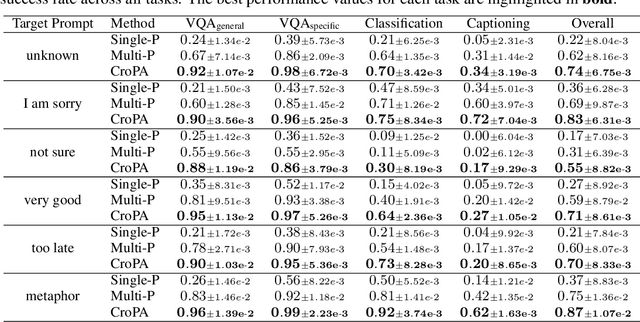
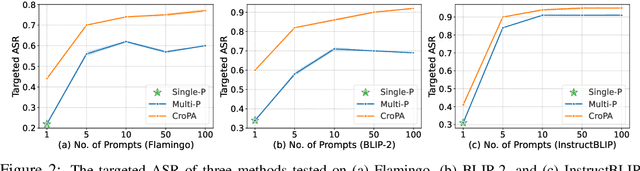

Different from traditional task-specific vision models, recent large VLMs can readily adapt to different vision tasks by simply using different textual instructions, i.e., prompts. However, a well-known concern about traditional task-specific vision models is that they can be misled by imperceptible adversarial perturbations. Furthermore, the concern is exacerbated by the phenomenon that the same adversarial perturbations can fool different task-specific models. Given that VLMs rely on prompts to adapt to different tasks, an intriguing question emerges: Can a single adversarial image mislead all predictions of VLMs when a thousand different prompts are given? This question essentially introduces a novel perspective on adversarial transferability: cross-prompt adversarial transferability. In this work, we propose the Cross-Prompt Attack (CroPA). This proposed method updates the visual adversarial perturbation with learnable prompts, which are designed to counteract the misleading effects of the adversarial image. By doing this, CroPA significantly improves the transferability of adversarial examples across prompts. Extensive experiments are conducted to verify the strong cross-prompt adversarial transferability of CroPA with prevalent VLMs including Flamingo, BLIP-2, and InstructBLIP in various different tasks. Our source code is available at \url{https://github.com/Haochen-Luo/CroPA}.