 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuned Vision Language Model for Localization of Parasitic Eggs in Microscopic Images
Feb 14, 2026Soil-transmitted helminth (STH) infections continuously affect a large proportion of the global population, particularly in tropical and sub-tropical regions, where access to specialized diagnostic expertise is limited. Although manual microscopic diagnosis of parasitic eggs remains the diagnostic gold standard, the approach can be labour-intensive, time-consuming, and prone to human error. This paper aims to utilize a vision language model (VLM) such as Microsoft Florence that was fine-tuned to localize all parasitic eggs within microscopic images. The preliminary results show that our localization VLM performs comparatively better than the other object detection methods, such as EfficientDet, with an mIOU of 0.94. This finding demonstrates the potential of the proposed VLM to serve as a core component of an automated framework, offering a scalable engineering solution for intelligent parasitological diagnosis.
Semantic-Aware Advanced Persistent Threat Detection Using Autoencoders on LLM-Encoded System Logs
Jan 30, 2026Advanced Persistent Threats (APTs) are among the most challenging cyberattacks to detect. They are carried out by highly skilled attackers who carefully study their targets and operate in a stealthy, long-term manner. Because APTs exhibit "low-and-slow" behavior, traditional statistical methods and shallow machine learning techniques often fail to detect them. Previous research on APT detection has explored machine learning approaches and provenance graph analysis. However, provenance-based methods often fail to capture the semantic intent behind system activities. This paper proposes a novel anomaly detection approach that leverages semantic embeddings generated by Large Language Models (LLMs). The method enhances APT detection by extracting meaningful semantic representations from unstructured system log data. First, raw system logs are transformed into high-dimensional semantic embeddings using a pre-trained transformer model. These embeddings are then analyzed using an Autoencoder (AE) to identify anomalous and potentially malicious patterns. The proposed method is evaluated using the DARPA Transparent Computing (TC) dataset, which contains realistic APT attack scenarios generated by red teams in live environments. Experimental results show that the AE trained on LLM-derived embeddings outperforms widely used unsupervised baseline methods, including Isolation Forest (IForest), One-Class Support Vector Machine (OC-SVM), and Principal Component Analysis (PCA). Performance is measured using the Area Under the Receiver Operating Characteristic Curve (AUC-ROC), where the proposed approach consistently achieves superior results, even in complex threat scenarios. These findings highlight the importance of semantic understanding in detecting non-linear and stealthy attack behaviors that are often missed by conventional detection techniques.
Real-Time Human Detection for Aerial Captured Video Sequences via Deep Models
Jan 01, 2026Human detection in videos plays an important role in various real-life applications. Most traditional approaches depend on utilizing handcrafted features, which are problem-dependent and optimal for specific tasks. Moreover, they are highly susceptible to dynamical events such as illumination changes, camera jitter, and variations in object sizes. On the other hand, the proposed feature learning approaches are cheaper and easier because highly abstract and discriminative features can be produced automatically without the need of expert knowledge. In this paper, we utilize automatic feature learning methods, which combine optical flow and three different deep models (i.e., supervised convolutional neural network (S-CNN), pretrained CNN feature extractor, and hierarchical extreme learning machine) for human detection in videos captured using a nonstatic camera on an aerial platform with varying altitudes. The models are trained and tested on the publicly available and highly challenging UCF-ARG aerial dataset. The comparison between these models in terms of training, testing accuracy, and learning speed is analyzed. The performance evaluation considers five human actions (digging, waving, throwing, walking, and running). Experimental results demonstrated that the proposed methods are successful for the human detection task. The pretrained CNN produces an average accuracy of 98.09%. S-CNN produces an average accuracy of 95.6% with softmax and 91.7% with Support Vector Machines (SVM). H-ELM has an average accuracy of 95.9%. Using a normal Central Processing Unit (CPU), H-ELM's training time takes 445 seconds. Learning in S-CNN takes 770 seconds with a high-performance Graphical Processing Unit (GPU).
Enhancing Password Security Through a High-Accuracy Scoring Framework Using Random Forests
Nov 13, 2025



Password security plays a crucial role in cybersecurity, yet traditional password strength meters, which rely on static rules like character-type requirements, often fail. Such methods are easily bypassed by common password patterns (e.g., 'P@ssw0rd1!'), giving users a false sense of security. To address this, we implement and evaluate a password strength scoring system by comparing four machine learning models: Random Forest (RF), Support Vector Machine (SVM), a Convolutional Neural Network (CNN), and Logistic Regression with a dataset of over 660,000 real-world passwords. Our primary contribution is a novel hybrid feature engineering approach that captures nuanced vulnerabilities missed by standard metrics. We introduce features like leetspeak-normalized Shannon entropy to assess true randomness, pattern detection for keyboard walks and sequences, and character-level TF-IDF n-grams to identify frequently reused substrings from breached password datasets. our RF model achieved superior performance, achieving 99.12% accuracy on a held-out test set. Crucially, the interpretability of the Random Forest model allows for feature importance analysis, providing a clear pathway to developing security tools that offer specific, actionable feedback to users. This study bridges the gap between predictive accuracy and practical usability, resulting in a high-performance scoring system that not only reduces password-based vulnerabilities but also empowers users to make more informed security decisions.
An explainable Recursive Feature Elimination to detect Advanced Persistent Threats using Random Forest classifier
Nov 12, 2025Intrusion Detection Systems (IDS) play a vital role in modern cybersecurity frameworks by providing a primary defense mechanism against sophisticated threat actors. In this paper, we propose an explainable intrusion detection framework that integrates Recursive Feature Elimination (RFE) with Random Forest (RF) to enhance detection of Advanced Persistent Threats (APTs). By using CICIDS2017 dataset, the approach begins with comprehensive data preprocessing and narrows down the most significant features via RFE. A Random Forest (RF) model was trained on the refined feature set, with SHapley Additive exPlanations (SHAP) used to interpret the contribution of each selected feature. Our experiment demonstrates that the explainable RF-RFE achieved a detection accuracy of 99.9%, reducing false positive and computational cost in comparison to traditional classifiers. The findings underscore the effectiveness of integrating explainable AI and feature selection to develop a robust, transparent, and deployable IDS solution.
Neutralizing the Narrative: AI-Powered Debiasing of Online News Articles
Apr 04, 2025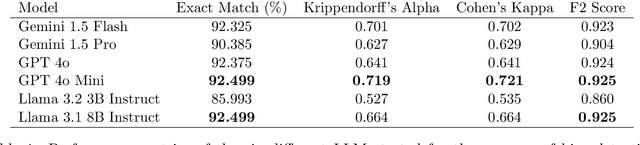
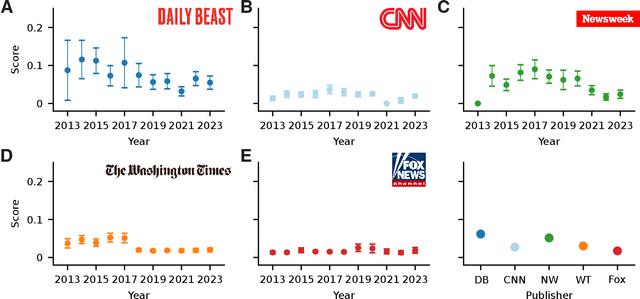
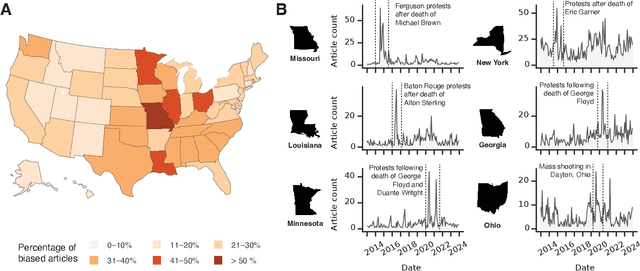

Bias in news reporting significantly impacts public perception, particularly regarding crime, politics, and societal issues. Traditional bias detection methods, predominantly reliant on human moderation, suffer from subjective interpretations and scalability constraints. Here, we introduce an AI-driven framework leveraging advanced large language models (LLMs), specifically GPT-4o, GPT-4o Mini, Gemini Pro, Gemini Flash, Llama 8B, and Llama 3B, to systematically identify and mitigate biases in news articles. To this end, we collect an extensive dataset consisting of over 30,000 crime-related articles from five politically diverse news sources spanning a decade (2013-2023). Our approach employs a two-stage methodology: (1) bias detection, where each LLM scores and justifies biased content at the paragraph level, validated through human evaluation for ground truth establishment, and (2) iterative debiasing using GPT-4o Mini, verified by both automated reassessment and human reviewers. Empirical results indicate GPT-4o Mini's superior accuracy in bias detection and effectiveness in debiasing. Furthermore, our analysis reveals temporal and geographical variations in media bias correlating with socio-political dynamics and real-world events. This study contributes to scalable computational methodologies for bias mitigation, promoting fairness and accountability in news reporting.
Advancing Vehicle Plate Recognition: Multitasking Visual Language Models with VehiclePaliGemma
Dec 14, 2024



License plate recognition (LPR) involves automated systems that utilize cameras and computer vision to read vehicle license plates. Such plates collected through LPR can then be compared against databases to identify stolen vehicles, uninsured drivers, crime suspects, and more. The LPR system plays a significant role in saving time for institutions such as the police force. In the past, LPR relied heavily on Optical Character Recognition (OCR), which has been widely explored to recognize characters in images. Usually, collected plate images suffer from various limitations, including noise, blurring, weather conditions, and close characters, making the recognition complex. Existing LPR methods still require significant improvement, especially for distorted images. To fill this gap, we propose utilizing visual language models (VLMs) such as OpenAI GPT4o, Google Gemini 1.5, Google PaliGemma (Pathways Language and Image model + Gemma model), Meta Llama 3.2, Anthropic Claude 3.5 Sonnet, LLaVA, NVIDIA VILA, and moondream2 to recognize such unclear plates with close characters. This paper evaluates the VLM's capability to address the aforementioned problems. Additionally, we introduce ``VehiclePaliGemma'', a fine-tuned Open-sourced PaliGemma VLM designed to recognize plates under challenging conditions. We compared our proposed VehiclePaliGemma with state-of-the-art methods and other VLMs using a dataset of Malaysian license plates collected under complex conditions. The results indicate that VehiclePaliGemma achieved superior performance with an accuracy of 87.6\%. Moreover, it is able to predict the car's plate at a speed of 7 frames per second using A100-80GB GPU. Finally, we explored the multitasking capability of VehiclePaliGemma model to accurately identify plates containing multiple cars of various models and colors, with plates positioned and oriented in different directions.
Advancing Content Moderation: Evaluating Large Language Models for Detecting Sensitive Content Across Text, Images, and Videos
Nov 26, 2024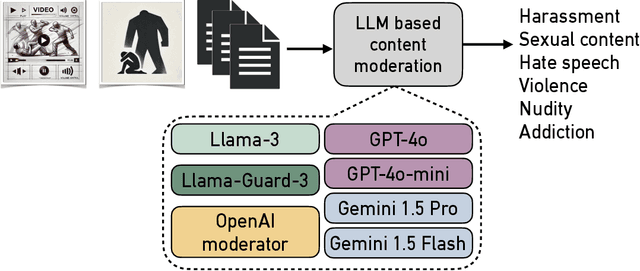
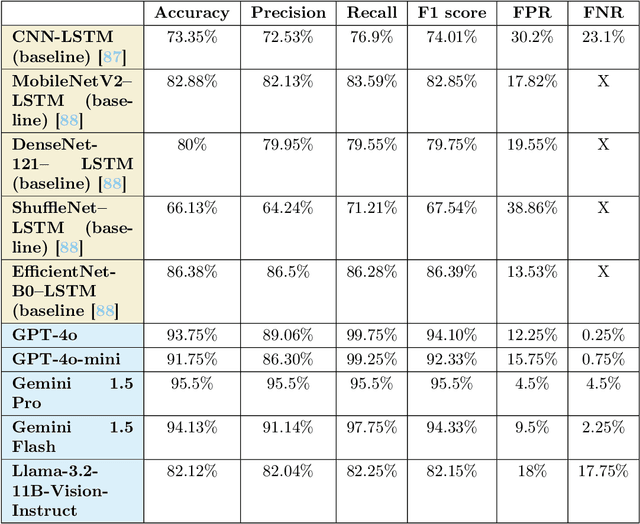
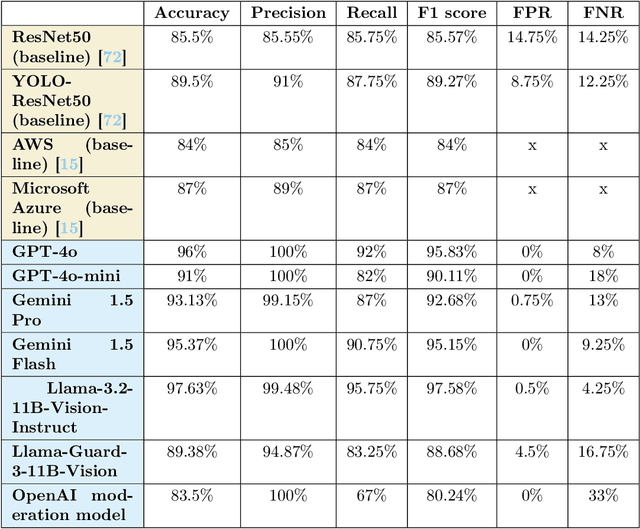
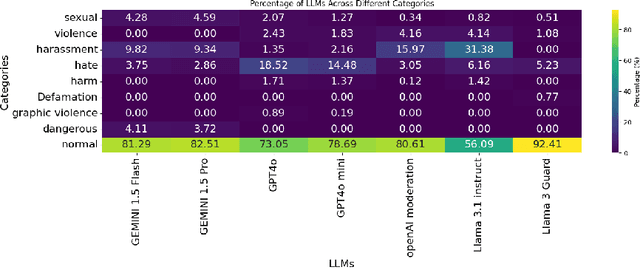
The widespread dissemination of hate speech, harassment, harmful and sexual content, and violence across websites and media platforms presents substantial challenges and provokes widespread concern among different sectors of society. Governments, educators, and parents are often at odds with media platforms about how to regulate, control, and limit the spread of such content. Technologies for detecting and censoring the media contents are a key solution to addressing these challenges. Techniques from natural language processing and computer vision have been used widely to automatically identify and filter out sensitive content such as offensive languages, violence, nudity, and addiction in both text, images, and videos, enabling platforms to enforce content policies at scale. However, existing methods still have limitations in achieving high detection accuracy with fewer false positives and false negatives. Therefore, more sophisticated algorithms for understanding the context of both text and image may open rooms for improvement in content censorship to build a more efficient censorship system. In this paper, we evaluate existing LLM-based content moderation solutions such as OpenAI moderation model and Llama-Guard3 and study their capabilities to detect sensitive contents. Additionally, we explore recent LLMs such as GPT, Gemini, and Llama in identifying inappropriate contents across media outlets. Various textual and visual datasets like X tweets, Amazon reviews, news articles, human photos, cartoons, sketches, and violence videos have been utilized for evaluation and comparison. The results demonstrate that LLMs outperform traditional techniques by achieving higher accuracy and lower false positive and false negative rates. This highlights the potential to integrate LLMs into websites, social media platforms, and video-sharing services for regulatory and content moderation purposes.
Exploring Vision Language Models for Facial Attribute Recognition: Emotion, Race, Gender, and Age
Oct 31, 2024



Technologies for recognizing facial attributes like race, gender, age, and emotion have several applications, such as surveillance, advertising content, sentiment analysis, and the study of demographic trends and social behaviors. Analyzing demographic characteristics based on images and analyzing facial expressions have several challenges due to the complexity of humans' facial attributes. Traditional approaches have employed CNNs and various other deep learning techniques, trained on extensive collections of labeled images. While these methods demonstrated effective performance, there remains potential for further enhancements. In this paper, we propose to utilize vision language models (VLMs) such as generative pre-trained transformer (GPT), GEMINI, large language and vision assistant (LLAVA), PaliGemma, and Microsoft Florence2 to recognize facial attributes such as race, gender, age, and emotion from images with human faces. Various datasets like FairFace, AffectNet, and UTKFace have been utilized to evaluate the solutions. The results show that VLMs are competitive if not superior to traditional techniques. Additionally, we propose "FaceScanPaliGemma"--a fine-tuned PaliGemma model--for race, gender, age, and emotion recognition. The results show an accuracy of 81.1%, 95.8%, 80%, and 59.4% for race, gender, age group, and emotion classification, respectively, outperforming pre-trained version of PaliGemma, other VLMs, and SotA methods. Finally, we propose "FaceScanGPT", which is a GPT-4o model to recognize the above attributes when several individuals are present in the image using a prompt engineered for a person with specific facial and/or physical attributes. The results underscore the superior multitasking capability of FaceScanGPT to detect the individual's attributes like hair cut, clothing color, postures, etc., using only a prompt to drive the detection and recognition tasks.
A Longitudinal Analysis of Racial and Gender Bias in New York Times and Fox News Images and Articles
Oct 29, 2024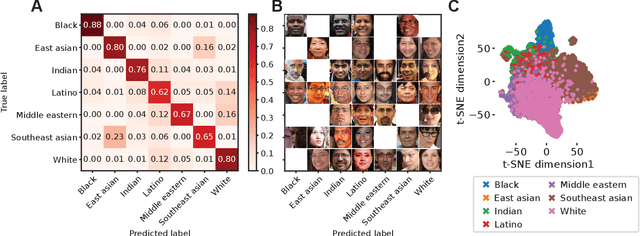
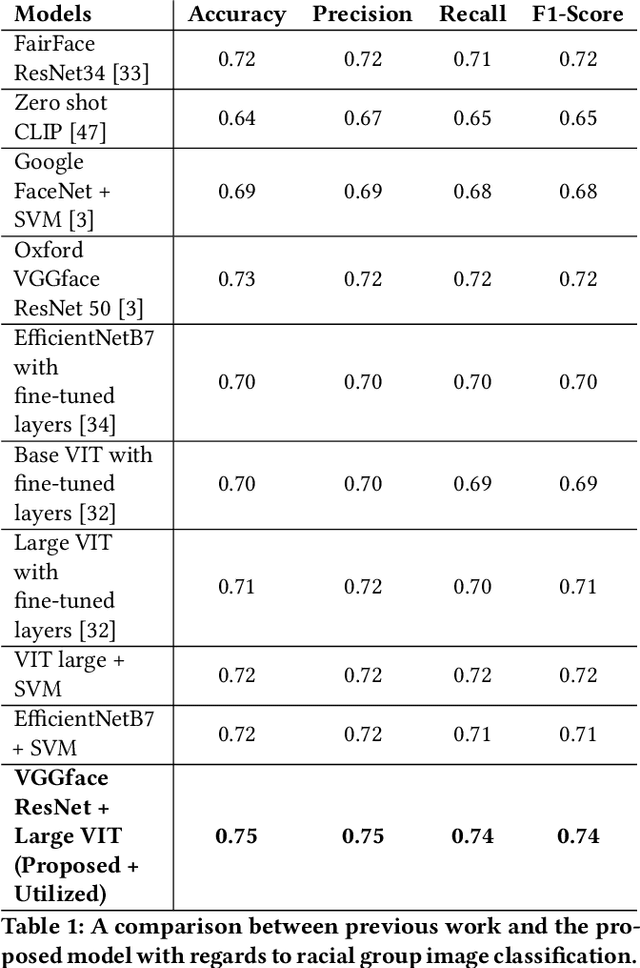
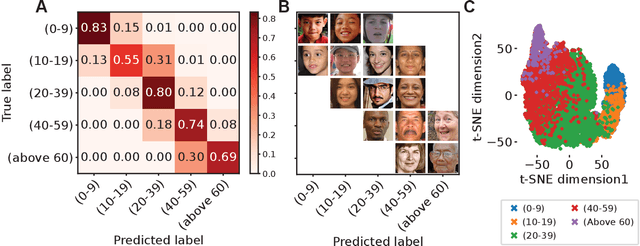
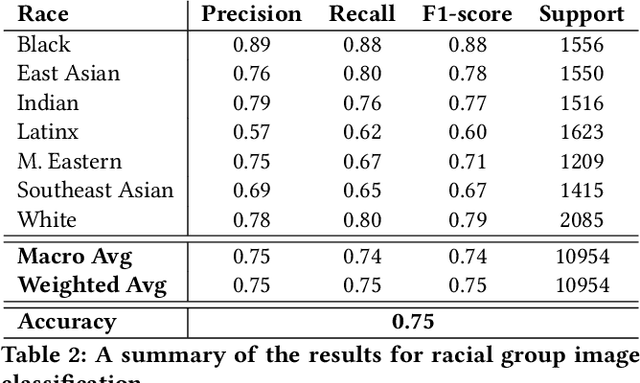
The manner in which different racial and gender groups are portrayed in news coverage plays a large role in shaping public opinion. As such, understanding how such groups are portrayed in news media is of notable societal value, and has thus been a significant endeavour in both the computer and social sciences. Yet, the literature still lacks a longitudinal study examining both the frequency of appearance of different racial and gender groups in online news articles, as well as the context in which such groups are discussed. To fill this gap, we propose two machine learning classifiers to detect the race and age of a given subject. Next, we compile a dataset of 123,337 images and 441,321 online news articles from New York Times (NYT) and Fox News (Fox), and examine representation through two computational approaches. Firstly, we examine the frequency and prominence of appearance of racial and gender groups in images embedded in news articles, revealing that racial and gender minorities are largely under-represented, and when they do appear, they are featured less prominently compared to majority groups. Furthermore, we find that NYT largely features more images of racial minority groups compared to Fox. Secondly, we examine both the frequency and context with which racial minority groups are presented in article text. This reveals the narrow scope in which certain racial groups are covered and the frequency with which different groups are presented as victims and/or perpetrators in a given conflict. Taken together, our analysis contributes to the literature by providing two novel open-source classifiers to detect race and age from images, and shedding light on the racial and gender biases in news articles from venues on opposite ends of the American political spectrum.